# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026年4月底,AI界被一篇名为《不可压缩知识探针》(Incompressible Knowledge Probes,简称 IKP)的论文震动了。

论文地址:https://www.alphaxiv.org/abs/2604.24827
Pine AI的首席科学家Bojie Li发表了一项研究,声称通过一种全新的「黑盒探测法」,推算出了那些闭源模型的真实体量。
这个数据瞬间引爆了社交媒体。
要知道,如果GPT-5.5真的达到了10T规模,那意味着它比传闻中的GPT-4(约1.8T)大了5倍有余。
一时间,这个参数瞬间传遍全网。
然而,仅仅几天后,反转就来了。
逻辑的漏洞:从10T到1.5T的缩水内幕
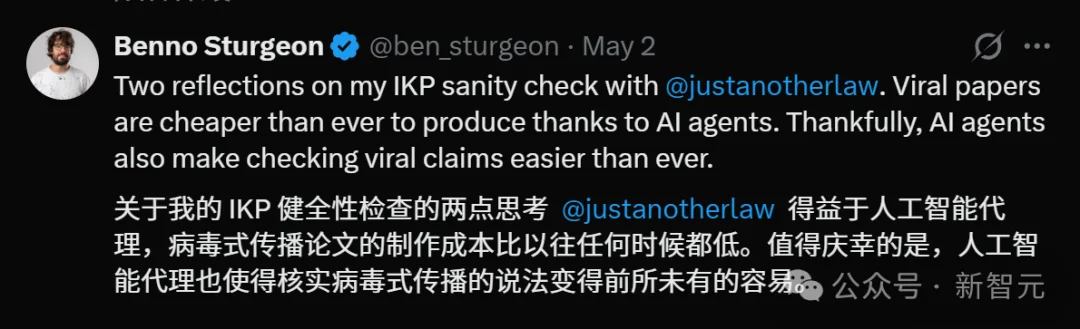
最近,来自UC伯克利CHAI实验室的Lawrence Chan和UK AISI的研究员Ben Sturgeon对这篇论文进行了深挖。

