# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

越过从记忆到理解的鸿沟。
5 月 14 日,OpenHuman 登上 GitHub 榜单,并在这个月中旬经历了爆发式增长。仅仅 6 天之内,它从 3,489 增长到 14,227 stars,日均增长 1,690 stars,连续霸榜第一约一周之久。截至研究日,更是已经突破 18,600 stars。
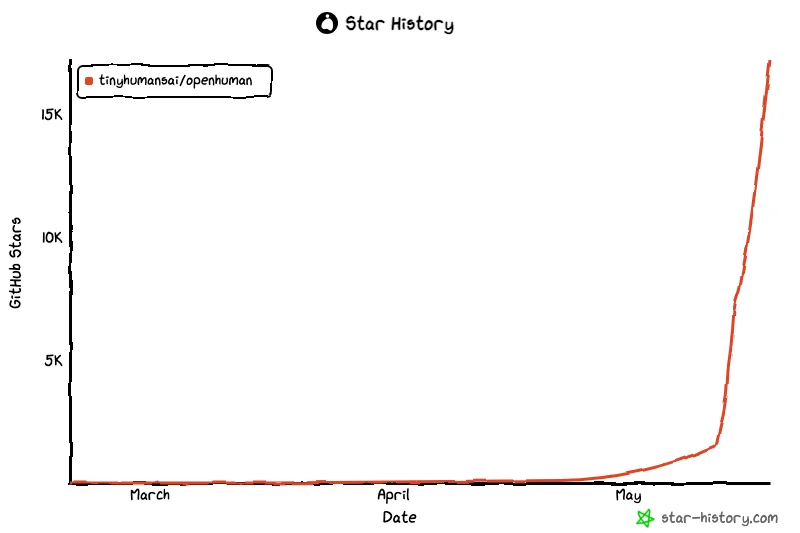
OpenHuman 是一款由开发者集体 TinyHumans AI 构建的开源桌面 AI Agent。它的自我定位是「Personal AI Super Intelligence」,即一个私有、简单、极其强大的个人智能体。
从品类上看,OpenHuman 既不是 IDE(不写代码),也不是聊天机器人(有工具调用和自动化能力),也不是笔记软件(虽然它生成 Obsidian 兼容的知识库)。
它试图成为一个桌面级的个人 AI 操作系统入口,把记忆、集成、语音、编码工具、本地知识库塞进同一个 Agent 框架里。
而在桌面级智能体助手迭出的今天,它的核心主张也可以用一句话概括:在用户输入第一个 prompt 之前,Agent 就已经了解你。
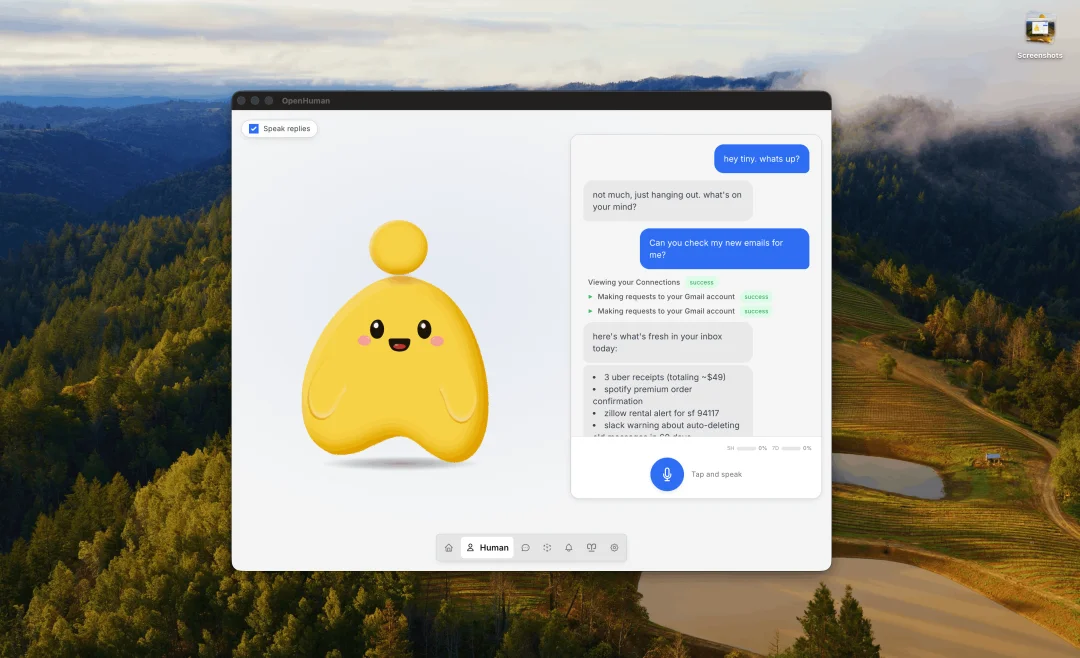
从制作者自己在 Product Hunt 上的评论中可以看到,这个项目的初衷其实很朴素。创始人想给自己的老爸配置一个 AI Agent,但发现市面上的智能体配置都太复杂了,从装终端、配 API Key,到写 YAML,一般人根本玩不转。于是他想做一个,真正能一键开箱即用的产品。
这个出发点是真诚的。但 AI 产品或者 vibe coding 这事,往往梦想很庞大, 落地都一地鸡毛。我们上手之后很快就发现,OpenHuman 的实际使用体验和愿景,还有着不小的距离。
最明显的问题是,「在第一个 prompt 之前就了解你」的主张,隐含着一个巨大的前提条件:
你必须主动、尽可能多地绑定第三方服务。

