# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近,我们都在关注旗舰级大模型的进步,其实本地运行的 AI 模型也迎来了重要的分水岭。
在可行性和实用性方面,很多新模型已经实现了性能的跨越,不论智力、智能体(Agent)能力还是工具链成熟度,在最近半年里都有巨大的提升。
看起来已经能做到「点两下就能跑」了。
本文作者 Vicki Boykis 是一家创业公司的创始机器学习工程师,主要从事推荐系统 / 个性化 / 信息检索方面的工作。
此前,她曾在 Mozilla.ai 从事 LLM 和 LLM 基础设施方面的工作,也曾在 Duo、Tumblr、Automattic 和 Comcast 从事机器学习和推荐系统方面的工作。
她最近发表的博客文章,在 HackerNews 上成了爆款:

我从本地模型刚推出时就开始和它们合作,现在它们已经做得出乎意料地好了。
我有一台 2022 年款 M2 Mac,配备 64 GB 内存和 1TB 存储空间。基于这样的硬件,我一直都在使用:
在许多不同的系统设置中,例如:
在大模型兴起后,本地模型运行缓慢、难以使用是常态,而且对于大多数编程任务来说准确率不高。本地模型严重落后的观点在很大程度上是正确的,直到 2025 年 8 月 OpenAI GPT-OSS 的发布才让我们改变了这种看法。我没有确凿的科学证据 —— 我个人判断一个模型是否足够好的标准是「我是否需要将其与 API 模型进行比对」,而 GPT-OSS 是我第一个开始大幅减少这种比对次数的模型。
因此,我主要使用本地模型作为快速、个性化的谷歌,来解答不需要时效性的开发问题。
但是随着谷歌最新发布的 Gemma 4 系列产品,我终于能够在本地进行智能体编码,并且循环的准确率 / 速度达到了前沿模型的 75% 左右,这真是令人难以置信。
目前为止,我一直使用 gemma-4-26b-a4b LM Studio 实现作为我的默认本地模型。到目前为止,我使用本地设置完成了以下工作:将一个 Python 脚本(原本是一个 notebook)重构为一个包含 5-6 个模块的仓库,并对该模块进行代码检查,以确保泛型使用正确的类型提示(现在大多数前沿模型都会自动执行此操作,但并非总是如此)。

我还用它来校对一些博客文章、编写单元测试,以及搭建一个基于双塔模型的推荐系统仓库,看看智能体在空白环境下会如何运作。以下是它生成的内容,虽然非常基础,但仍然远远超出了我去年所能想象的范围:


请注意,由于我将所有智能体工作流运行在具有有限执行权限的 Docker 容器中,因此环境受到限制。
我还在开发一款应用,用于筛选 arXiv 论文中的热门话题。出于好奇,我让 Pi 查看了我之前的 LM Studio 会话日志,想弄清楚我使用 LM Studio 的目的是什么:
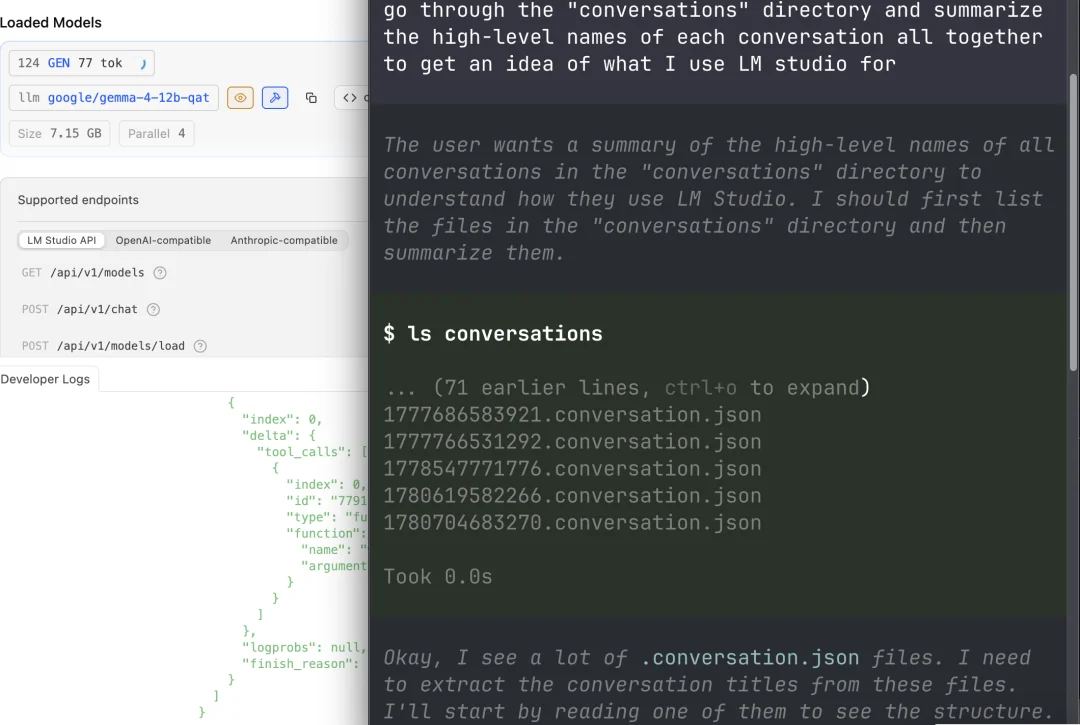

不出所料,自从我开始参与 Rijksearch 项目以来,

