# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让一个模型概括“这是一段什么视频”,并不难。
但如果追问一步——一闪而过的车牌号后四位是多少?这个动作一共发生了几次、分别在第几秒?不断滚动的字幕写了什么?
——大多数视频理解模型就开始交白卷了。
这类问题有一个共同特征:答案可以被明确验证。研究团队把它称为视频理解中的「证据题」。
近日,复旦大学、上海创智学院邱锡鹏教授领衔的OpenMOSS团队联合初创公司模思智能(MOSI)开源MOSS-VL——一个11B参数的多模态视觉理解模型,支持图像、视频、文档等多种输入模态。在视频理解方面,MOSS-VL不满足于生成一段概括,而是开始把视频里可被验证的细节、时间、过程和空间关系,准确地回答出来。

如果只要回答“这是一段买瓜的视频”“这是一段做饭的视频”,很多模型看起来都不错。但视频理解真正拉开差距的地方,从来不在概括能力,而在更深一层的追问:
回答这些问题,模型需要的不是“看一眼就概括”的能力,而是从连续画面中精确提取证据的能力。MOSS-VL正是围绕这一层能力构建的。
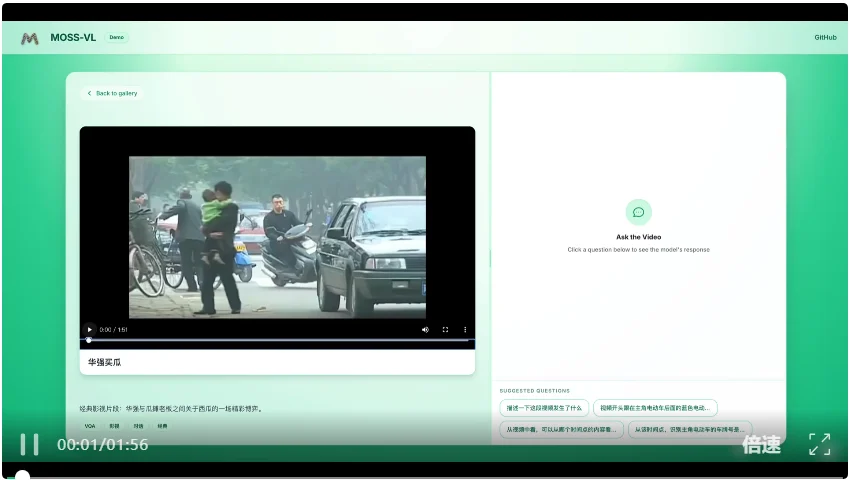
在一段广为流传的视频中,一辆蓝色电动车仅在开头短暂经过。当被问到“跟在主角身后的蓝色电动车,车牌后四位是多少”时,MOSS-VL准确回答4425,对照模型则给出了完全不对应的结果。
这类任务的核心难度在于:目标出现时间极短,画面本身在运动,模型需要从连续帧中锁定一个局部区域并稳定读取。能把这种一闪而过的镜头内容回答出来,证明了模型能够精确捕捉瞬时细节信息。
柜台上摆着三个杯子。问题是:根据柜员的说法,三个杯子分别对应什么尺寸?
