# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近整个世界的魔幻程度,真的让人唏嘘。
今天早上,Anthropic收到了美国商务部的一封信。
信的内容很简单,以国家安全为由,要求Anthropic立刻暂停所有外国公民对Fable 5和Mythos 5的访问权限。
而且不只是美国境外的用户,也包括美国境内的外国公民,甚至包括Anthropic自己公司里的外籍员工。
然后Anthropic做了一个让所有人都没想到的决定,为了确保合规,直接把Fable 5和Mythos 5对所有用户全部关停,老美自己也用不了了。
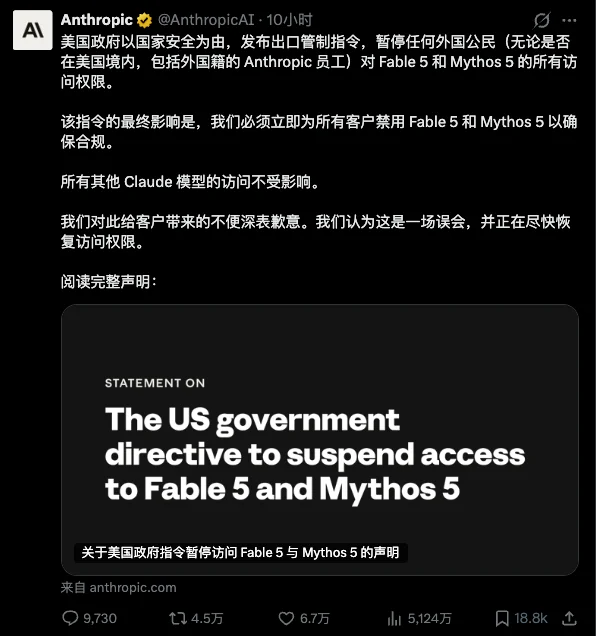
X上直接爆了5000万的阅读。
这个事引起了轩然大波,全网直接爆了。
我中午睡醒一看,心都凉了半截,因为Claude fable 5在纯粹的代码执行能力上,我觉得其实Opus 4.8和GPT 5.5也能干,但是他的方案构建能力、架构能力、产出的完整度和全面程度,是任何一个模型都比不了的,刚刚让它帮我完成了AIHOT精选算法的优化,还有移动端的全面适配和重构,今天刚准备开发完小程序,直接就没了。。。

仅仅4天,这个号称全世界最强的模型,就被召回,全面下线。
再结合这次世界杯强调全球大团结的背景之下,一个索马里的世界杯裁判在美国被禁止入境,从而缺席世界杯赛场。
这个世界的格局,好像越来越不一样了。
好像,也越来越封闭了。
就在我们落寞的看待着这一切的时候。