他们发现,这篇声称「逆推大模型规模」的爆火论文,竟然存在严重的逻辑与代码偏差。
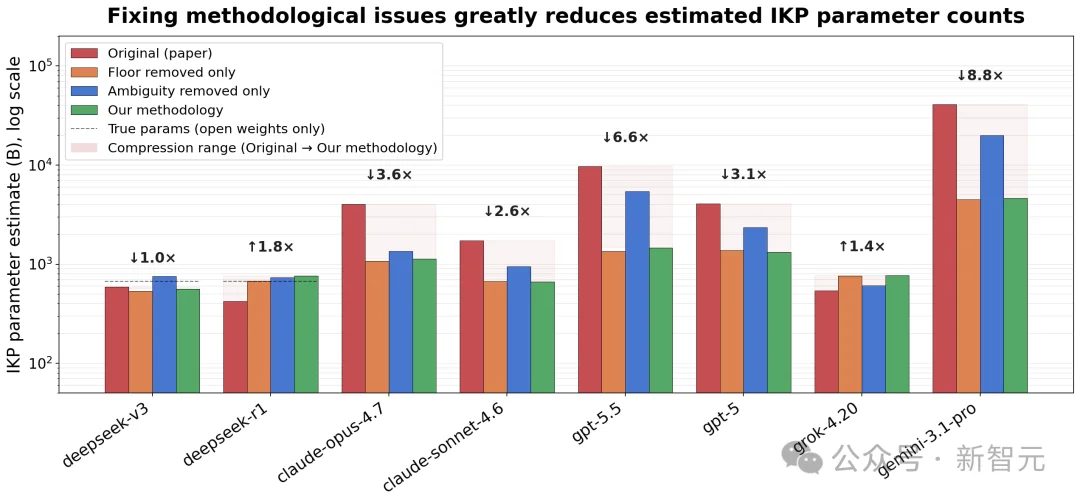
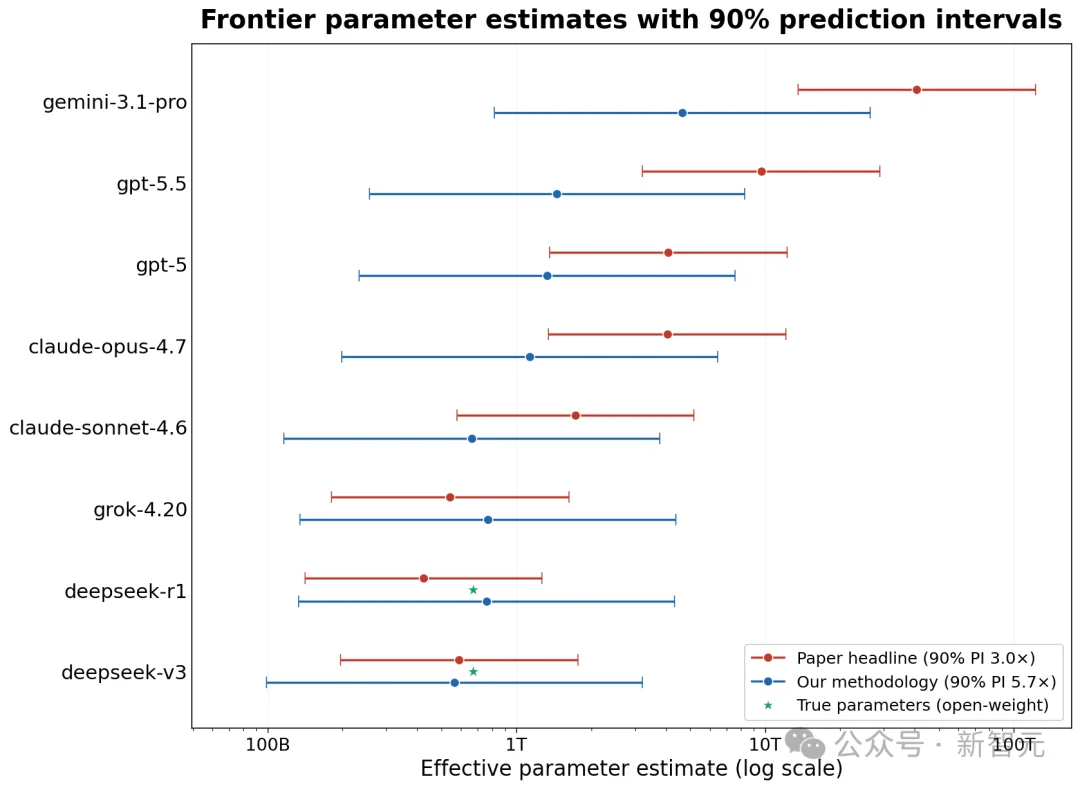
修复这些问题后,GPT-5.5的参数约为1.5T(90% 置信区间:256B-8.3T)。
被修饰的拟合曲线
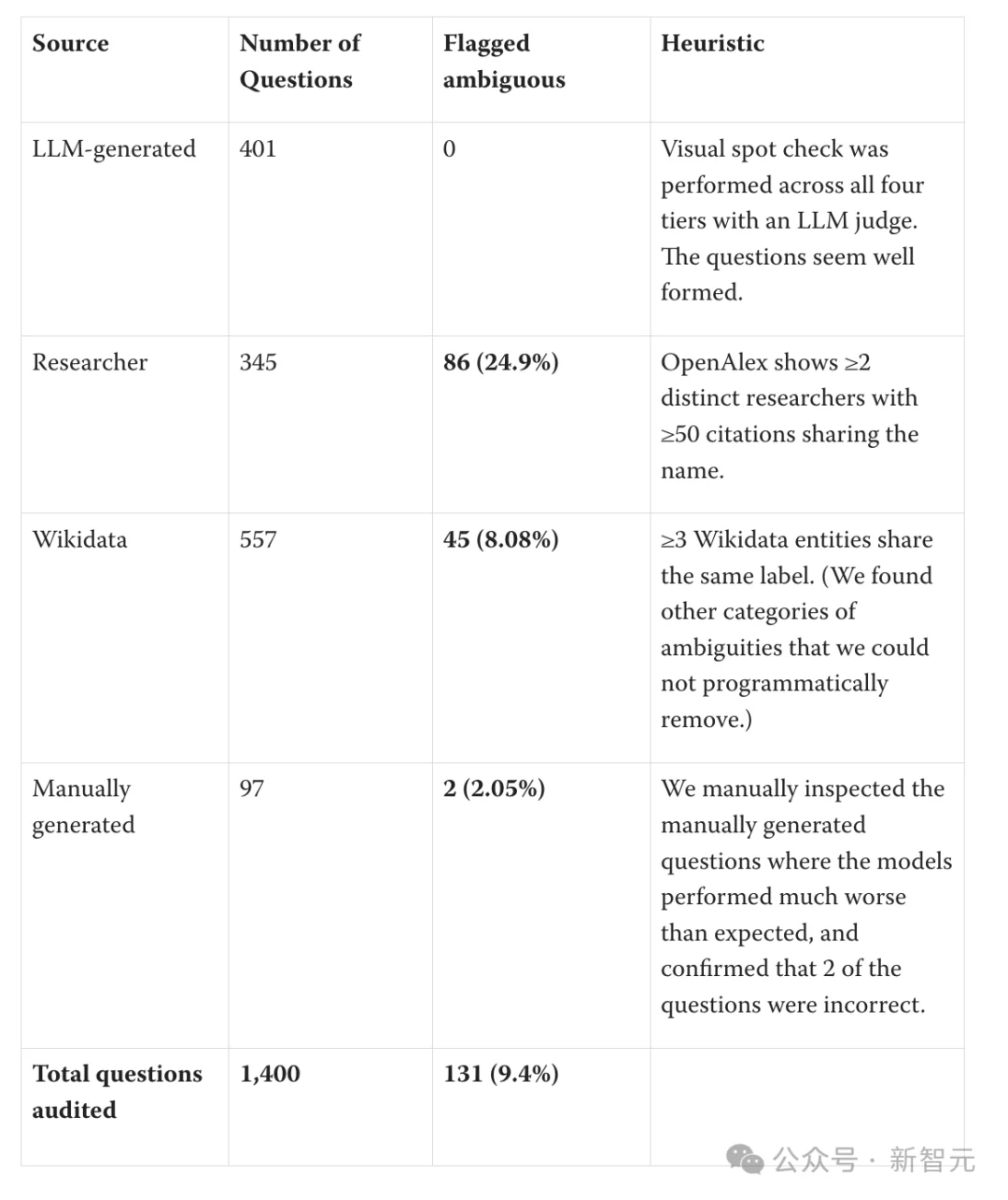
在原始论文中,作者声称没有对模型的得分进行「保底处理」(flooring)。但在复现代码时,研究者发现作者在计算小模型得分时,偷偷地将负分归零了。
科普:当模型遇到不知道的冷知识时,如果乱猜(幻觉),得分会是负数。
如果把这个「归零」操作去掉,小模型的得分会大幅下降。这意味着原本陡峭的「得分-参数」拟合曲线会变得平缓。修正后,估算的GPT-5.5规模直接从9.7T暴跌至1.5T。

「人工智障」出题:25%的题目本身就有错
研究者发现,这套用来测试模型的「冷知识题库」质量同样堪忧。
最戏剧性的是,原作者Bojie Li后来坦言:这篇研究是他在AI智能体的辅助下,仅用4天时间完成的早期探索。
这种「AI写论文研究AI」的模式,被Lawrence Chan戏称为「充满槽点的Vibe-coding」。

核心理论依然坚挺
知识「不可压缩」
用严谨的话说,论文的核心思想——IKP 得分与对数参数数量之间的线性关系——仍然成立,但参数数量的估计却不成立。

解决这两个问题后,基于IKP的前沿模型估计的参数数量通常会下降,置信区间会扩大:
GPT 5.5:9.7T -> 1.5T
Claude Opus 4.7:4.0T -> 1.1T
DeepSeek R1(实际大小671B):424 B -> 760 B
难得的是,论文中的三种说法,承受住了各种测试,被证明依然是正确的。
比如,IKP分数和模型的参数呈对数线性关系。

总之,论文提出的核心模型依然得到了学界的认可:不可压缩知识探针(IKP)。
这个理论认为,大模型的能力可以分为两部分。
你可以把模型想象成一个硬盘,存一个事实就需要占几个比特位。
因此,测试模型到底知道多少「不可压缩」的冷知识,确实是目前探测闭源模型参数最科学的「测力计」。
谁才是真正的「知识之王」?
