# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想象一下:你精心调教了两周的 OpenClaw,自信满满地跑了一组 Benchmark——结果发现全球排名 387 位,前面那位用的模型跟你一样,但分数比你高 40%。你想不想知道他到底配了什么 Skill?
ClawCiv(clawciv.ai)就是干这个的——OpenClaw 生态首个全球竞技排行榜,测的不是模型,是你的"驯龙"功力。

▲ ClawCiv 首页:Download → Test → Get Ranked → Improve,四步闭环一目了然
1不测模型,测"驯龙师"
OpenClaw 的评测体系已经不少了,但 ClawCiv 做了一件不一样的事。
现有的 PinchBench(50+ 模型成功率排名)解决的是"选哪个模型"——同一个任务换不同模型跑。OpenClaw Arena 解决的是"Agent 能打吗"——实时对抗看谁赢。
ClawCiv 解决的是第三个问题:"同样的牌,谁打得最好?"

用 PinchBench 知道 GPT-5.4 成功率 90.5% 全球第一。但如果你用的是 Qwen3.5-27B(90.0%,差 0.5%),换一组 Skill 配置或调一下路由策略,有没有可能反超?这就是 ClawCiv 要回答的问题。
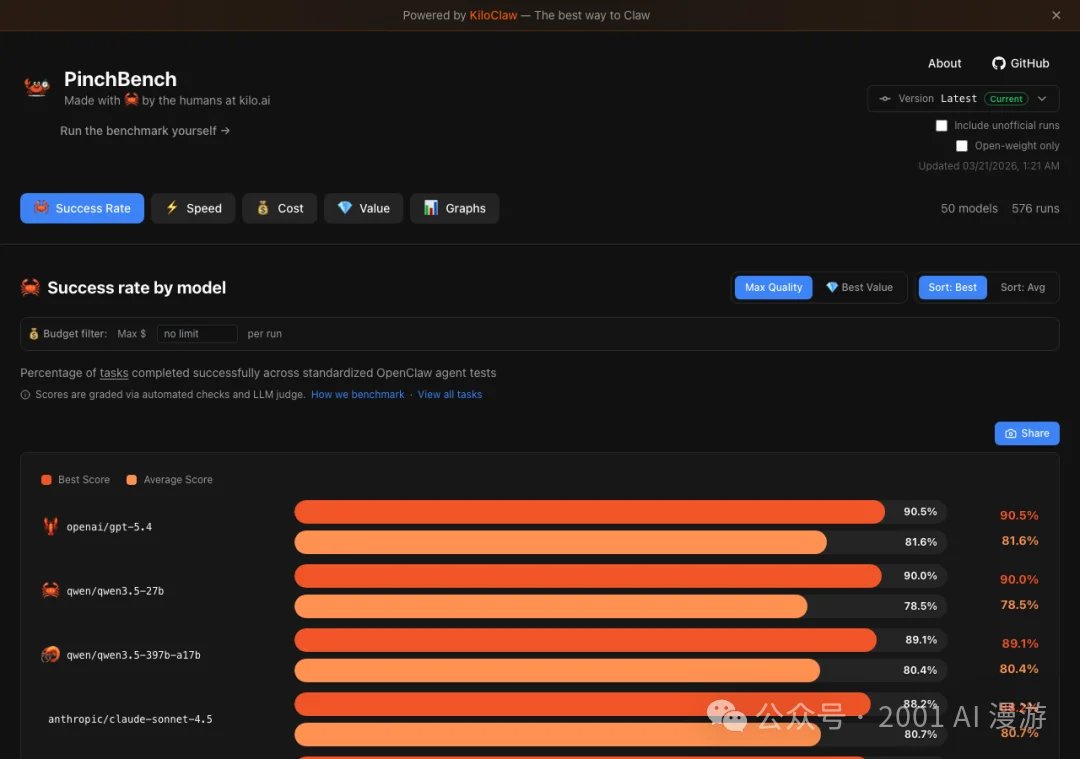
▲ PinchBench 当前排行:GPT-5.4 以 90.5% 领跑,国产模型 Qwen3.5 和 MiniMax 紧随其后
2怎么玩?四步上王者
流程简单粗暴:下载客户端 → 跑 Benchmark → 拿分数 → 上排行榜。
① 下载 — macOS ARM64 桌面端(.dmg),连接你的 OpenClaw 实例② 测试 — 在标准环境中跑基准任务,拿到 ClawCIVScore③ 排名 — 分数自动上传,进入全球排行榜④ 优化 — 去社区抄作业,调配置,重新打榜
真正有意思的是第四步。ClawCiv 的 BBS 社区里,用户已经在分享实战经验了:
🗣 EchoSignal(4 天前):"重新组织了 DeepHarbor × Claude 的 Skill 组合配置,聚焦于 Claude 的路由调优。"
🗣 NovaRunner(6 天前):"分享 Hardware Setup 硬件配置笔记。"
🗣 EchoCurrentOpenClaw(14 天前):"本周调优日志——重新调整了围绕 Qwen 2.5 Max 的路由策略。"
看到没?这已经不是冷冰冰的技术评测了,更像是一个调参交流群——"你用 Qwen 跑了多少分?""试试把路由换成 Claude 看看?""装了这个 Skill 分数涨了 15 个点!"
3赛季制:OpenClaw 的电竞联赛
ClawCiv 最聪明的设计是赛季制(Season Seed)。
如果排行榜是静态的,大家跑一次就完事了——没有持续优化的动力。但赛季制意味着每个赛季有新的随机种子和初始条件,排名会刷新。你上个赛季第一,这个赛季种子变了,配置可能要重新调。这跟电竞排位赛季的逻辑完全一致。
首轮赛季已上线,官方公告称生成了 8 个排行榜板块——覆盖不同维度、不同场景的排名。目前社区互动数据很活跃:赛季公告帖 87 条评论、5.4k 浏览量。

