# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI范式从Chat转向Agent时,AI的能力边界正在被重新定义。
在探寻下一代AI助理差异化的关键节点,盛大集团副总裁、EverMind CEO邓亚峰提出了核心判断:
模型能力的差距正在缩小,在产品与业务实践中,记忆与数据层才是真正能沉淀下来的护城河。
他认为,未来的AI不仅要能完成任务,更需要像人一样,在与环境和用户的交互中不断自我进化。
而实现智能体“自主”与“自进化”两大特征的基石,关键在于长期记忆系统——这将是下一代AI基础设施的决定性战场,也正成为企业构建差异化竞争力的关键。

为了完整体现邓亚峰的思考,在不改变原意的基础上,量子位对演讲内容进行了编辑整理,希望能给你带来更多启发。
2026中国AIGC产业峰会是由量子位主办的行业峰会,近20位产业代表与会讨论。线下参会观众超千人,线上直播观众近400万,获得了主流媒体的广泛关注与报道。
以下为邓亚峰演讲原文:
当下,我们正在真正迎来数字世界的生产力革命。回顾语言模型的发展历程,有一个时间点可能被大家忽略了——2025年5月Claude 4的发布。

从今天来看,那实际上是智能体走向真正自主的关键节点。现在大家意识到,Claude在某些方面已经超越了OpenAI,但回到那个时间点,我们很多人并未充分认识到这一点。
关于“OpenClaw”的爆火,我简单谈谈我的理解。它让人感觉拥有了一个AI贾维斯,可以像人一样7×24小时工作,只需留言就能完成任务。
更重要的是,它将长期记忆、自主性等新的AI能力运用到了智能体之中,尽管目前做得还不够完善——前段时间风靡破圈,但我也知道很多人已经弃用。
核心原因不是大家不需要,而是它做得还不够好。
我的理解是,它有点像智能体时代的iPhone 4,定义了一种框架或产品范式;但它并不完美,需要不断迭代和超越。同时,它将几个核心组件明确了下来,这也是我们今后可以参考的。
大家已经深刻认识到,当前行业正从Chat转向Agent的范式,这也是Claude和Anthropic在估值上超越OpenAI的重要原因。

伴随着这种范式变迁,整个软件行业也发生了变化:
过去SaaS交付的可能是一套流程和界面,而现在更多是直接交付结果。交互方式也越来越以Message为主,更像人与人之间的交流。这是我们这个时代正在经历的剧变。
在这个时间点,我们的思考是:我们需要什么样的AI助理?
这里有几个关键定语:一是自主,二是自进化。