而且,尽管参数规模下调了,但各家模型的「有效容量」排名依然极具参考价值。
梯队格局
「思考模式」的玄学
测试显示,开启「思维链」(Thinking Mode)并不能显著增加模型的知识量。这再次印证了:思考能提高逻辑,但不能凭空变出你没读过的书。
最后,Lawrence Chan吐槽说:这项工作果然是AI智能体在四天内完成的,因为网站和代码库到处都体现着vibe coding的粗糙风格。
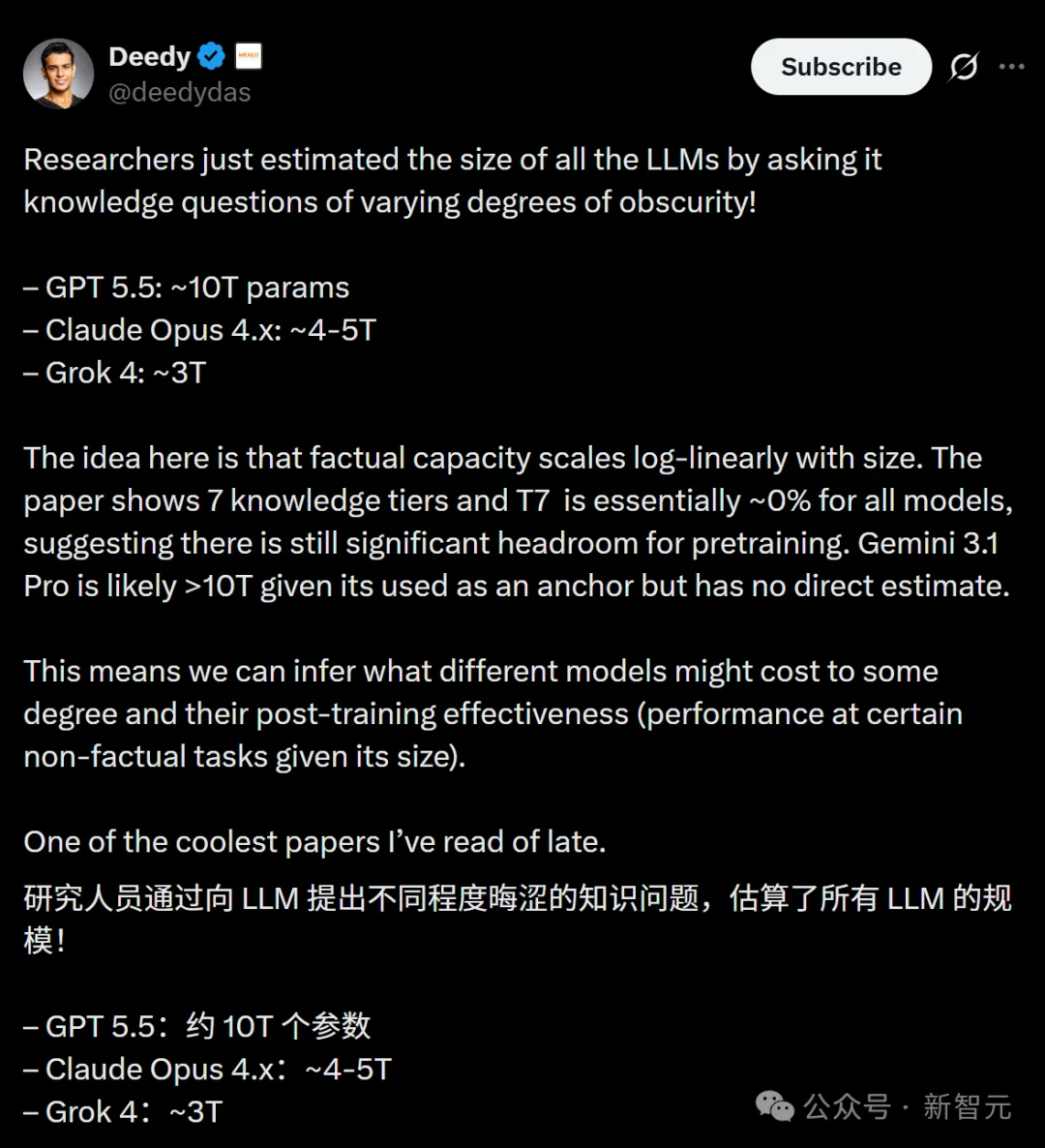
GPT-5.5参数有9.7T?