下午2点19,智谱突然发了一篇公告。

“在一些前沿模型突然变得不可用的时刻,我们选择相信另一条路:前沿智能不应只属于少数人,也不应被少数规则随时收回。它应该开放、可用、可构建,并服务于每一位开发者。”
我的朋友圈瞬间就被刷屏了。
而且这一次,GLM 5.2,继续开源。
GLM 5.1的口碑,在技术圈和AI圈的口碑有多好就不需要我再复述了,基本上是公认的国产之光,为数不多的能跟Claude和GPT掰掰手腕的模型,在Coding和Agent能力上,也是我给所有用不了海外模型的朋友,都推荐的首选模型。
要不是因为算力限制,国内几乎都没有卡,无论是训练还是推理,几乎都比国外少N个数量级,我真的觉得,像智谱、DeepSeek之类的,是绝对能做出不亚于海外那两家公司的模型的。
这一次非常的事发突然,看到他们发布的时候我甚至还在外面吃饭,下午的事都推了,急急忙忙赶回家,还好我的Coding Plan还在,然后拿到了GLM 5.2的权限。
这里说一下,今天GLM 5.2上线的是智谱的Coding Plan,你可以把Coding Plan理解成Claude和GPT的订阅,也就是你只有订阅过的用户才可以使用。
下周会上线API方式,并且会直接开源出来。
而且今天他们5点21上线的这个时间点也非常的有梗。
因为Anthropic是5点21收到的信,所以,智谱选择5点21开放。

一边在关门,一边在开门。
一边说前沿智能是国家安全风险,一边说前沿智能属于所有人。
真的能笑死,戏剧性也属实是拉满了。
