# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
边听边说
OpenAI 前 CTO Mira Murati 和前应用研究负责人翁荔(Lilian Weng)创立的 Thinking Machines Lab,也就是 TML,刚刚发布了一个叫「Interaction Models」的研究
这东西的核心能力,是让 AI 能一边听你说话、一边看周围环境、一边回应你。TML 种子轮融资 20 亿美元,估值 120 亿,这是他们创立一年多来第一次公布核心技术方向,下面这个是发布视频

看完 TML 的发布,我想到了两个东西:
今天的故事由此展开,聚焦于 TML-Interaction 和 MiniCPM-o 这俩系列的技术技术、思路的异同,大家是怎么做的:
→ TML 发布 TML-Interaction-Small,276B 参数,12B 激活,200ms 微回合设计
→ 面壁 2 月开源 MiniCPM-o 4.5,9B 参数,1.0s 时间片段,可在 12GB RAM 设备上运行
→ 两家核心洞察一致:交互瓶颈在范式层面,传统的 VAD 应该被模型自身替代
→ 技术路径有分歧:时间粒度、编码器策略、模型架构各走各的
Thinking Machines Lab 这次的模型叫 TML-Interaction-Small,276B 参数的混合专家架构(参数很多但每次只激活其中 12B),搭配一个异步运行的「背景模型」使用。
注意,这里是两套模型:交互模型负责实时对话,始终在线。背景模型负责工具调用、网页搜索这类需要时间的重活,做完把结果回传给交互模型
翁荔在 Demo 视频里出镜,也是她的首次产品演示。在视频里,她要求模型在她讲故事时,每听到一个动物名字就计数一次。她中间喝水、停顿思考,模型都没有打断。最后给出了正确答案:鹿一次、绵羊一次、郊狼一次、卡皮巴拉一次

TML Demo:Introducing Interaction Models
Benchmark 方面,TML 用了 FD-bench,一个专门测交互质量的基准。轮次切换延迟 0.40 秒,GPT-realtime-2.0 是 1.18 秒,Gemini-3.1-flash-live 是 0.57 秒。交互质量评分 77.8,GPT 两个版本分别 46.8 和 47.8
TML 还自己造了两个 benchmark:TimeSpeak 和 CueSpeak
TimeSpeak 测模型能不能在指定时间主动开口,比如「每 4 秒提醒我呼吸一次」;CueSpeak 测模型能不能在正确时刻回应,比如「听到外语就纠正发音」
对于这俩 bench,现有模型几乎为零,GPT-realtime-2.0 分别得了 4.3 和 2.9,TML 得了 64.7 和 81.7
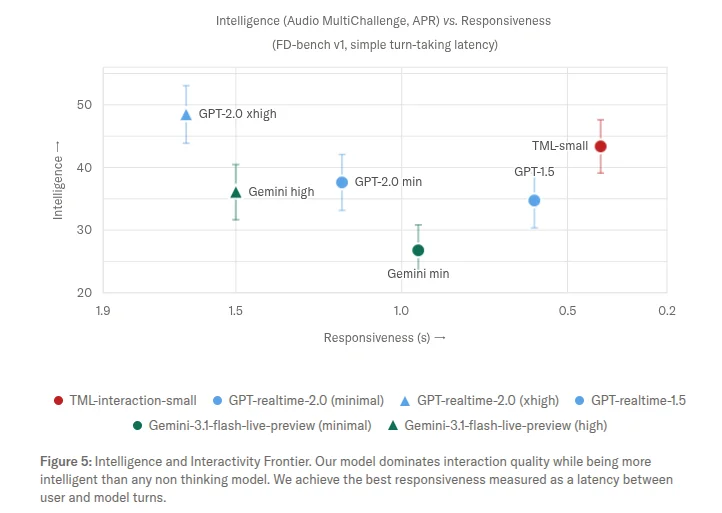
TML 在智能和交互两个维度上的位置
然后...这个模型目前只是放了个视频,还没有正式开放,预计公开发布会安排在今年晚些时候
现在的 AI 通话,主流是怎么做的呢?其实流程跟用对讲机差不多:你说完,等一下,AI 回应。AI 说完,你再说...一轮一轮,循环往复
控制这个节奏的组件叫 VAD(Voice Activity Detection,语音活动检测),负责判断你有没有在说话。你停顿超过大约半秒,它就认定你说完了,触发 AI 回复。TML 在博客里是这样描述的:这个组件比模型本身笨得多,但它在主导整个对话节奏
人说话会停顿、会思考、会犹豫,但是呢... VAD 分不清「在想」和「说完了」,所以 AI 经常在你思考的时候抢话...讲道理,这个很烦...
