# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Anthropic 在 6 月 30 日发布了 Claude Science。
原文链接:https://www.anthropic.com/news/claude-science-ai-workbench

如果只看发布稿,这很容易被理解成“Claude 又加了一套科研插件”。但我看完之后,感觉它想做的事情比插件更重一点:它不是只帮你读论文、写代码、画图,而是想把文献、数据库、代码环境、计算资源、图表、手稿和结果审查放进一个连续的科研工作台里。
这件事对生信人很有吸引力。
因为我们日常工作里,真正消耗时间的往往不是某一个算法,而是流程太碎。文献在 PubMed,数据在 SRA、GEO、Ensembl、UniProt,分析在 Jupyter、R、命令行和服务器之间切换,稍微上点规模还要碰 SLURM、conda、scratch、路径、权限和日志。
Anthropic 给 Claude Science 的定位,就是面向科学家的 AI workbench。它宣称可以调用 60 多种科研 skills 和 connectors,覆盖基因组学、单细胞、蛋白质组学、结构生物学、化学信息学等方向;还能在本地、远程 SSH、HPC 登录节点上工作,必要时接入计算资源;输出的图表、代码、环境和消息历史也会保留,方便审计和复现。
这些说法听起来都很对。
但问题是,科研工具不能只看发布稿。尤其是生信工具,demo 里跑得很顺,不代表换到自己的服务器、自己的目录、自己的调度系统上还能顺。
所以我这次没有让 Claude Science 总结论文,也没有让它写一段脚本。
我给它做了一个更接近生信日常的实战测试:连接一台远程服务器,摸清环境,补齐缺失软件,提交 SLURM 作业,下载公开 RNA-seq 数据,建立 Salmon 索引,跑两个酵母样本的转录本定量,最后把结果取回来。
这件事不复杂,但很真实。
因为生信里很多工作不是“写一段代码”这么简单,而是卡在一堆杂事上:服务器有没有 conda?有没有 sra-tools?能不能联网?salmon 装没装?作业往哪个分区投?scratch 目录在哪里?大文件要不要拉回本地?这些问题单看都不难,但每次换环境都要重新确认。
所以我想试的不是 Claude Science 会不会写命令,而是它能不能像一个真正干活的人一样,把一件远程分析任务推进到完成。
结论先说:这次它跑通了。
但真正让我觉得有意思的,不是它成功跑出了结果,而是它在中间遇到配置问题时,知道先停下来,而不是硬投一个必然失败的作业。
热点归热点,我给它安排了一个真任务
在真正开跑之前,还有一个很关键的问题:Claude Science 到底在哪里跑这些分析?
它不是把所有东西都塞进本地聊天窗口里硬跑。我的理解是,它会先判断“这活儿应该落在哪个算力环境上”。
本地沙箱资源是有限的,当前只有 8 CPU、8 GiB 内存、没有 GPU。对于一些轻量步骤,比如解析表格、整理结果、画图、跑下游统计,本地可以处理。但生信里很多步骤不适合硬扛,比如下载 SRA、解压 FASTQ、建 Salmon 索引、跑比对或定量、处理大矩阵,这些任务动不动就超过本地内存或耗时很长。
所以我这次先在 Compute 面板里配置了一台远程主机,也就是后面提到的 99。
Claude Science 的运行方式大概是这样:先用 list_compute
看当前有哪些远程算力,再用 compute_details
读取这台机器的提交方式、调度系统和资源信息。如果没有远程算力,它会提示这类任务容易在本地 OOM,建议先加一台远程主机。等我把 99 配好之后,它再重新检查,并把重活投到远程服务器上。
远程作业是提交后不阻塞的模式。它把脚本和输入送到服务器,作业在 SLURM 上跑,几分钟到几小时都可以;完成后再把结果、日志和小文件回收到当前工作区。原始 FASTQ、SRA、索引这些大文件则尽量留在远程 scratch,不来回搬。
这点对生信很重要。
如果一个 AI 工具只能在本地小沙箱里跑,那它最多适合 demo。要真的处理生信数据,它必须知道什么时候该把计算派到服务器,什么时候只把结果拿回来。
于是我让 Claude Science 在一台叫 99 的远程服务器上跑一个小型 RNA-seq 冒烟测试。
任务目标很明确:
我没有提前告诉它服务器环境是什么,也没有手动帮它准备 salmon。
这点很重要。因为我不是在测试“Claude Science 能不能运行一段我已经准备好的流程”,而是在测试它能不能先理解环境,再决定怎么跑。