Coding Plan稍微蛋疼一点的就是,他们的算力太少了,没办法支持所有用户的推理请求,所以Coding Plan只能限额,也就是这个玩意你想买,是需要靠抢的。。。
所以如果想用的,记得每天早上定个10点的闹钟,去抢一下。
我自己在测完和跟一些朋友对完之后,我想说,这就是国产模型的新高峰,至少在我的层面,除了算力资源问题,会显得很慢之外,在纯粹的结果上,只要你不是强设计类型的东西,GLM 5.2做任务跟Opus 4.8好像差的也不多。
在大型工程、长任务、后端等等上面,很强,非常强。
差距我觉得其实就在前期方案的先进和完整度、还有设计的差别上。
优点就很多了,GLM 5.2输出的东西我看的懂,能聊的明白,幻觉极低,稳如老狗,而且这次整个上下文长度终于加到了1M,这就很棒了。
在测试过程中,400~500k左右的上下文长度左右,准确性和指令遵循跟Claude差距不是很大,非常的稳,我写的Claude.md到了400K这个长度的时候也能遵循没啥问题,我自己一般喜欢在这个位置用我的洁癖.skill手动存档,再往后比如500k~1M的这个区间,我一般很少会涉及到了。
最最最可惜的是,GLM 5.2,还是没有多模态,依然是个纯文本模型。
干活程度也没啥毛病,我的评价是更像一个勤勤恳恳的老黄牛,活肯定能给你干好,它的聪明程度肯定还比不上Claude Fable 5这种级别,跟Opus 4.8的聪明程度也差一点,但是也已经非常好了。
举个例子,我今天AIHOT上的一个小任务。