MOSS-VL的回答是中杯、大杯和特大杯。Qwen3-VL则答成了“小杯、中杯和大杯”——这恰恰是按照杯子外观大小直觉猜测的结果。
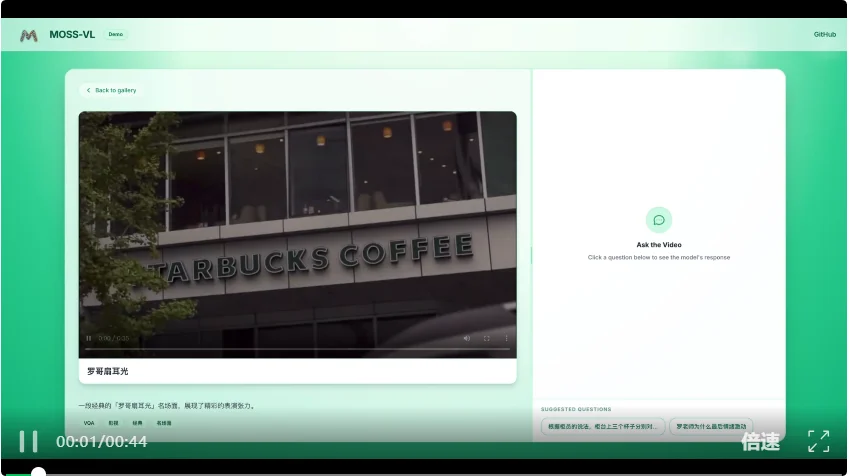
差异的关键在于:MOSS-VL不是凭物体外观猜答案,而是结合视频中说话内容的语义信息来完成匹配。视觉和语义同时参与推理,这才更接近真实场景中的多模态问答。
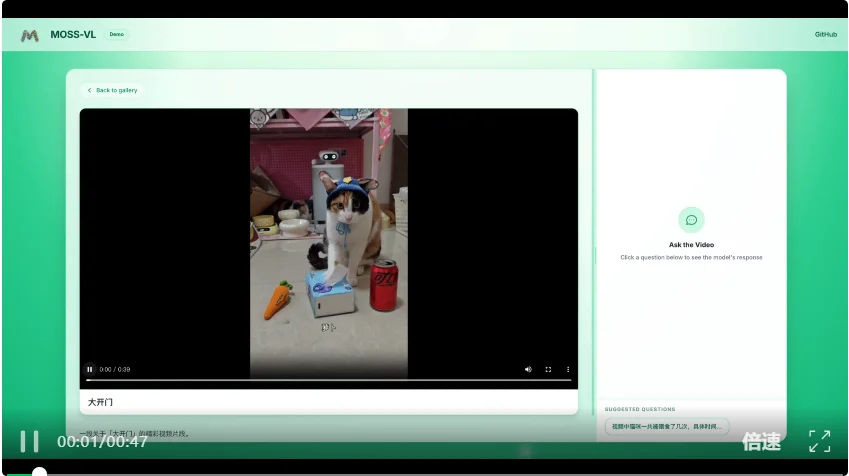
一段喂猫视频里,猫被喂食了几次?分别在什么时间?
MOSS-VL的回答是5次,并给出了00:03、00:12、00:18、00:27、00:37这五个时间点。
这类任务的核心不是物体识别,而是模型能否把重复发生的动作逐段切分,并将每一次精确定位到时间线上——这是只有在视频理解中才会出现的时序推理能力。
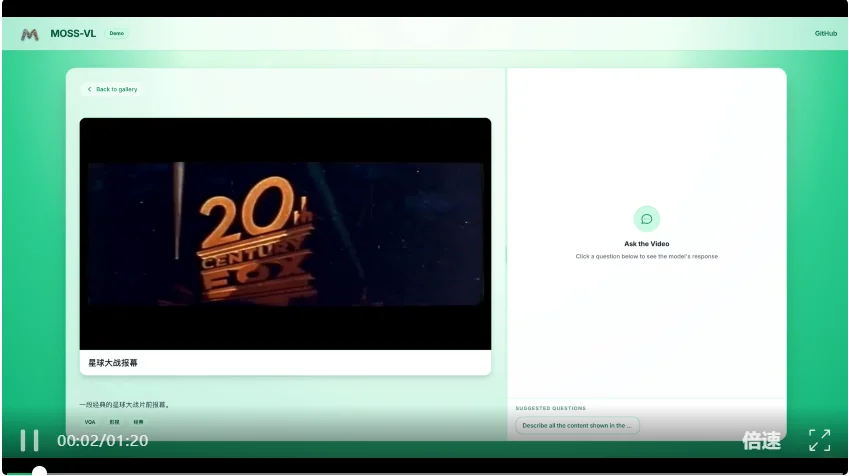
《星球大战》经典的开场爬行字幕,英文文本从屏幕底部持续向上滚动。这不是OCR一张静态图片,而是面对不断变化的视觉文本,要求模型持续跟踪并完整输出。
MOSS-VL给出的不是零碎的关键词片段,而是一整段较为完整的全文转写。这项能力一旦稳定,在字幕视频、课件录屏、演示文稿录制、文档视频化等场景中,将直接产生应用价值。
面对“描述这道菜的制作步骤,并定位到对应时间段”这个问题,MOSS-VL不是笼统地回答“这是一段做卤肉饭的视频”,而是将整个过程拆解为多个明确阶段——展示成品与食材、切五花肉和配料、下锅翻炒加调料、加水放卤蛋收尾——每个阶段都对应到视频中的具体时间段。
这种步骤级的输出体现的是模型对过程、顺序和阶段转换的理解。在教程理解、工业流程记录、维修演示、机器人前置观察等场景中,最常见的问题正是:做到第几步了?前后顺序是什么?