如果用户不连接 Gmail、GitHub、YouTube 等账号,这个 Agent 就会对你一无所知,它会退化成一个普通的聊天窗口,和免费的 ChatGPT 没有本质区别。
所谓的“分钟级了解”,完全建立在用户绑定账号的“分钟级手速”之上。但谁会在接触一款新产品的第一瞬间,就急头白脸地交出几乎所有权限?
这是 OpenHuman 给我们留下的第一印象,冒昧,而现实的骨感之处还有更多。
使用 OpenHuman 的过程中,一种很强烈的感受在于,这是一个商业化野心远超产品完成度的项目。
这种洞察甚至先于真正上手使用,因为我们发现主界面已经高调加入了「奖励」模块。也就是说当产品还在 Early Beta,功能还有大量粗糙边角的时候,推荐奖励系统就已经就位了。这种对优先级的选择,本身就传递了很多信号。
此外如果用户不订阅 OpenHuman 的付费计划,而是配置自己的 API Key,那么得到的只会是一个聊天框。没错,连 tools 都无法使用。
免费情况下所有工具调用能力被锁死,Agent 的手和脚被没收了,核心功能完全不可用。此时的OpenHuman 只剩一张嘴,这意味着「一键开箱即用」的愿景,必须靠充值才能实现。
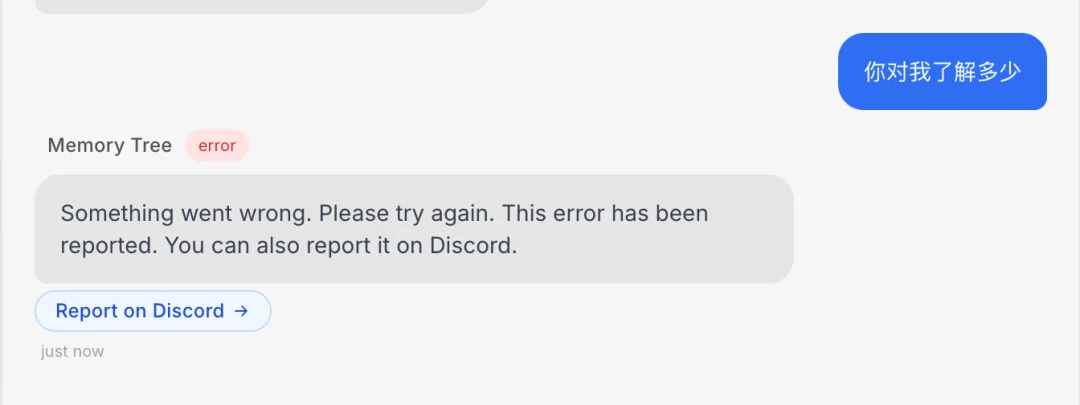
公平地说 OpenHuman 确实提供了一定的免费额度,但实测下来大概只支持三次简单问答。甚至于用户一句话都不说的情况下,如果 Agent 绑定了几个第三方账号,那么系统自动抓取数据消耗的 token,也足以把免费额度吃光。用户还没来得及输入第一个 prompt,Agent 就死在了没额度上。

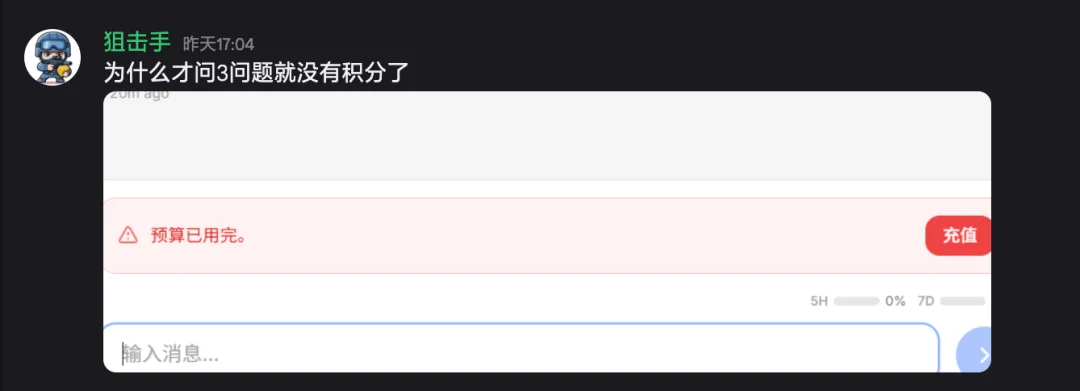
产品的梦想是「在输入第一个 prompt 之前 Agent 就足够了解你」,但现实是「在输入第一个 prompt 之前 Agent 就已经把你的免费额度花完了」。
可以看出,OpenHuman 宣称的低成本、无摩擦使用,完全建立在充值之上。
细想之下 OpenHuman 其实展现出了相当魔幻的一面。