于是,让模型自己学会判断什么时候该说、什么时候该听这件事就变得无比重要,并且得把 VAD 从系统里拿掉
TML 的做法是把时间切成 200ms 一个片段,叫「微回合」(micro-turn)。每个片段里模型先处理刚收到的输入,再决定是否输出。200ms 刷新一次感知,没有人工设定的轮次边界
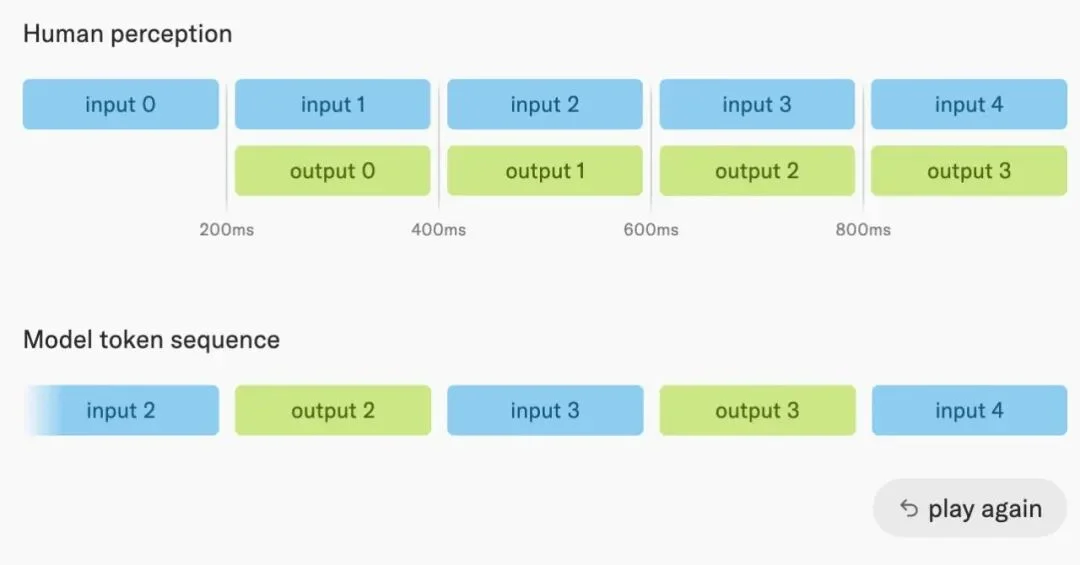
上面是人感受到的(同时),下面是模型看到的(交替)
而在面壁这一侧,框架叫 Omni-Flow,思路类似:把连续的音视频流切成时间片段,在共享时间轴上对齐
面壁在 2 月 3 日开源了 MiniCPM-o 4.5,2 月 6 日放出了可本地部署的实时 Web Demo,也发了技术报告,其实之前有比较详细的解读:让大模型【告别回合制】:同时看、听、说、一直察言观色|MiniCPM-o 4.5 开源
MiniCPM-o 4.5 是 9B 参数的端到端全模态模型,从编码到解码全部打通:视觉用 SigLIP ViT(0.4B),音频用 Whisper Medium(0.3B),语言模型用 Qwen3-8B,语音解码用一个 0.3B 的轻量解码器。所有组件通过 token 级的隐状态连接,可以端到端联合训练
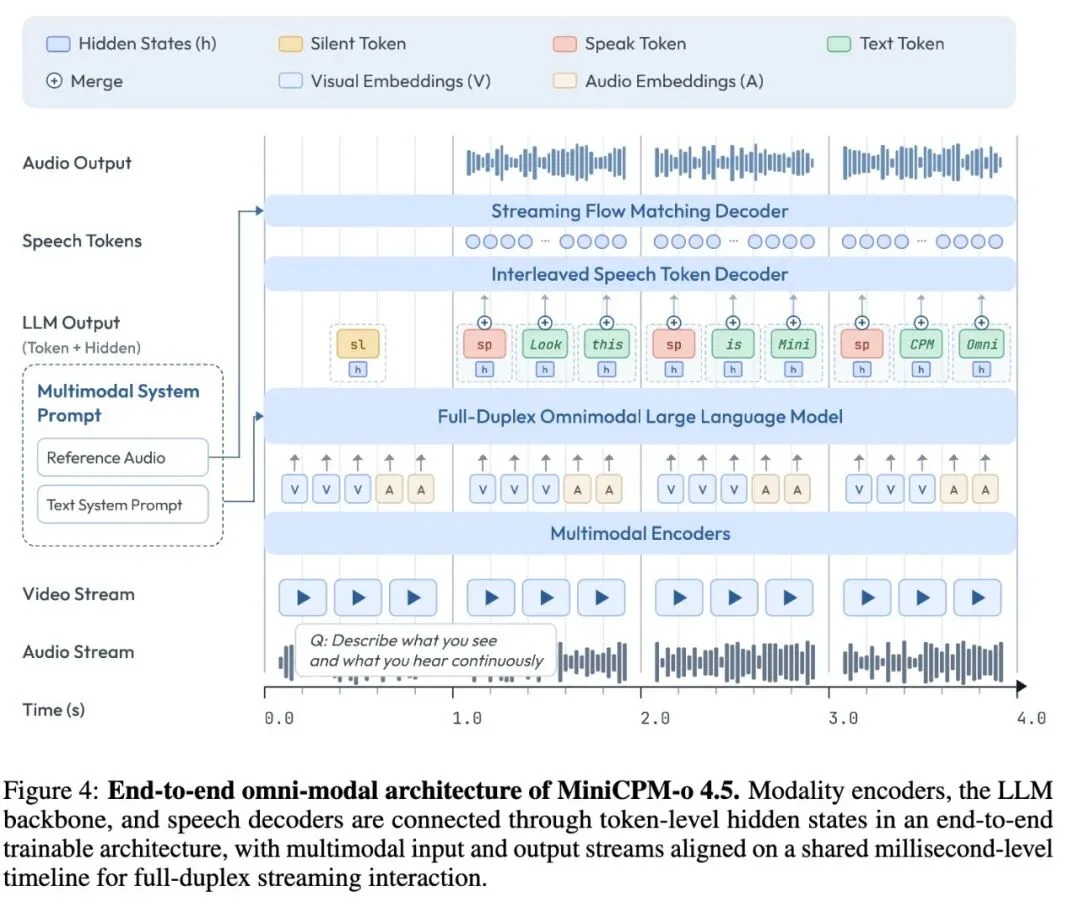
9B 参数,从编码器到语音解码器一路连到底
Omni-Flow 把交互过程切成以秒为单位的时间窗口。每个窗口内,模型先接收新的视觉和音频信号,再预测一个控制 token:「听」还是「说」。如果是「说」,再生成具体内容
面壁对 Omni-Flow 做了消融实验。时间窗口从 1.0 秒、0.2 秒到 0.1 秒都测了,1.0 秒效果最好。窗口太短,模型在每个片段内拿到的信息不够做稳定决策
面壁还处理了一个问题:模型生成文本很快,但把文本念出来需要时间。如果不做对齐,模型说出来的内容会滞后于当前语境。他们的 TAIL 技术让模型自适应控制每个窗口的文本量,保持语音和实时语境同步