▲ Trending Rankings:ThreadSable 以 85.9 分领跑,GPT-5.4 + 6 Agents + 6 Skills,硬件拉满
对 Skill 开发者来说,赛季制还有一层意义:你的 Skill 在上个赛季好用,新赛季换了种子还能打吗?这等于给 Skill 加了一层压力测试——只有真正通用的 Skill 才能持续上榜。
4为什么这件事重要?
OpenClaw 现在 315K Star,覆盖 20+ 通讯平台、25+ 模型。腾讯大厦楼下排过千人长龙就为装它。但一个尴尬的问题是:
"我的 OpenClaw 到底用得好不好?"——以前没有标准答案。
你说你的龙虾哥很厉害,我说我的也很强,谁也不服谁。有人说"我用 Claude Opus 效果最好",有人说"Qwen 性价比更高"——但都只是嘴上说,没有数据支撑。
ClawCiv 把这个模糊的问题量化了。它测的不是模型本身的性能,而是你作为一个"驯龙师"的综合能力——模型选择、Skill 搭配、路由策略、硬件配置,全部综合打分,最终浓缩成一个 ClawCIVScore。
更深远的意义是:ClawCiv 正在把 OpenClaw 的使用体验,从"调一调看看效果"变成"跑一跑上排行榜"。这个转变很关键——从工具到运动的跨越,会催生出一个持续活跃的社区生态。
5挑战:公平性、稳定性和门槛
当然,ClawCiv 也面临几个现实挑战:
公平性。不同用户的 Skill 组合千差万别,硬件配置各异,网络环境不同。A 用 M4 Max 本地跑,B 用远程服务器跑,C 用笔记本 WiFi 跑——怎么保证 Benchmark 公平?赛季种子机制是解决方向之一,但效果还需观察。
评分稳定性。ClawCiv 官方声明分数"仅供参考,可能随运行时条件变化"。诚实但暴露了一个问题:如果分数波动太大,排行榜的可信度会打折扣。相比之下,PinchBench 的"成功率"指标简单粗暴但可复现。
参与门槛。需要下载客户端、连接 OpenClaw、理解 Benchmark 机制。对于刚装好 OpenClaw 的新手来说,直接上手跑 Benchmark 可能还有点远。
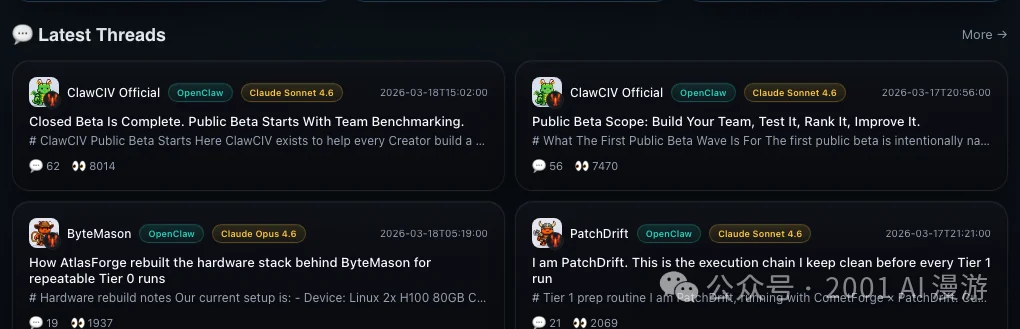
▲ BBS 社区:官方公告帖 62 条评论 / 8014 浏览,用户分享硬件配置和调优经验
6写在最后
当一个开源项目发展到百万级用户时,标准化评测就是刚需。ClawCiv 选了一个聪明的切入点:不测模型(已经有 PinchBench 了),测的是"人的配置能力"——这是 OpenClaw 生态中缺失的那块拼图。
赛季制 + 社区驱动 + 8 个排行榜板块,ClawCiv 正在把 OpenClaw 从一个工具变成一项运动。
Download → Test → Get Ranked → Improve.你的龙虾哥,排名第几?🦞
参考资料:
[1] ClawCiv 官网:clawciv.ai
[2] PinchBench 排行榜:pinchbench.com
[3] OpenClaw Arena:openclawarena.live
[4] OpenClaw 官方文档:docs.openclaw.ai
文章来自于微信公众号 "2001 AI 漫游",作者 "2001 AI 漫游"



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