一方面,市场上已经有不少能够一键开箱即用的免费 Agent 产品,甚至于 ChatGPT 某种程度上也可以归于此列。另一方面,OpenHuman 选择了「付费」作为用户转移学习成本的方式,但付费本身就是巨大的用户使用成本,它和「简单」的目标自相矛盾。
当然,这也不能全怪 OpenHuman。AI 的推理成本确实昂贵,对于一个需要每 20 分钟自动抓取数据、持续构建记忆树的系统,token 消耗更是普通聊天的数倍。
这或许也反映了 AI 创业的一个残酷现实,如果没有足够充裕的启动资金来补贴冷启动期的用户体验,就会重现 OpenHuman 这种尴尬的剧本,产品还没让用户感受到价值,就已经开始要钱了。
抛开体验层面的粗糙,这款产品在工程架构上确实有值得关注的设计。
OpenHuman 的核心架构是一条三阶段管道:
▪ 连接:OAuth 接入 118+ 服务
▪ 抓取:每 20 分钟自动轮询
▪ 记忆:转换为 Markdown,构建 Memory Tree
这种设计意图很清晰,就是为了让 Agent 能在后台持续积累对用户的了解,无需用户主动投喂数据。当一众 Agent 产品都在宣称自己“越用越懂用户”,OpenHuman 把这个过程的开端,拉低到了只要能在用户的设备上跑起来即可。
为了实现这一点,OpenHuman 的技术栈选择了 Tauri,即 Rust 后端加 WebView 前端。必须承认开发团队确实非常细节,相比 Electron,Tauri 更轻量、更安全、更省内存,适合需要长期后台运行的 Agent 应用。从这个选型就体现出了团队对产品形态的思考,当它需要像一个系统服务一样常驻后台,Electron 的资源开销在这个场景下就是不可接受的。
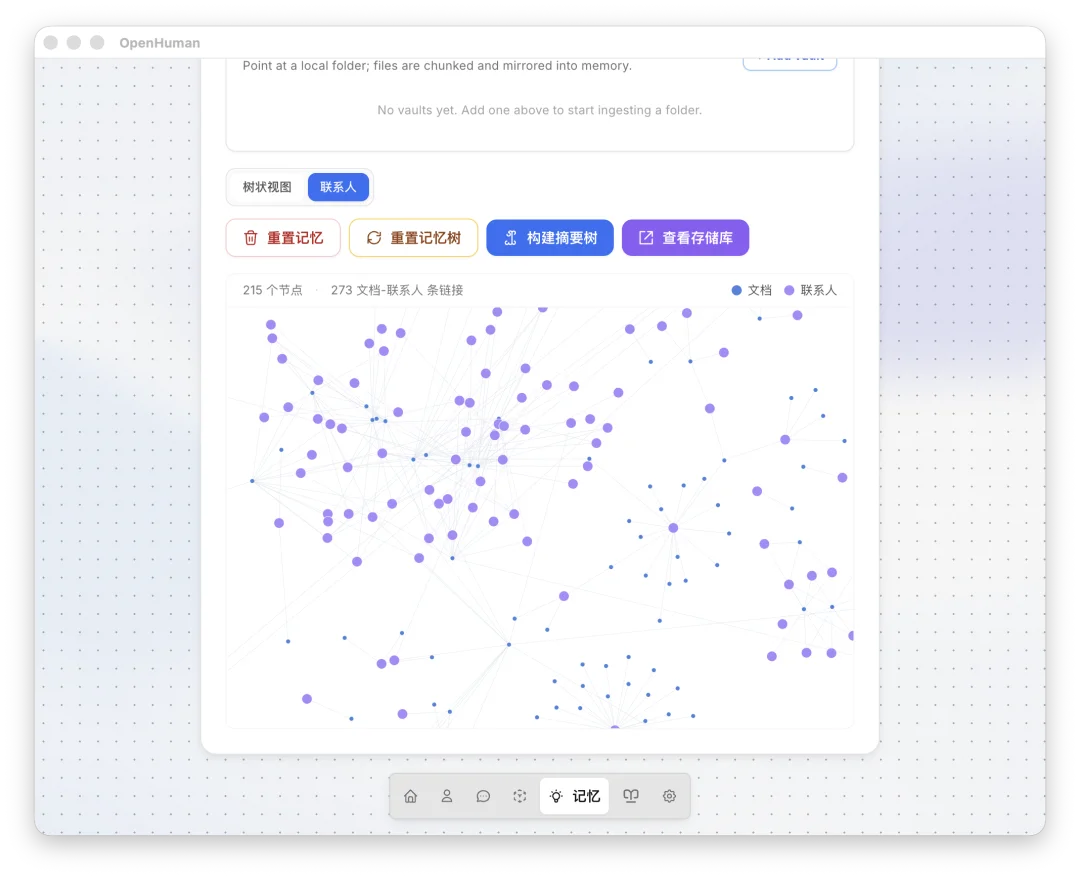
此外还有 Memory Tree,这是 OpenHuman 最有技术含量的部分。关注 Andrej Karpathy 的朋友或许有印象,他在今年 4 月提出了一个名为「LLM Wiki」的概念,也就是用 LLM 将原始数据编译成结构化的 Markdown 知识库。