4月30日,Pine AI的首席科学家李博杰的这篇论文引发了热议。

核心观点是:事实性容量与模型规模呈对数线性关系。
论文展示了 7 个知识层级,其中T7对所有模型来说几乎都是0%左右,这表明预训练仍有巨大的提升空间。
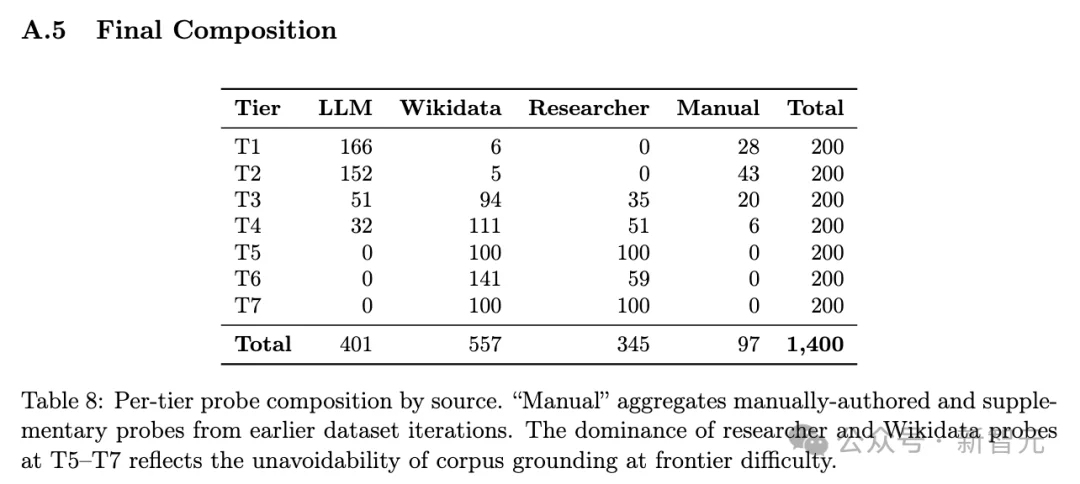
Gemini 3.1 Pro很可能超过 10T,因为它被用作锚点,但论文中没有对其直接估算。
这意味着,我们可以在一定程度上推断不同模型的训练成本,以及它们的后训练效果——即在给定规模下,在某些非事实性任务上的表现。
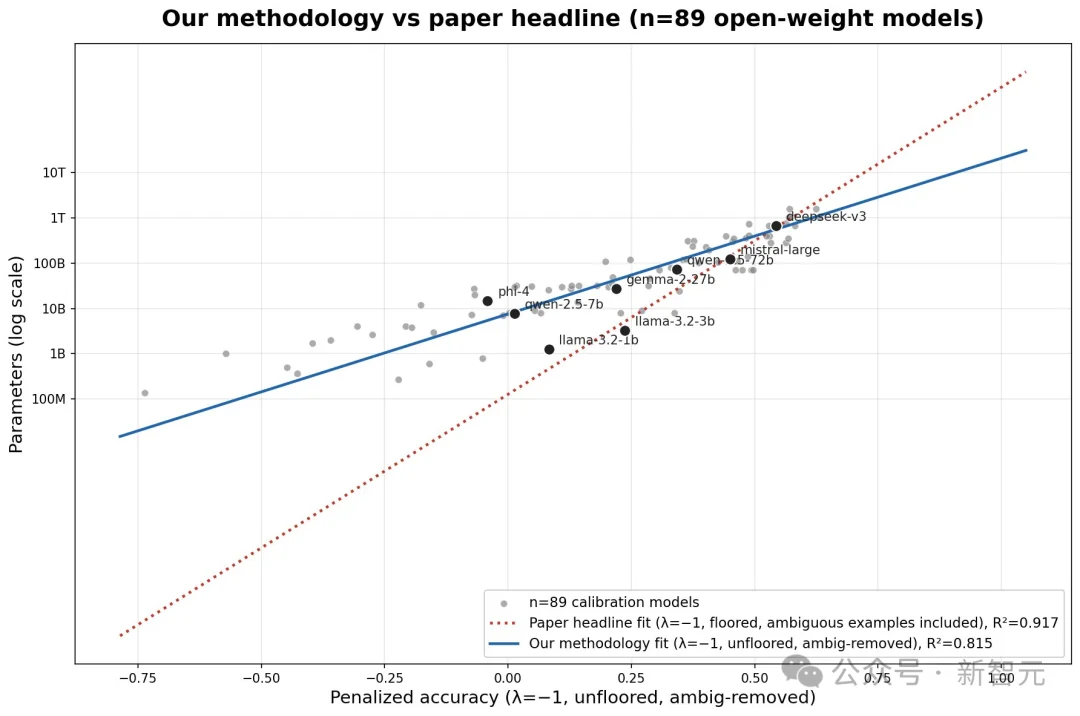
在原作中,李博杰构建了一个包含1400个事实性问题的数据集,并将准确率与参数数量进行拟合。
通过反转拟合,从闭源模型的数据集得分,研究人员推断出其参数数量。
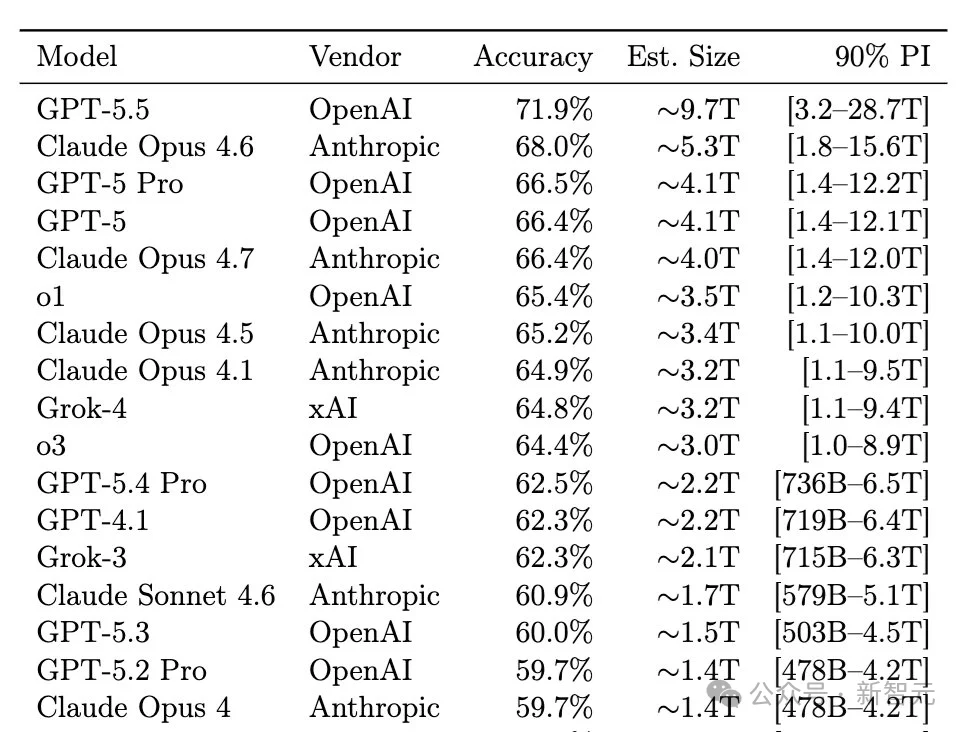
特别要注意最后一行的90%预测区间「Predicition interval, PI」非常大。