自进化意味着AI能像人一样,在与人和环境的交互中不断成长、优化,而目前的AI尚未做到这一点。因此我认为,自主和自进化是下一代AI智能体非常重要的两个Feature(特征)。
其中,与此最相关、最核心的底层技术,我个人认为是长期记忆。
一个Agent是由模型和Harness组成的,而Harness主要包括两部分:一是操作流程,包括Agent Loop和底层基础设施等;另一部分则是围绕数据或Memory构建的中间层,这正是长期记忆的核心价值所在。
抽丝剥茧来看,当模型能力越来越强时,Memory或Data这部分,反而更容易在产品与业务实践中沉淀为差异化的竞争力。
再回顾人类智能的构成,我们通常认为它由两部分组成:推理能力和长期记忆能力。
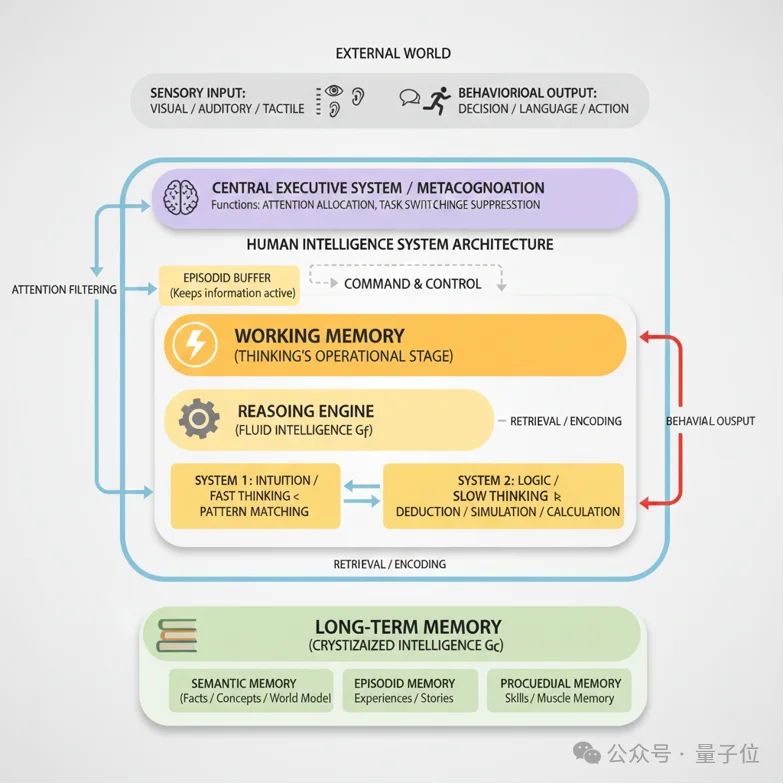
在人类进化过程中,长期记忆非常重要——比如记住哪里能找到食物、没有风险、没有威胁等,人类需要记住这些信息,然后预测未来。
我们曾与神经科学领域的一些专家交流,发现人之所以具备强大的泛化能力,很重要的一个原因在于,人具备在记忆中组织训练样本的能力。
也就是说,在人类智能中,记忆也至关重要。
当前,大家看到模型进展非常快,但在记忆方面的工作,今年才逐渐多起来,去年这个时候我们和行业里一些团队开始交流AI Memory,这方面的关注还非常少。
在Agent运行过程中,记忆有几个核心作用,我简单总结为三点:
第一,模型的上下文窗口长度有限,目前一般能做到1兆。
但在Agent运行过程中,上下文会急剧扩张,因此需要对信息进行抽象、总结,并为模型提供应有的信息。
这其中涉及效率、准确率、成本等多个关键问题。
第二,在与AI交互时,大家常发现AI很容易“失忆”——之前告诉它的事情,过段时间就忘了。
因此,Agent需要一个个性化和偏好对齐的过程,即让AI知道“这个人是谁、有什么偏好、身份、目标、价值观”。这也是长期记忆在Agent系统中非常重要的功能。
第三,对于Agent而言,我们一方面希望交代任务后它能完成,这是基本要求;更进一步的,是希望它在了解你全部历史的基础上,能主动提炼你可能感兴趣的事情,并提前处理,做完再询问你是否需要。
就像雇佣人类员工一样,最好的员工不仅能把交代的A任务完成得很好,还可能主动做了B和C。这需要AI具备一定主动预测的能力。
EverMind是盛大集团孵化的一个团队,我们主要的工作是基于长期记忆的核心技术研究,目标是打造具备自进化能力的自主Agent OS。
我们有一个平台叫EverOS,它的定位是“Agent Memory For AI Builders”(为AI开发者构建的智能体记忆系统)。

一方面,我们聚焦于Agent Memory;另一方面,我们认为,未来的AI Memory的Layer(记忆层),服务的可能不仅是资深的开发者,将来很多人都会构建AI应用。我们在产品序列上也有所考虑。
首先,我们希望服务于广大的AI Builders,并在其中内置强大的Self-Evolving(自进化)能力,也就是说,随着你使用我们的记忆基础设施,你的智能体会变得越来越好。
具体来说,它支持自进化、多模态(当前很多平台和技术尚不支持多模态),并且其本身跨平台、跨智能体——用户可以把在一个Agent上积累的记忆提取管理,用在其他Agent或平台上。
同时它还提供云版本和本地版本,两者兼容,本地版本主要采用Markdown文件结构。
在多项指标上,例如经典的Benchmark、上下文长度、准确率、响应速度(添加和Retrieve(检索)均为几百毫秒级)方面,我们都处于领先水平。
我们在token节省和模型成本方面也取得了显著的效果,原因是利用强化学习的方法训练了很小的模型——我们的4B模型在记忆提取和检索使用上的效果可媲美几百B的模型,并且已有不少学术成果发表。
例如《EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning》这篇文章总结了EverOS算法上的一些成果,已经被ACL 2026收录,文章提到我们在五个主流Benchmark上测试均取得了SOTA结果。
我们还开展了一项称为稀疏注意力机制(Memory Sparse Attention)的工作。这项工作的思考原点是:人一生的文本量约为几亿token,而当前模型上下文窗口一般在1兆左右,大概仅为1%。如果要让Agent陪伴人终身进化,有没有能让大模型具备可以端到端训练的、支持上亿token上下文的方案?