从00:00开始到00:06结束,我们可以看到特写镜头首先展示了一锅正在炖煮的卤肉,锅中包含肉块、卤蛋和葱段,表面撒有香料,随后镜头聚焦于锅中正在冒泡的卤肉,热气腾腾,色泽诱人。画面中央出现白色文字“台式卤肉饭”,紧接着镜头切换,用木勺将卤肉舀到一碗白米饭上,米饭旁配有切开的卤蛋和绿色蔬菜。画面下方出现白色字幕:“软糯入味的卤肉饭没有人不爱吧~”。随后,一个木勺舀起一勺卤肉和米饭,展示其丰富的配料和诱人的色泽,画面下方再次出现白色字幕:“软糯入味的卤肉饭没有人不爱吧~”。整个视频以成品展示开场,呈现了这道台式卤肉饭的诱人外观和制作完成后的摆盘效果。
在00:06至00:11期间,一只手使用菜刀在木质砧板上将五花肉切成小块,画面下方显示白色字幕“五花肉切小块”;随后,同一块砧板上被切碎的红葱头,画面下方出现白色字幕“红葱头切小丁”;接着,切碎的干香菇也被展示在砧板上,画面下方显示白色字幕“泡发好的干香菇切丁”。随后镜头切换,展示出四个装有食材的碗,分别盛放着切好的五花肉、干香菇、红葱头和蒜末,所有食材整齐摆放,准备用于后续的烹饪步骤。整个过程围绕食材的初步处理展开,清晰呈现了五花肉、红葱头和干香菇的切割方式与状态。
在00:11至00:24期间,视频展示了在平底锅中,切碎的红葱头被倒入热油中,伴随着“下锅小火慢炸”的白色字幕,厨师用木铲不断翻炒,直至红葱头呈现出金黄色,随后用漏勺将其捞出,留下热油在锅中。接着,切好的五花肉被放入锅中,画面显示“五花肉蒜末姜片”的白色字幕,厨师继续用木铲翻炒,使五花肉逐渐煸炒出油脂,画面下方出现“煸炒出油脂”的白色字幕。随后,厨师将煸炒出的多余油脂倒入另一个碗中,画面下方显示“多余的油盛出来油多了会腻”的白色字幕。紧接着,厨师向锅中加入一勺料酒、两勺生抽、一勺老抽、八角、桂皮、香叶以及几颗冰糖,画面左侧出现白色文字列表,详细列出了所用的调味料,包括“1勺料酒2勺生抽1勺老抽八角桂皮香叶几颗冰糖”,厨师继续翻炒,使五花肉均匀地裹上酱汁,画面下方出现“翻炒均匀”的白色字幕。整个过程清晰展示了卤肉的初步烹饪步骤,包括炸红葱头、煸炒五花肉以及加入调味料进行翻炒。
00:24至00:31,画面显示切好的干香菇丁和葱头丁被加入锅中,与五花肉一起翻炒,画面下方出现白色字幕“下锅干香菇丁和葱头丁”。随后,厨师向锅中倒入适量的水,画面下方出现白色字幕“加入没过食材”,接着将三个卤蛋放入锅中,画面下方出现白色字幕“再几个鸡蛋小火煮一个小时”。最后,厨师盖上锅盖,画面下方出现白色字幕“开盖后再煮10分钟收浓汤汁”。整个过程展示了卤肉的收尾阶段,包括加入干香菇和葱头丁、加水、放入卤蛋并盖上锅盖进行长时间炖煮。
从00:31开始到00:37结束,我们可以看到特写镜头展示了卤肉在锅中炖煮的过程,汤汁正在慢慢收浓,随后画面切换至卤肉被盛入一碗白米饭中,旁边摆放着切开的卤蛋和绿色蔬菜,厨师使用木勺将卤肉与米饭充分搅拌,画面下方出现白色字幕:“酱汁浓郁拌着米饭吃真的超级香~”。紧接着,一个木勺舀起一勺拌好的卤肉饭,画面下方再次出现白色字幕:“卤肉软糯入味肥而不腻~太好吃啦”。视频以这道完成的台式卤肉饭作为结尾,展示了其最终的呈现效果和诱人的口感。
在镜头运动方向判断任务中,MOSS-VL准确识别出镜头正在向前推进(forward),对照模型则判断为backward。在空间关系推理任务中,面对“站在床边面朝桌子,马桶在哪个方位”的提问,MOSS-VL同样给出了正确答案(front-right),对照模型错选为back-left。
这两项任务考验的不是“画面里有什么物体”,而是模型能否理解运动方向、空间结构和物体间的相对位置关系——这些恰恰是迈向具身智能和真实环境理解的关键基础能力。

