# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天一早,谷歌又发新模型了!
Gemmna 家族有了新成员 ——DiffusionGemma,一个探索文本扩散的实验性开源模型,在文本生成任务上速度极快。
根据官方介绍,DiffusionGemma 采用了 Apache 2.0 许可证发布,是一个 26B 规模的混合专家模型(MoE)。
该模型没有沿用典型自回归大语言模型(LLM)那种按顺序、逐 token 生成的方式,而是可以同时生成整块文本,在 GPU 上,文本生成速度最高可提升至 4 倍。
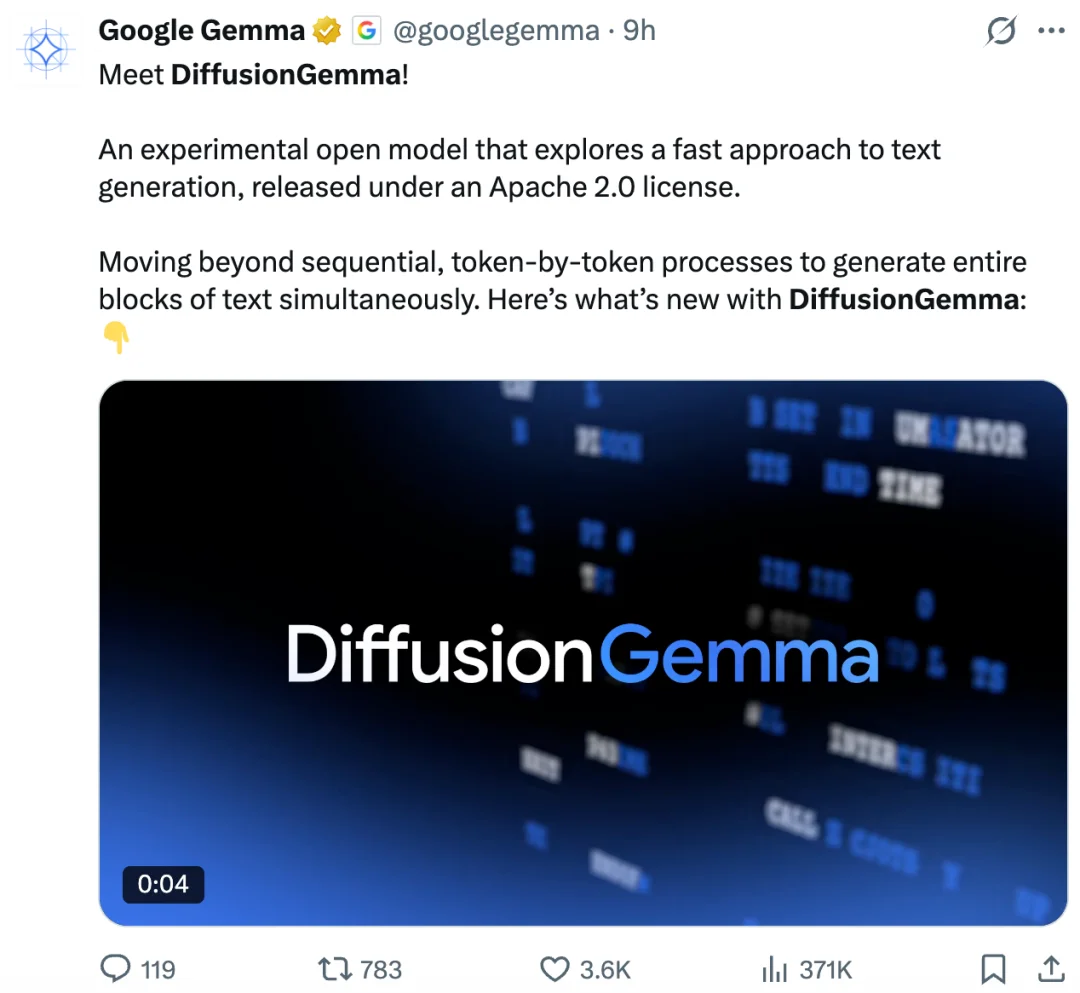
DiffusionGemma 建立在 Gemma 4 家族业界领先的「每参数智能水平」之上,同时吸收了 Gemini Diffusion 的前沿研究成果。它引入了一种全新的扩散式输出头,目标很明确:尽可能提高生成速度。
需要说明的是,自回归版本的 Gemma 4 仍然是高质量生产级输出的首选。而 DiffusionGemma 更适合研究人员和开发者探索那些对速度要求极高、强调本地交互体验的工作流,比如行内编辑、快速迭代,以及生成非线性的文本结构。