这些任务都不是什么突破性的任务(再次强调,都是大量的个性化 Google / 文档查找),但处理这些任务确实让我的 GPU 和 RAM 得到了充分的使用,KV 缓存增长到了 64 GB RAM。
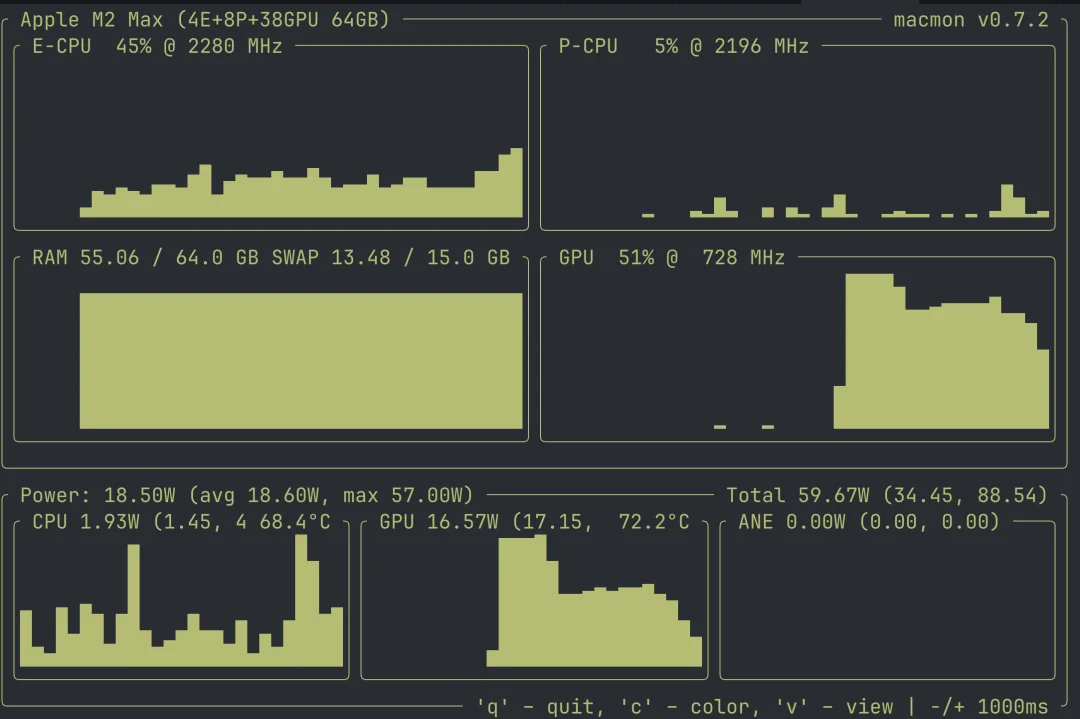
但对我来说,更重要的一点是,就在 6 个月前,这类任务即使再简单,对于本地模型来说也是不可能完成的。
Gemma-4-12b-qat 虽然刚发布不久,但其性能与规模相比已经给我留下了深刻的印象。模型架构本身就非常有趣,并提出了一系列引人深思的问题,例如「如果我们受到性能和价格的限制,我们需要在架构上做出哪些权衡?」—— 这个问题在目前疯狂的 token 淘金热潮中还没有真正被提出过。
但别光听说,自己动手试试吧!如果你想运行本地智能体流程,你需要一个本地模型推理引擎、一个智能体框架以及本地模型工件。你需要配置智能体框架,使其指向你的本地推理端点,也就是通过推理引擎提供的已下载模型工件。
就我的本地设置而言,我目前使用 Pi 作为智能体框架,LM Studio 作为推理服务器,尽管如果我直接使用 llama.cpp 可能会更快 —— 这是未来实验的一个潜在方向。
这篇文章(https://patloeber.com/gemma-4-pi-agent/)很容易理解,它指导我们如何用 Pi 和 LM Studio 设置智能体编码,虽然我对文章中的设置做了一些调整。
1、模型:该文章推荐 Gemma 26B A4B,但 gemma-4-12b-qat 更新、更小、更快,而且准确性没有太大损失。
2、安全性:我将所有 Pi 会话都运行在 Docker 容器中,并只授予其 bash 权限,这样它就无法运行 Python 代码或进行网页浏览,尽管我计划在另一个镜像中允许 curl 用于我正在进行的一些研究工作。
3、智能体配置:由于我所有程序都在 Docker 中运行,所以我编辑了 Pi 的配置 models.json,以便让 Pi 与模型通信。
"lmstudio":{"baseUrl":"http://host.docker.internal:1234/v1",
"api":"openai-completions",
"apiKey":"not-needed",
"models":[{"id":"google/gemma-4-12b-qat",
"input":["text",
"image"]}]}
这是我的 Docker Compose 配置:
services:
pi:
build:
context: .
dockerfile:Dockerfile
image: pi-agent:0.74.0
init:true
stdin_open:true
tty:true
extra_hosts:
- "host.docker.internal:host-gateway"environment:
ANTHROPIC_API_KEY: ${ANTHROPIC_API_KEY:-} OPENAI_API_KEY: ${OPENAI_API_KEY:-not-needed} GEMINI_API_KEY: ${GEMINI_API_KEY:-} OPENAI_API_BASE: ${OPENAI_API_BASE:-http://host.docker.internal:1234/v1} # note that you'll need to specify a base if you also use OpenAI to access OpenAI's actual completions endpoint WHATEVER_API_KEY: ${WHATEVER_API_KEY:-} volumes:
- ${HOME}/.pi/agent/models.json:/config/models.json
- ${WORKSPACE:-.}:/workspace
- pi-config:/config
- pi-sessions:/sessions
working_dir: /workspace
volumes:
pi-config:
pi-sessions:
这是运行的 bash 脚本 pi。
#!/usr/bin/env bash
# Pi — Start the containerized Pi agent.
# Directory containing this script and the compose files.SCRIPT_DIR="$(cd -- "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
# Workspace to mount into the container. WORKSPACE_DIR="${WORKSPACE:-$(pwd)}"case "$WORKSPACE_DIR" in
/*) ;;
*) WORKSPACE_DIR="$(cd -- "$WORKSPACE_DIR" && pwd)" ;;
esacexport WORKSPACE="$WORKSPACE_DIR"
sandbox="${PI_SANDBOX:-0}"pi_args=()
while (($#)); docase"$1"in
--sandbox) sandbox=1 ;;
--no-sandbox) sandbox=0 ;;
*) pi_args+=("$1") ;;
esacshift
done
compose_files=( -f "$SCRIPT_DIR/docker-compose.yml" )if [[ "$sandbox" == "1" ]]; then# an even more secure sandbox compose_files+=( -f "$SCRIPT_DIR/docker-compose.sandbox.yml" )fi