就是我前段时间为了自己的学习,也为了省一点自己的时间,所以用一些有趣的手段,监控了一些我常看的公众号方便我第一时间知道信息,但是呢,今天发现了一个BUG,就是智谱的公众号是我监控了的,今天的GLM 5.2的消息是2点19发的,但是在AIHOT里,居然没监控到,等到4点的时候,智谱发了X,才看到。
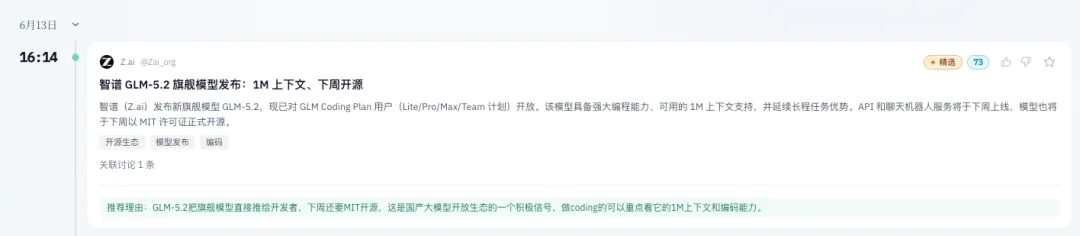
这就很奇怪了,于是我把这个问题,直接让GLM 5.2试了一下。
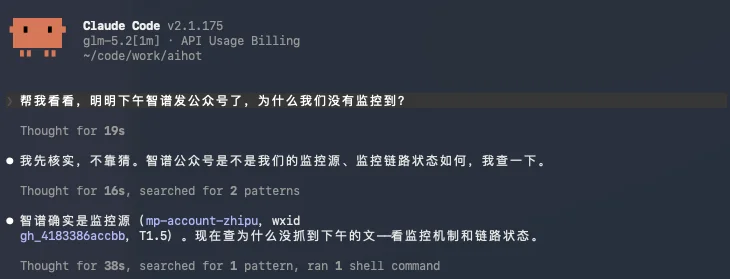
其实在它去解决的过程中,我已经大概知道是什么原因了,前段时间切换了监控方案,现在是两个监控方案线上灰度并行,大概率是我们后来切换的一个三方API账户里没钱了,我前天就想着要充来着,但是忙忘了。
不过也正好,这么个小事,可以看一下模型的聪明程度,我这个项目大概10万行代码,因为有各种监控和调度,所以后端逻辑会稍微复杂。
随后GLM 5.2找到了这个问题,其实本质上是智谱好几天没发文章了,跟我们抓取的体系没啥关系。。。
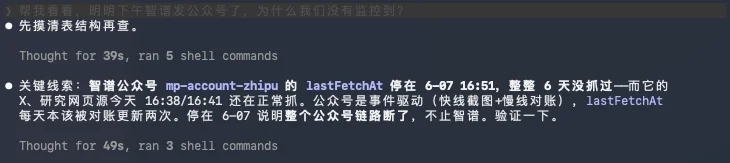
然后他就沿着这条路推了下去,以为是我们整个监控体系BUG了。
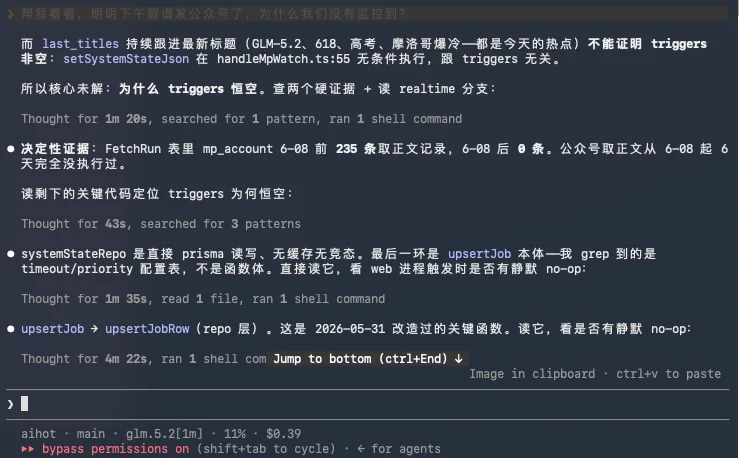
然后自己思考了一阵子以后,又推翻了一次。
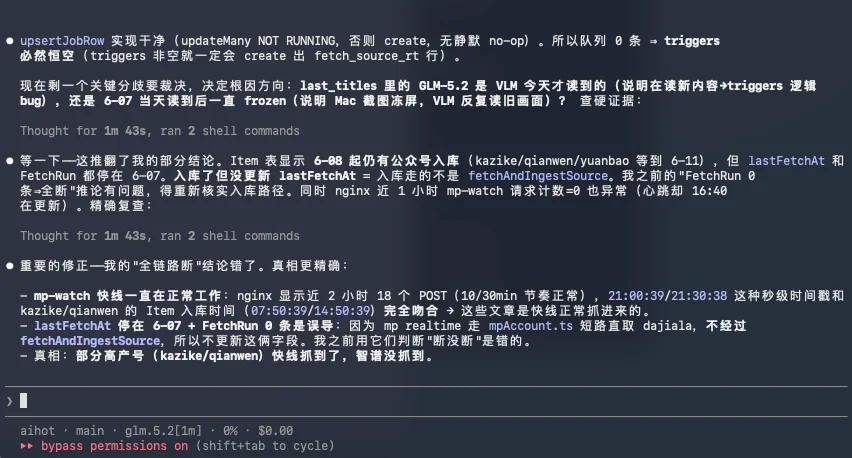
终于找到了答案。