问题:In which direction is the video panning?
选项:A.up B.down C.backward D.forward
Qwen3-VL:C.backward
MOSS-VL:D.forward(正确)
除了细节、时间和过程,MOSS-VL还有一类值得拿出来讲的能力:空间关系推理。
在VSI-Bench这张图里,题目问的是:
如果我站在床边并面朝桌子,马桶在我的前左、前右、后左还是后右?
GroundTruth是front-right。MOSS-VL预测正确,对照模型则选成了back-left。
这类题的关键在于,它不是简单识别“床、桌子、马桶”三个物体,而是要求模型把它们放进同一个空间关系里,再从人的相对朝向出发做判断。原稿也明确指出,这已经更接近具身智能、空间推理和真实环境理解的问题。
换句话说,它回答的不再只是“画面里有什么”,而是“这些东西在一个可推理的空间里是什么关系”。

问题:If I am standing by the bed and facing the table, is the toilet to my front-left, front-left, front-right, back-left, or back-right? The directions refer to the quadrants of a Cartesian plane(if I am standing at the origin and facing along the positive y-axis).
选项:A.front-leftB.front-rightC.back-leftD.back-right
Qwen3-VL:C.back-left
MOSS-VL:B.front-right
在架构层面,MOSS-VL做了三个面向视频理解的关键设计:
Cross-Attention按需读取视觉信息。不是把所有视觉token全部压入语言模型,而是通过交叉注意力机制让模型按需提取,使长视频处理不再被视觉token数量拖垮。
绝对时间戳编码。为视频帧引入真实时间信息,让模型天然具备“这个动作发生在第几秒”的定位锚点,时间定位能力从源头获得支撑。
XRoPE统一位置编码。用一套编码方案同时建模时间维度、空间维度和文本查询维度,实现跨模态的精细对齐。
这三项设计指向同一个核心目标:让模型在面对长视频时,能稳定抓取时间细节、空间关系和局部证据,而非仅在少量采样帧上做粗粒度概括。
在主流视频理解benchmark上,MOSS-VL在11B参数级别展现出领先表现。

案例负责让人看懂能力边界,数据负责让人相信能力水位。具体评测细节可前往项目主页查阅。
MOSS-VL采用Apache2.0开源许可,欢迎学术研究和商业应用。
开源链接
MOSS-VL-Base-0408HuggingFace:
https://huggingface.co/OpenMOSS-Team/MOSS-VL-Base-0408
ModelScope:
https://www.modelscope.cn/models/openmoss/MOSS-VL-Base-0408
MOSS-VL-Instruct-0408HuggingFace:
https://huggingface.co/fnlp-vision/MOSS-VL-Instruct-0408
ModelScope:
https://www.modelscope.cn/models/openmoss/MOSS-VL-Instruct-0408
文章来自于"量子位",作者 "MOSS-VL团队"。