OpenHuman 把这个手动过程完全自动化了,多源数据抓进来,经过标准化、分块(≤3k token)、评分,最终形成层级摘要树,分别存入SQLite(供机器检索)与obsidian Vault(方便人工查阅)。
这里面最关键的设计决策是可检视性,用户终于可以直接打开、阅读、编辑 Agent 的知识库。这和传统 RAG 的向量黑箱形成了鲜明对比,当你能看到 AI 到底「记住」了什么,才能谈溯源和纠正。
这类工具调用 Agent,有一个通病是反复召回导致的上下文爆炸。OpenHuman 也考虑到了这一点,它的架构中有一层名为 TokenJuice,这是一个用于 token 压缩的中间层。原理并不复杂,HTML 转 Markdown、长 URL 缩短、噪声清理、内容去重,同时保留 CJK 和 emoji 等多字节文本,但官方声称,就是这一套流程下来,可以降低高达 80% 的 token 消耗。
比起实现路径,这种工程思路显然更珍贵。在 Agent 系统中,真正昂贵的是后台抓取和工具调用产生的 token,在数据进入模型前做清洗,一定比直接塞原始内容更经济。
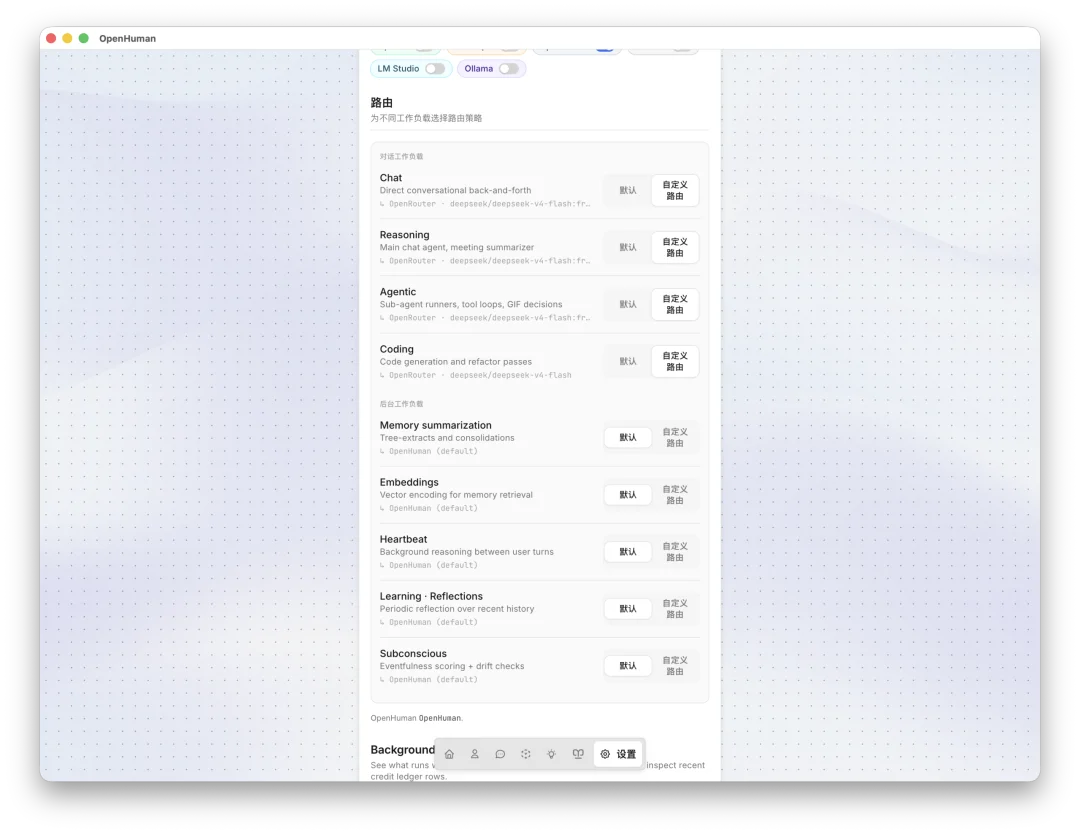
OpenHuman 另一处比较少见的设计,是提供了非常丰富的内置智能路由。推理密集任务走前沿大模型,常规任务走便宜模型,图像走视觉模型,支持 Ollama 本地推理,成本控制更加合理。
从 OpenClaw、Hermes 到 OpenHuman,短短半年间,已经有三代 Agent 在 GitHub 上各领风骚。有意思的是,你能看到三者之间在工程思路上存在着根本差异。
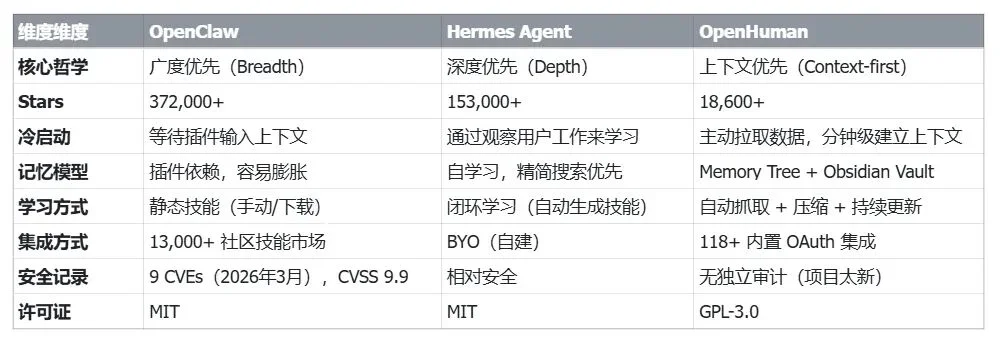
OpenClaw 特征最鲜明,它在试图构建的是一个 Agent 控制平面,在此基础上才有了多 Agent 团队、跨通道路由和 Skill 市场,使用体验很像是在管理一个公司的 Agent 组织。
Hermes 的关键词则到了自进化。外部环境、脚手架……这些描述背后的共性在于,它们都看到了 Hermes 服务于单 Agent 持续改进的一面,这也是 Hermes 最核心的产品逻辑,即检测重复模式,然后自动生成可复用技能,就像是训练一个越来越聪明的助手。