几个月前我们刚刚发表了《MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens》,能将上下文长度扩展到1亿,且对底层模型结构进行了修改,通过和大模型可插拔的结构实现真正的端到端。在常见问答任务上,其性能与当前SOTA模型相当。最关键的是,当上下文容量超过1兆时,大多数模型性能衰减严重,而我们的MSA能做到准确率基本保持平稳。
接下来,我简要介绍一下,我们当前在自进化能力方面所做的工作。我认为“AI越用越聪明”,一定是未来产品的重要Feature,为此我们做了以下几件事:
第一,整理现有Skill库。目前Skill库规模约为几十万,我们进行了质量筛选,最终提炼出7万多个Skills,大家可以直接使用,且都是开源、可商用的。
第二,当Skills数量非常多时,就不能简单依赖模型的渐进式披露,而需要技能匹配的策略与机制。我们在这方面也做了大量工作,精度和效率都很高。
此外,我们还实现了Skill的自进化——当每个人使用Agent时,会有成功和失败的经验,不同用户可能执行相似任务,同一用户也可能重复类似任务。
我们会将成功的经验积累下来,自动提取为Skills,当类似任务再次执行时,这些技能便会被自动调取和使用。
具体来说,我们整理了8000多个公开Skills仓库,通过安全性检查、去重、剔除无效项等一系列筛选流程,最终得到7万多个Skills,可供直接下载和使用。
在Skills的筛选机制上,与同参数量或稍小规模的通用模型相比,我们的检索指标更优。
此外,我们还推出了一个称为EvoAgentBench的评测体系,目前在Hugging Face上Agent Bench类别已经排到下载量第二名。截止当前,我们发布仅一个多月,主要用于评估智能体在四大类任务上的Performences。其中也包含一些Evolving策略的横向比较。可以看到,使用EverOS的Agent进化策略在任务执行成功率提升和任务轮次减少方面同样处于领先位置。
整体来讲,我们的工作主要是专注于长期记忆,并基于此发展Agent的自进化与自主能力,后续还会有其他与智能体操作系统相关的工作发表。
并且我们坚持开源,希望助力整个AI Builders和开发者的相关工作。
我们还针对Agent场景重新定义了Memory体系。

传统的记忆大多面向人类对话设计,而我们则定义了一套更适合智能体场景的记忆体系,包括智能体的身份设定、角色、目标、价值观、行为准则等,这就是Agent Memory的部分。
其次,Agent执行任务时也需要了解用户,因此会有User Memory的部分,涵盖时间、地点、事件、行为历史,以及用户自身的偏好、身份、价值观、历史偏好等。
此外,我们的工作还包括世界知识,我们称之为“LLM Wiki”,以上三部分我们都支持。
在技能方面,我们做了深入工作:
一方面,大家可以使用我们筛选后直接可用的Skills,并享受配套的检索策略。
另一方面,这些Skills会随着使用不断沉淀、优化。
最理想的情况是,模型与Harness能不断自我迭代、自我演化,就像推荐系统一样,这一定是未来的趋势。
我们还有一个核心观点:未来一个人可能会使用多个Agent,但记忆应当属于个人,数据也应当属于个人。创建和使用Agent的能力也正在从开发者普及到更广泛的专业人士群体。
因此我们推出了EverMe产品,核心是帮助更广泛的用户管理跨智能体、跨平台的数据和记忆。

你在Codex、Claude Code、OpenClaw、Hermes等Agent中的记忆可以汇集管理并优化,用于你后续在这些产品中的体验,或者快速冷启动一个新的Agent时达到最优配置。这些记忆属于你自己,并在一个地方同步。
基于此,我们最重要的设想是:当一个AI拥有了你的记忆和数据后,它应当是最最了解你的,你未来的意图也可以从这里分发,这就是我们正在做的事情。
更多信息参考链接:
官网:EverMind.ai
开源入口:https://github.com/EverMind-AI/EverOS
文章来自于"量子位",作者 "编辑部"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