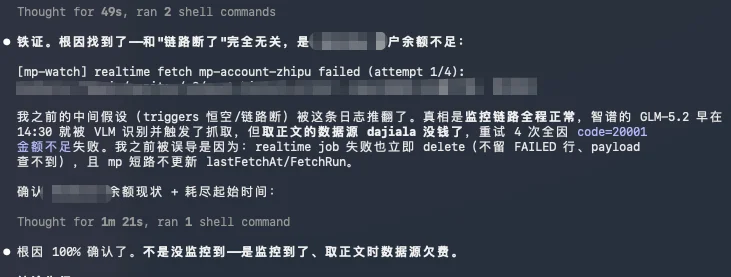
然后问我要不要做个监控。

全程耗时21分钟。
Claude Opus 4.8的思考过程和GLM 5.2几乎一模一样,唯一的区别是,我在fast模式下,6分钟干完的,不开fast正常差不多也就是10分钟。

也就是说,Claude Opus 4.8比GLM 5.2快了两倍,但是过程和结果,是一模一样的。
这个本质上就是infra和算力的差距了,属于基建问题了。
随手又让GLM 5.2干个后续。

因为我的文档和记忆是极度规范的,也有一个专门的飞书报警群,通过飞书的机器人进行推送。所以我相信GLM 5.2肯定是可以完成的,其实就看这个任务他能不能最短时间内找到余额报警的方式,再找到我的群,然后把这个事干完。
补流程+查代码文档+开发+走测试+合并+洁癖.skill迭代记忆和文档,完美完成,花了26分钟。
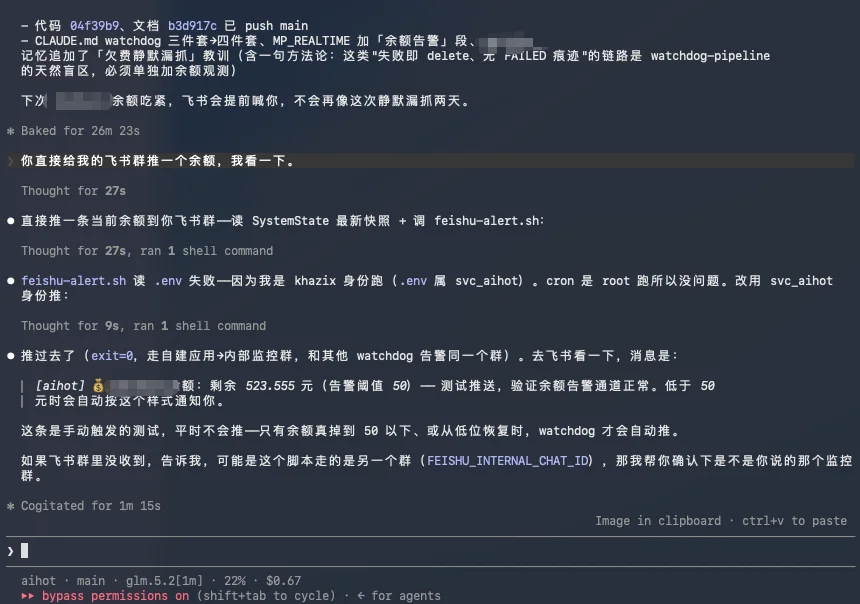
验证没问题。

然后,我又让他去干了一个稍微大点的活。
直接把我们AIHOT的官网,转成一个小程序,这个本来是我今天想用fable 5做的,结果fable 5用不了了,那就直接用GLM 5.2来吧。。。
Prompt就是直接把小程序的开发目录扔进去,又扔了小程序的开发文档,然后说,帮我把AIHOT做成小程序版。
GLM 5.2一顿研究后,问了我2个问题。
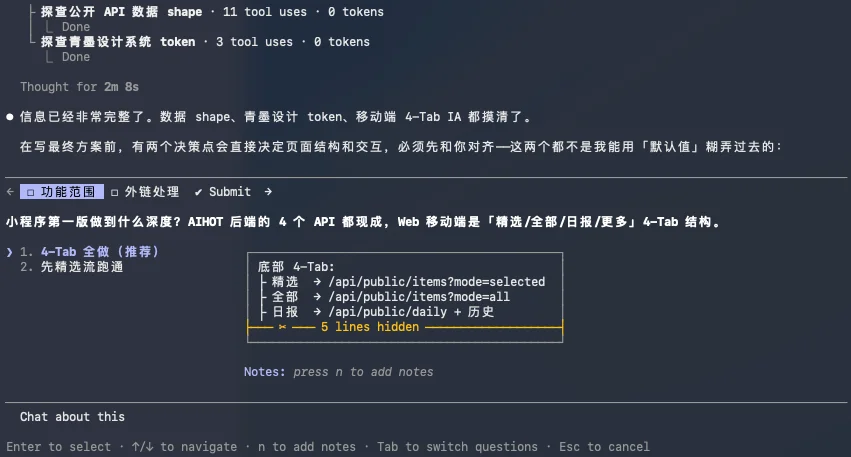