# Derive a container name from the workspace directory's basename.# Sanitize to characters Docker accepts: [a-zA-Z0-9][a-zA-Z0-9_.-]*repo_slug="$(basename -- "$WORKSPACE_DIR" | tr -c 'a-zA-Z0-9_.-' '-' | sed 's/^-*//')"[[ -z "$repo_slug" ]] && repo_slug="workspace"container_name="pi-${repo_slug}-$$"
api_key_args=( -e OPENAI_API_KEY
-e DEEPSEEK_API_KEY
-e ANTHROPIC_API_KEY
-e GEMINI_API_KEY
)
cmd=( docker compose
--project-directory "$SCRIPT_DIR""${compose_files[@]}" run --rm
--name "$container_name""${api_key_args[@]}" pi
)
if ((${#pi_args[@]})); then cmd+=("${pi_args[@]}")fi
exec"${cmd[@]}"
我构建了 Docker 容器,并修改了它自身仓库中的文件。然后,我在我正在编辑的仓库中运行 Pi,这样 Pi 就会启动 Docker,从而避免因直接操作我的物理硬盘而擦除文件或目录。此外,json 通过将自定义模型配置传输到容器中,运行在容器中的 Pi 也能够访问这些配置。所有这些在我的实验中都运行良好。
本地模型仍然存在一些问题:推理速度可能较慢,上下文窗口较小且受限于你自己的硬件和生态系统,尽管像 LM Studio 和 HuggingFace 的「使用此模型」按钮之类的工具已经大大简化了相关工作。早期版本存在提示模板不匹配的问题。不过,这些问题通常都能很快得到修复。毋庸置疑,我不确定它是否已经完全准备好用于生产软件开发。
不过,其优势众多,而且该生态系统至关重要,值得投资,尤其是在当下。本地化模式最吸引人的地方之一在于,你可以深入了解几乎所有方面,例如实时观察 token 推断过程。
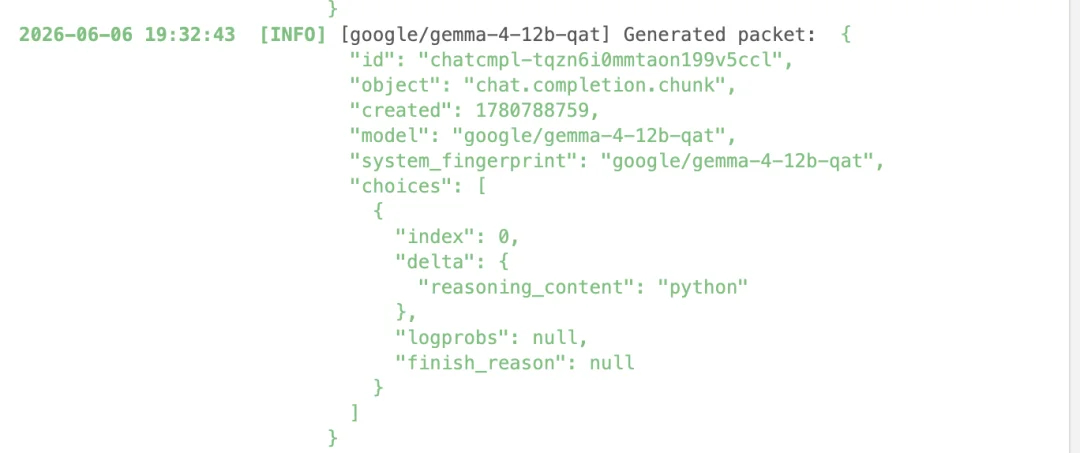
并观察 token 的流入 / 流出。
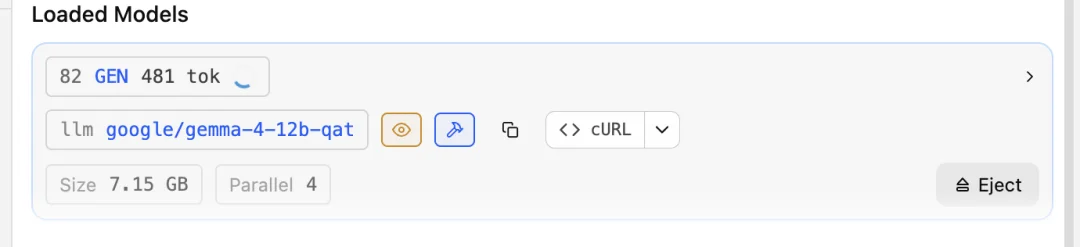
你可以进行诸如更改本地上下文窗口、观察性能提升或下降等操作,并深入了解 GPU 如何处理令牌。你可以更改系统提示符和量化设置。你可以对比不同的模型。你还可以更改和分析测试框架。
可能性无穷无尽,工具也只会越来越好。
参考内容:
https://vickiboykis.com/2026/06/15/running-local-models-is-good-now/
文章来自于"机器之心",作者 "机器之心编译"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