沿着这条脉络,就不难理解 OpenHuman 的宣言。在使用之前就开始了解用户,也就是不需要等待用户教,而是主动「认识」用户。这是一种「上下文即产品」的 Agent 哲学,把用户的个人数据积累变成结构化记忆,此时的 Agent ,像是一个从 Day 1 就认识了你的同事。
当然,为此带来的风险也是结构性的,OpenHuman 的价值主张和安全风险本就一体两面。
首当其冲的是 OAuth Token 聚合。
同时持有邮件、代码、日历、支付的 OAuth Token,本地 SQLite 数据库就会成为高价值攻击目标。2026 年已有前车之鉴,Context.ai/Vercel 事件中,攻击者通过窃取 OAuth Token 横向移动到 Vercel 内部系统,OpenClaw 的「Claw Chain」四漏洞链影响了 245,000 台服务器。OpenHuman 面临完全相同的结构性风险,且目前没有任何独立安全审计。
此外还有 curl | bash 安装。对于一个即将获得你邮件、代码、日历、支付信息访问权限的工具,管道安装是已知的供应链攻击向量。2025 年 ClickFix 攻击增长 517%,核心手法就是诱导用户在终端执行远程命令。
而在所有风险之上,更值得深思的是 OpenHuman 自身发布的,未经验证的技术声明。前文提到的 80% token 压缩率、20 分钟同步可靠性、Memory Tree 的规模行为都是项目自述,无第三方验证。而压缩层决定了哪些信息被保留、哪些被丢弃,对于敏感场景,这是不得不慎重的问题。
这些风险是 feature 的副作用。要做到「分钟级了解你」,就必须同时获取大量敏感数据,要「一键设置」,就必须简化安全边界,要「持续更新记忆」,就必须保持长期有效的 token。OpenHuman 的价值和风险,在架构层面就是绑定的。
尽管 OpenHuman 本身在完成度和商业化上有着诸般漏洞,但它提出的产品哲学仍然值得认真对待,甚至可以说,这正是 OpenHuman 最具价值的部分。