谷歌 CEO 皮查伊表示,「DiffusionGemma 是一款开放的实验性模型,它把我们的文本扩散研究带到了 Gemma 4 上。速度像赛马一样快 🏇:通过一次性生成整块文本,而不是逐 token 预测输出,推理速度最高可以提升至 4 倍。」
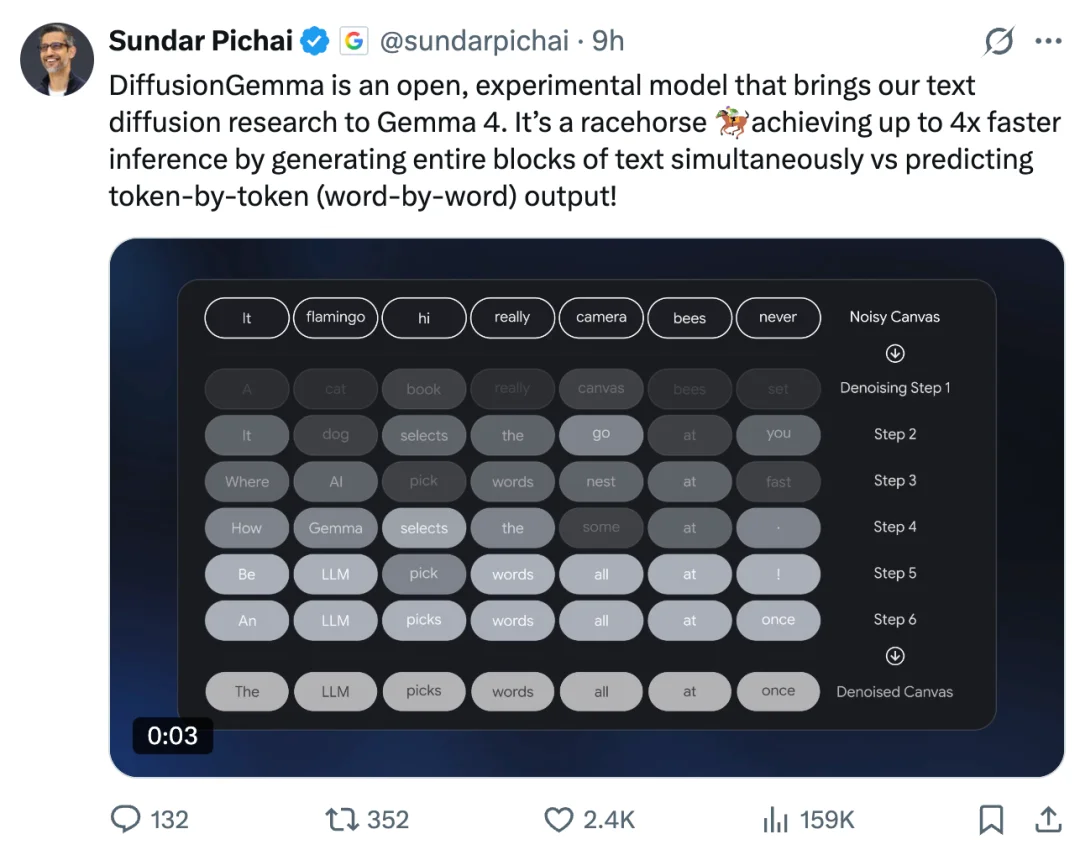
对实时交互式 AI 应用开发者来说,本地推理最大的痛点之一就是延迟。DiffusionGemma 正是针对这个问题而来,但也做出了一些取舍。
首先是推理速度非常快。
DiffusionGemma 将解码瓶颈从内存带宽转向计算本身,因此在专用 GPU 上,token 输出速度最高可提升至 4 倍。在单张 NVIDIA H100 上,它可以达到每秒 1000+ tokens;在 NVIDIA GeForce RTX 5090 上,也能达到每秒 700+ tokens。
其次是硬件门槛相对友好。