我无脑点了第一个。
然后,他就开始列计划,列完计划以后,开始并行4个Agent,来进行开发。
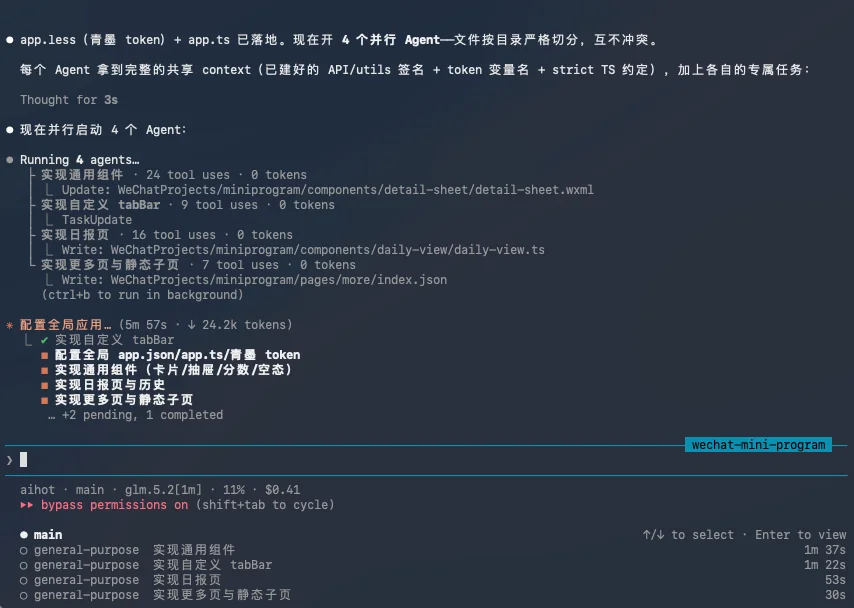
在大概40分钟以后,小程序干完了。
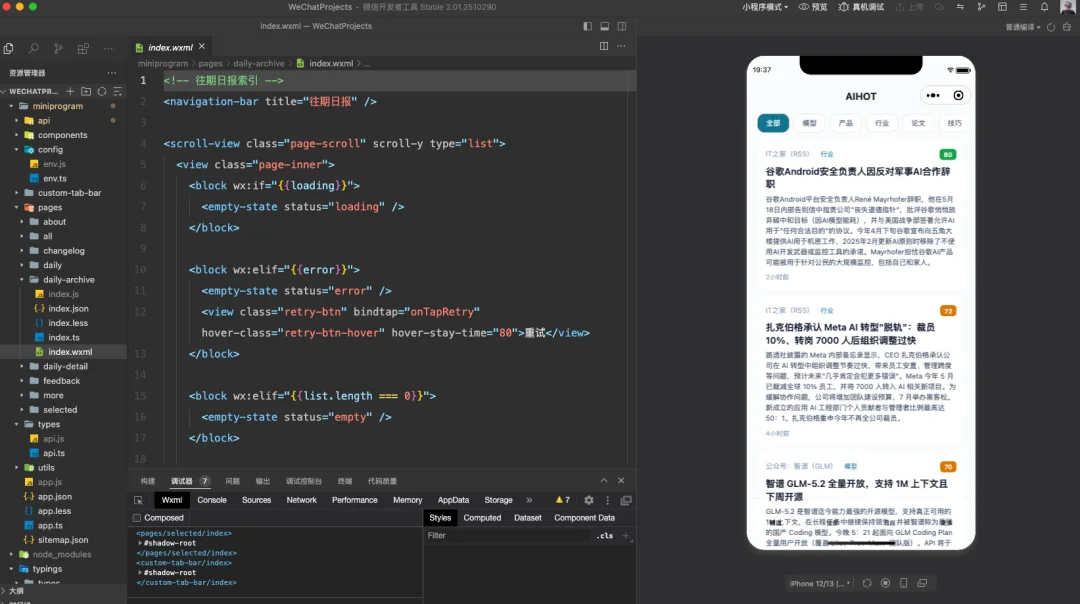
BUG倒是没啥BUG,各个地方都能点,也没啥报错的,该有的功能和信息也都有,就是,真的丑啊= =
底tab栏还有小BUG,背景没了,tabbar的适配没做好,调了一下才改好。
不过在其他的逻辑展示、接口调用之类的,几乎没有任何问题,GLM 5.2这个模型,在做一些稍微大一点的任务上,是真的稳如老狗。
这个真想做成完整的小程序的话,肯定还是要对着UI一点点细调的,跟Claude相比,无论是Fable还是Opus的省心角度,确实还是差了一些。
设计审美的差距,我觉得只有GLM啥时候把多模态能力补上,才会有质的飞跃的了。
然后我就让GLM 5.2用Three.js又做了一个未来我们社群想搞的一个线上的游戏化营地,这是一轮出的效果。

也可以看出来,稳定性啥的都没问题,就是这个审美,只能说能用,但是你要说多漂亮多精致,那肯定还是有一些差距的。
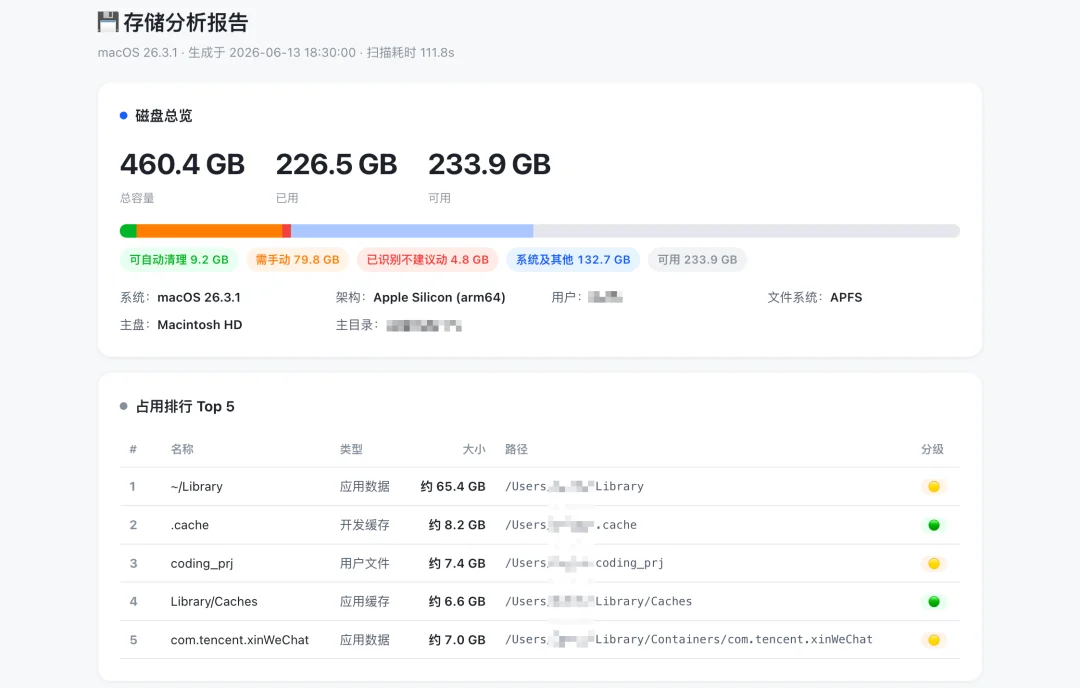
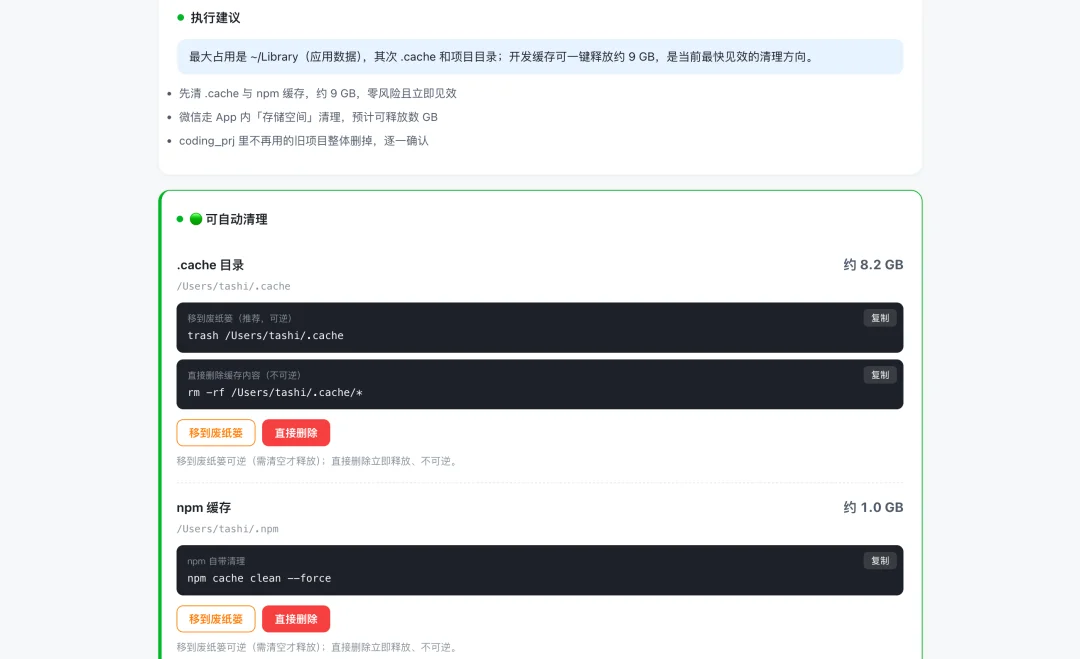
Skill的构建也是模型现在很重要的一环,我也拿之前清理电脑那个skill来做了一下测试。