部署方面,面壁开发了 llama.cpp-omni 推理框架,MiniCPM-o 4.5 在 RTX 4090 上的实时因子是 0.21,内存占用低于 12GB。模型权重和代码公开在 Hugging Face 和 GitHub
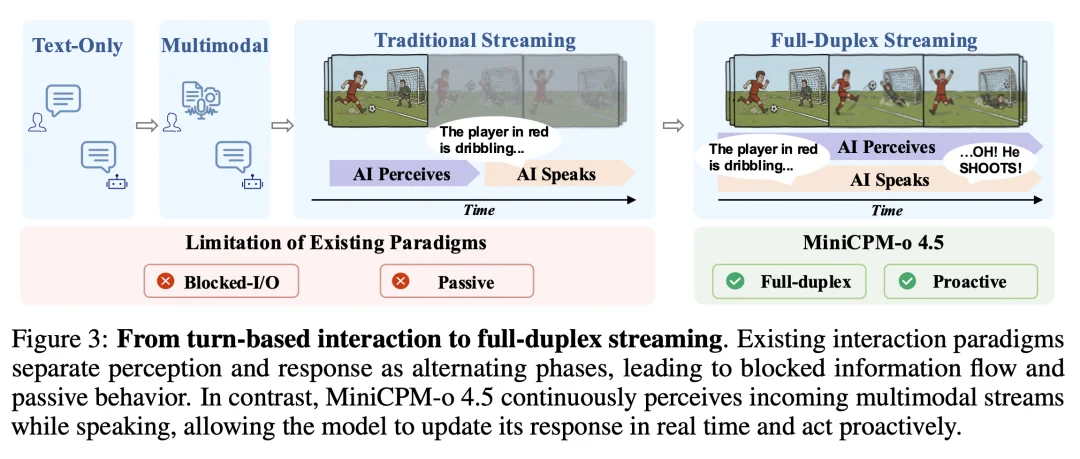
MiniCPM-o 4.5 边看边听边说的实时交互
两家对「为什么做」的判断几乎一致,在「怎么做」上走了不同的路
时间粒度:TML 选了 200ms,面壁选了 1.0s。 TML 的逻辑是粒度越细感知越快。面壁的消融实验给出了不同结论:0.2 秒的窗口里信息太少,模型决策不稳定。两家都没有公开对方粒度下的测试数据
编码器策略上,TML 不用 Whisper 这类独立编码器,直接把原始音频信号通过轻量嵌入层送进 transformer,从头联合训练。TML 在博客里引用了 Rich Sutton 的 Bitter Lesson:通用的学习能力最终会超过手工设计的组件。面壁保留了 Whisper Medium 和 SigLIP ViT
模型架构上,TML 拆成交互模型和背景模型两个,面壁用一个 9B 的统一模型覆盖全部
「是否说话」的判断方式也不同。TML 让模型隐式学会,而面壁用显式的 Listen-Speak 控制 token,先预测「听还是说」,再预测内容。面壁的消融显示拆开效果更好
部署目标上,TML 面向云端,面壁面向端侧
此外,TML 的博客里有一个细节。他们引用了 Anthropic 一份 model card 里的话:用户以同步的、手在键盘上的方式使用模型时,收益并不明显
边听边说这件事,TML 和面壁给出了各自的解法
以上
文章来自于"赛博禅心",作者 "金色传说大聪明"。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