「上下文即产品」的核心主张是:当模型能力趋同后,产品的核心价值不在于它能做什么,在于它知道什么。同样的模型,给它不同质量的上下文,产出的价值天差地别。
这项主张背后有一条清晰的逻辑链。当技术能力从稀缺走向充裕,Agent 能力真正商品化,竞争焦点就会从「我能做什么」上移到「我能帮你做什么」,此时对用户的理解就变成了新的稀缺资源。
这个链条在从网络带宽到内容推荐,从相机像素到计算摄影,从CPU 主频到用户体验等多个行业,已经被反复验证过。
OpenHuman 的出现仍然是对这种历史进程的重复,也就是在 Claude、GPT、Gemini 能力逐渐趋同的节点上,试图卡住「更了解用户」的身位。
但这里有一个关键的辨析,记住 ≠ 理解。
OpenHuman 目前做到的是「跨源记忆」,用户授权之后从多个平台拉取数据,压缩存储,被动检索。这解决了从 0 到 1 的问题,也就是让 Agent 有记忆。但是从「记住」到「理解」还有巨大的鸿沟,理解意味着关系推理、意图预测、价值对齐,在诸多孤立的信息点之间,建立逻辑和图景,描述未来和价值。
与此同时,「记住一切」也未必是正确答案。 记忆也有边际递减,真正有价值的不是记住更多,而是在关键时刻调用关键记忆。OpenHuman 「全量抓取 + 压缩存储」的路线,可能不如「少而精的关键记忆 + 强推理」更接近「理解」。
理解是记忆、推理、目标模型的乘积。 三者缺一,都只是更高级的搜索引擎。
这或许就是 AI 产品的下一个竞争维度,一个夹在模型和用户之间的、负责积累和管理用户上下文的「理解层」。OpenHuman 对此的洞察很可能是正确的,但全量抓取、压缩存储、被动检索只是这个方向上最早期、最粗糙的一次尝试。
因此如果你问我如何看待 OpenHuman。
我会说这是一个方向正确、时机精准、但执行粗糙、商业化过早的产品实验。它最大的价值不在于做出了什么,而在于它定义了一个好问题:当模型能力面临边际递减,如何越过从记忆到理解的鸿沟,会是构建护城河的关键。
这中间的差距,既是它的局限,也是整个行业的机会空间,反之亦然。
文章来自于"AI科技评论",作者 "星龙"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