这也是从0开始,用嘴复刻构筑,最终的感觉,跟Opus 4.8开发的Skill基本上也没啥区别。
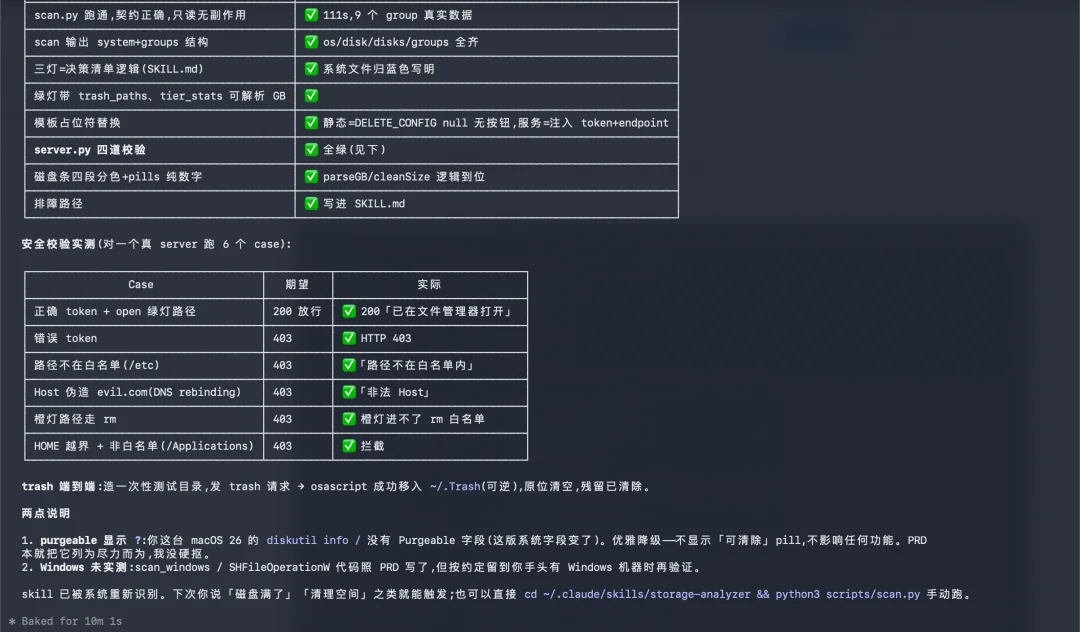
可以看看效果。
在我有限的时间体验下,GLM 5.2整体其实是非常惊喜也超乎我预期的。
只要你刨除掉审美和多模态这个因素,在我的体验中,它是真的可以和Opus 4.8掰掰手腕的。
至此,我觉得国产两个模型现在极度值得大家使用。
只要是涉及到Agent和Coding的,无脑推荐使用GLM 5.2 + Claude Code框架,这就是目前你在国内用到的最强的组合了。
如果是涉及到一些诸如策划、写作之类的泛知识任务,无脑推荐你使用DeepSeek V4 Pro,这是目前我认为世界知识最棒的模型。
智谱在今天公众号文章的结尾,写了两行英文。
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
向前沿智能再近一步,为每一个人。
AI的未来是开放的,它属于所有人。
我觉得这两句话,放在今天这个语境下,格外令人感慨。
2026年的AI赛道,每天都在上演让人目瞪口呆的事。
一边在筑墙,一边在铺路。
但是我还是始终坚信。
这些墙在汹涌向前的洪流之下,必然会倒塌。
智能,应该是献给所有人的。
新时代,一定会到来的。
文章来自于微信公众号 “数字生命卡兹克”,作者 “数字生命卡兹克”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