DiffusionGemma 是一个总规模为 26B 的 MoE 模型,但推理时只激活 3.8B 参数。经过量化后,它可以比较轻松地运行在 18GB 显存以内的高端消费级独立显卡上。
第三,它支持双向注意力。
每次前向计算可以并行生成 256 个 token,并且每个 token 都能看到其他 token。这让它在一些非线性场景中更有优势,比如行内编辑、代码补全、氨基酸序列生成,或者数学图结构。
第四,它具备一定的自我修正能力。
模型会通过多轮迭代不断 refine 自己的输出,并且可以一次性查看整个文本块,从而实时发现并修正错误。
不过,DiffusionGemma 目前仍然是一个实验性模型。因为它更重视速度和并行布局生成,整体输出质量低于标准版 Gemma 4。如果应用场景对质量要求最高,官方仍然建议部署标准版 Gemma 4。

开发者也可以通过微调,让 DiffusionGemma 在特定任务上表现更好。
下面这个例子中,Unsloth 对 DiffusionGemma 进行了微调,让它学会解数独。数独对自回归模型并不友好,因为每个 token 往往都依赖后面的 token;而 DiffusionGemma 的双向注意力机制,让这类任务变得更容易。
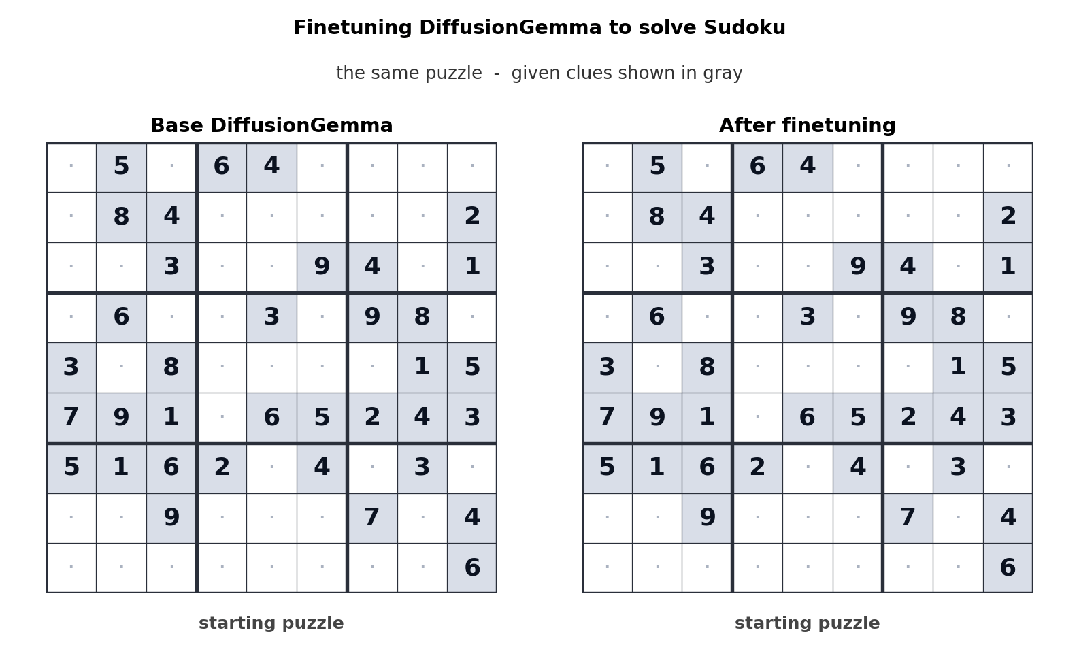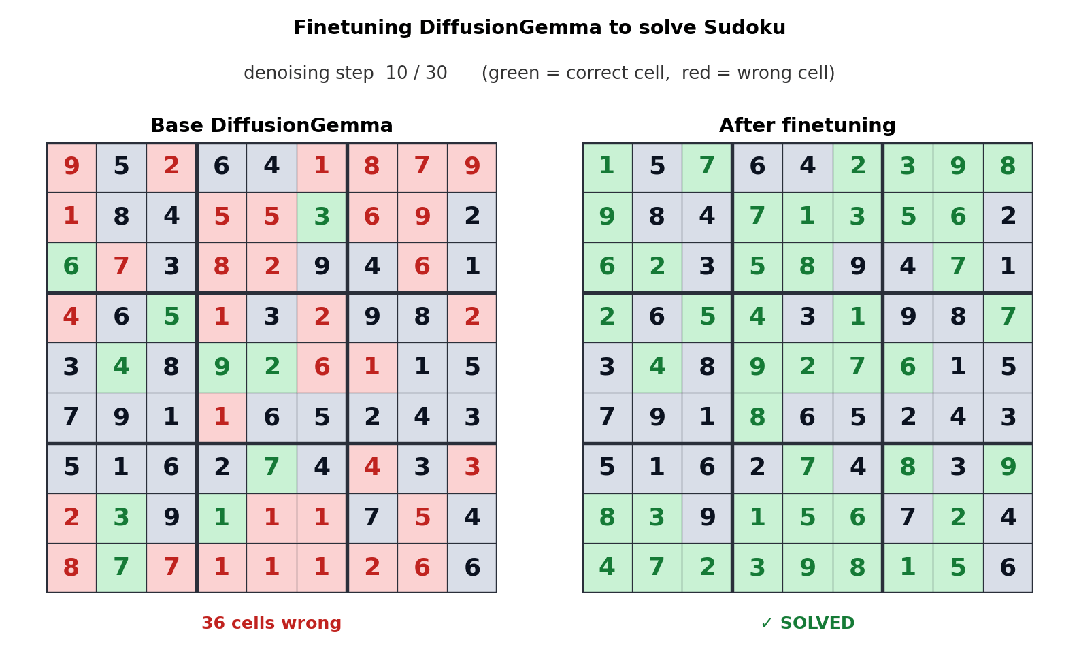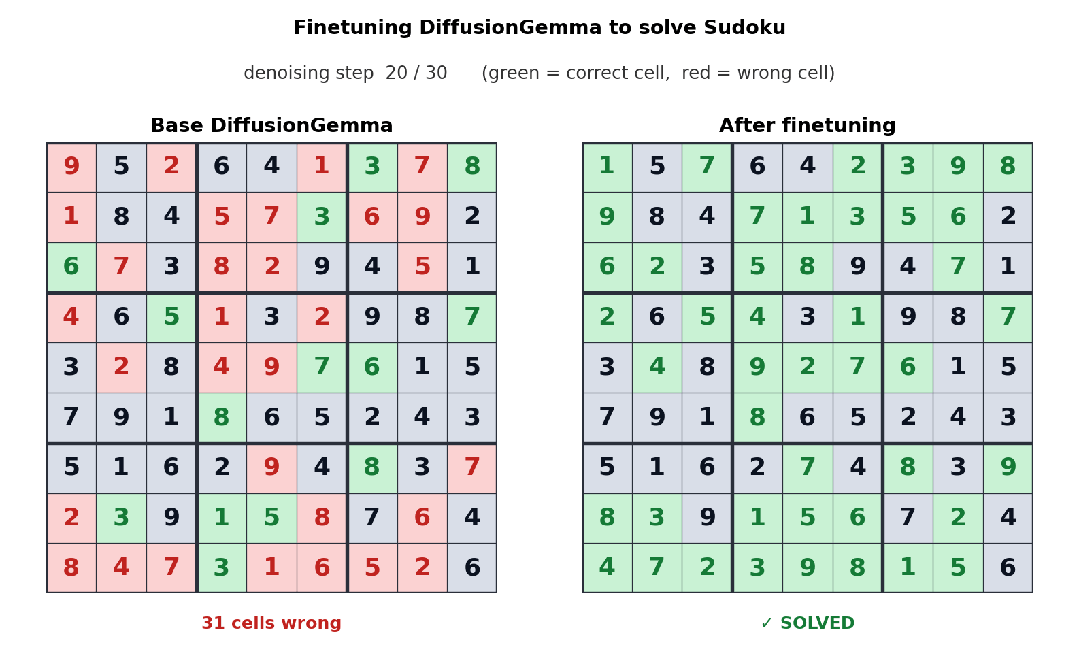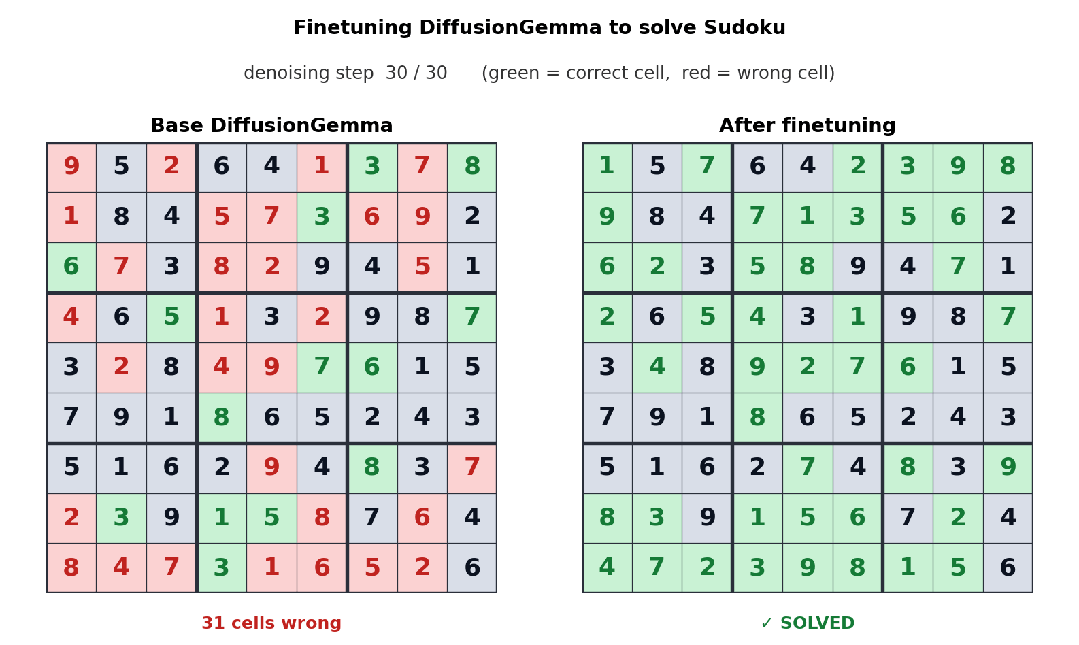
经过微调后,DiffusionGemma 正在解数独。
过去几年,AI 研究社区一直在探索基于扩散的文本生成方法,但要把它应用到大模型上并不容易。
DiffusionGemma 的突破点在于,它改变了模型使用硬件的方式。
传统语言模型更像一台打字机:从左到右,一个 token 接一个 token 地生成。在云端,这种方式很高效,服务器可以同时批处理成千上万个用户请求,让硬件资源被充分利用。
但在本地运行、只有单个用户请求时,这种逐词生成的方式反而会让你的独立 GPU 或 TPU 处于低利用率状态。它大部分时间都在等下一个「按键」。
DiffusionGemma 则把这个问题反了过来。它不是按顺序一个词一个词地预测,而是一次性起草整个 256-token 文本块。这样一来,处理器每次都能拿到更大块的计算任务,硬件利用率也更高。
换句话说,它把模型推理从一台顺序敲字的打字机,升级成了一台可以同时印出整块文本的高速印刷机。
Hugging Face 制作的 DiffusionGemma text-to-3D SVG 演示,展示了逐步生成过程。
这也意味着,DiffusionGemma 的速度优势主要面向本地推理和低并发推理场景。在高 QPS 的云端服务中,自回归模型本身就可以通过批处理充分吃满算力,因此 DiffusionGemma 的并行解码优势会被削弱,甚至可能带来更高的服务成本。
它的吞吐优势,主要体现在单个加速器上的低到中等 batch size 场景。
博客地址:https://blog.google/innovation-and-ai/technology/developers-tools/diffusion-gemma-faster-text-generation/
文章来自于"机器之心",作者 "机器之心编辑部"。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