此前,就有网友注意到这些「规模只是推测,不应当作事实」。
现在许多人,想知道估算对方法论有多敏感——

李博杰直言,「同一个评估任务,结果横跨60倍区间 → 任何单一的点估计都不诚实。」
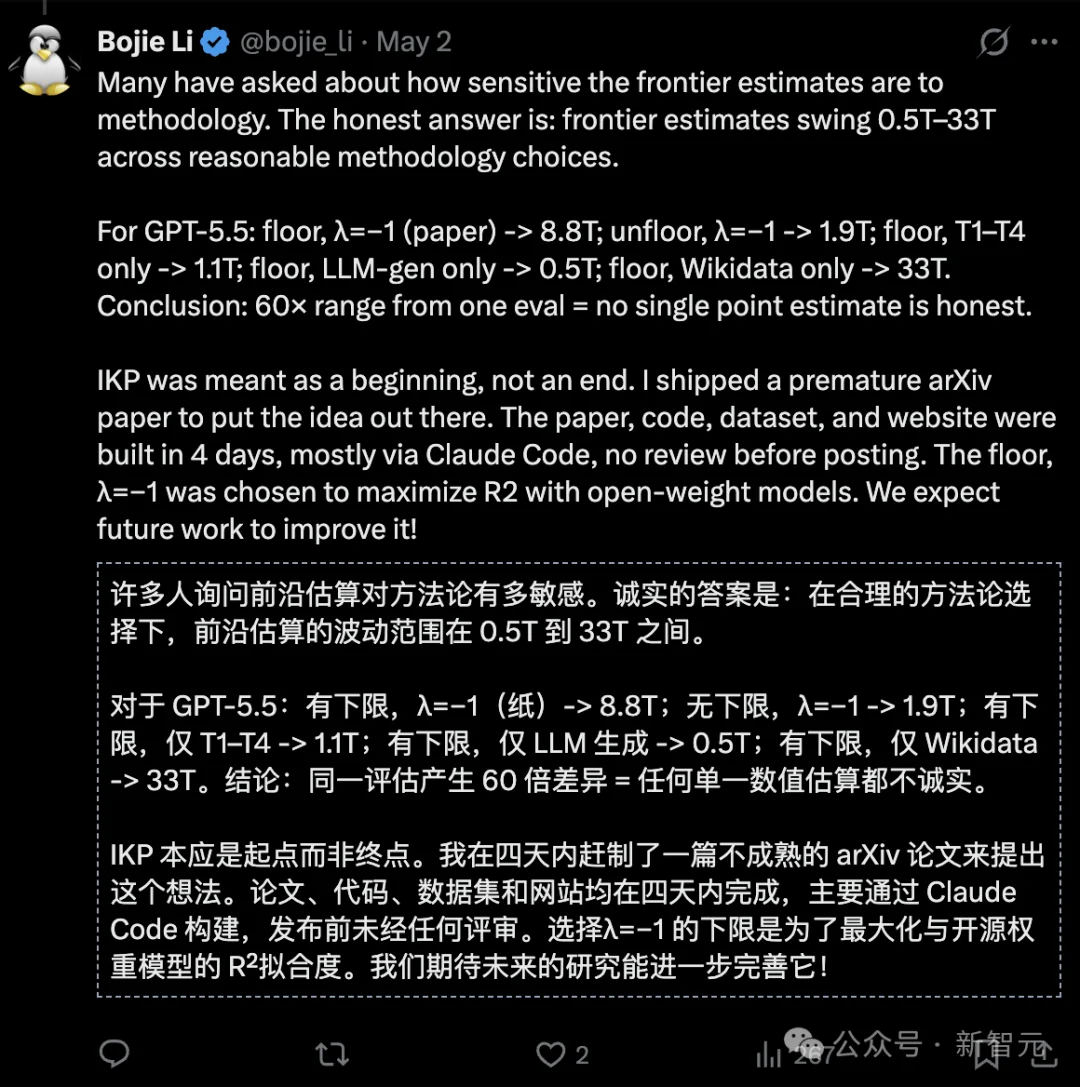
不过,IKP本是一个起点,而非终点。
作者坦诚自己匆忙上传了一篇未成熟的arXiv论文,只是为了把这个想法放出来。
论文、代码、数据集和网站都是在 4 天内完成的,主要借助 Claude Code,发布前未经同行审阅。采用下限处理和 λ=−1,是为了在开放权重模型上最大化R²。
我们期待未来的工作能将它做得更好!
Scaling Law失效了吗?
这次「参数神话」的破灭,给行业敲响了警钟:盲目崇拜大数字的时代正在过去。
GPT-5.5从10T降到1.5T,并不意味着它变弱了,而是意味着OpenAI可能在数据质量和参数效率上做了更惊人的优化。
正如Lawrence Chan在总结中所说:「GPT-5.5到底有多少参数?我们依然不确定。但这种通过探测知识容量来反推规模的方法,为我们揭开黑盒模型的面纱提供了一条新路径。」
在通往AGI的路上,我们需要的或许不再是更大的硬盘,而是更聪明的索引方式。
参考资料:
https://x.com/deedydas/status/2049523583517634862
https://x.com/justanotherlaw/status/2050399317782155726
文章来自于微信公众号 "新智元",作者 "新智元"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】paperai是一个可以快速通过关键词搜索到真实文献并将其应用到论文写作当用的功能。
项目地址:https://github.com/14790897/paper-ai
在线使用:www.paperai.life
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