第一步:它没有急着投作业,而是先摸环境
Claude Science 一开始做的事情比较像一个靠谱的生信同事。
它没有直接写脚本投作业,而是先确认 99 的计算环境:
这个顺序是对的。
如果一上来就写 Salmon 流程,很容易投上去才发现环境不完整。尤其是远程服务器和集群环境,失败往往不是算法问题,而是路径、环境、权限、调度器、网络这些外围问题。
它发现 salmon 没装之后,没有把这个问题留到作业里临时处理,而是先建了一个专用 conda 环境:
/home/*/miniconda3/envs/salmon_env
里面装了 Salmon 1.10。
这一步我觉得比“会写 salmon quant 命令”更重要。因为真实工作里,能不能把环境准备和作业执行分开,决定了后面流程是否稳定。
第二步:它自己选了适合冒烟测试的数据
Claude Science 没有随便找一个大数据集开跑,而是选了两个比较小的酿酒酵母 RNA-seq 样本:
这个选择也合理。
酿酒酵母转录组小,Salmon 索引很快,样本数据量也不会太夸张,适合用来测试整条链路是否跑通。对于第一次连接一台新服务器,我更希望它先跑一个小而完整的任务,而不是一上来就上人类单细胞或大规模队列。
这也是我对 AI 跑科研任务的一个基本要求:它不只是要会执行,还要知道任务规模和测试目的匹配。
这次的目的不是发表结果,而是验证 Claude Science 能不能打通远程生信作业链路。选酵母小样本,是一个稳妥选择。
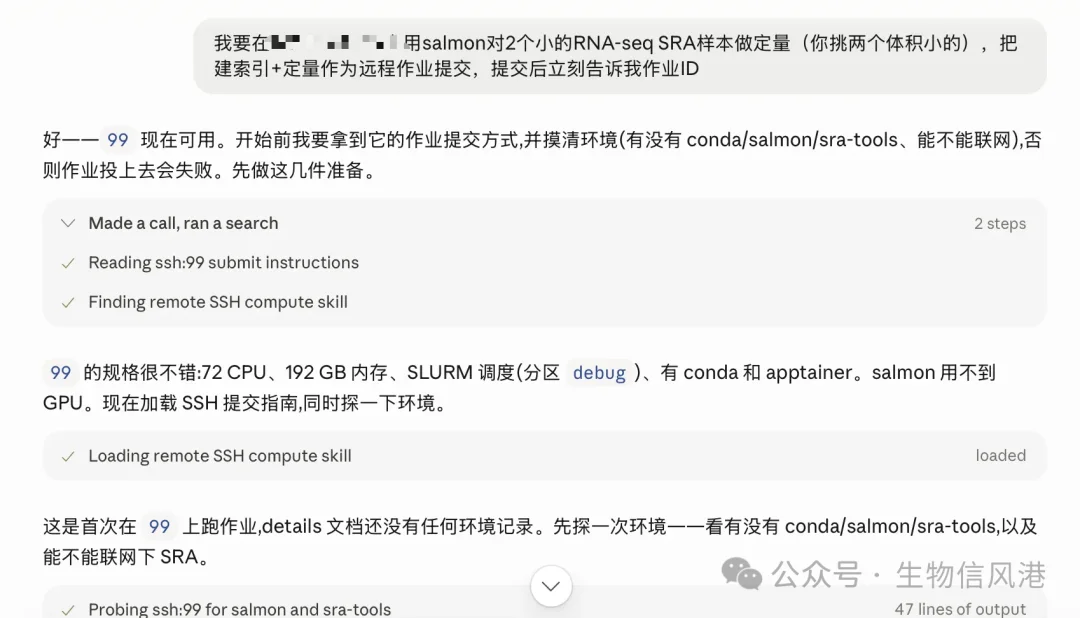
第三个细节:scratch_root 卡住了
这次实战里最有价值的细节,反而不是成功的部分,而是失败的部分。
Claude Science 写好作业后,准备提交到 99,但提交前卡住了:主机配置里没有登记
scratch_root。
简单说,就是它不知道远程作业工作目录应该放在哪里。
它先在 99 上建了一个目录:
/home/*/cs_scratch
然后尝试通过提交参数绑定 scratch 目录。但连续两次发现 submit 并没有读取这个配置,问题仍然卡在主机注册级别。
这时候它没有继续盲试第三次,而是停下来告诉我:
scratch_root
是主机注册级设置,不是作业提交参数;它编辑的 details 备注文档只是给下次会话看的说明,不是实时主机配置;需要我在面板里把 scratch_root 配好。
这个细节很关键。
如果是普通聊天助手,很可能会继续改脚本、换参数、重新投,最后制造一堆看起来很努力但没有意义的失败。Claude Science 这次的表现更像一个知道边界的执行者:它能判断“这个问题不是脚本层能解决的,需要用户去改主机配置”。
于是我帮它在面板里补好 scratch_root 之后,它重新提交,作业成功进入队列。
这一步让我对它的定位更清楚了:它不是一个完全自动驾驶的科研系统,但它已经能承担大量“工程推进”的工作,并且在权限和配置边界处把人叫回来。
作业实际跑了什么
最终提交的作业 ID 是:
9eabb346-d7cd-4942-a51f-7a098baa4d61
运行环境:
作业做了三件事:
第一,下载酵母 cDNA 参考转录组,来源是 Ensembl release-110,对应 R64-1-1。
第二,用prefetch和fasterq-dump下载两个 SRA 样本,并转成双端 FASTQ。
第三,使用 Salmon 建索引,然后分别对两个样本做 quant。

所有计算都在服务器上完成。大文件,比如 SRA、FASTQ、索引,都留在远程服务器上;本地只回收 quant.sf、运行日志和汇总结果。
这个设计很实用。
很多时候我们不希望把几 GB、几十 GB 的中间文件全部拉回本地。真正需要带回来的往往只是聚合结果、日志和可复查的表格。Claude Science 这次的文件回收策略是合理的:重活留远程,轻结果取回来。
中间也不是一帆风顺
作业刚提交时,Claude Science 预计 10 到 15 分钟完成。
实际跑了 25 分钟还没结束。
它没有只是说“还在运行”,而是去查了实际进度。结果发现:
这又是一个很真实的生信细节。

很多流程慢,不是因为计算慢,而是因为远端下载慢。SRA 下载速度波动很常见。能定位到“当前瓶颈在第二个样本 prefetch”,比泛泛地告诉你“作业仍在运行”有用得多。
后面作业成功完成,exit 0。
结果是否合理
最终 Claude Science 取回了两份 quant.sf 和 Salmon 日志,并汇总了结果。
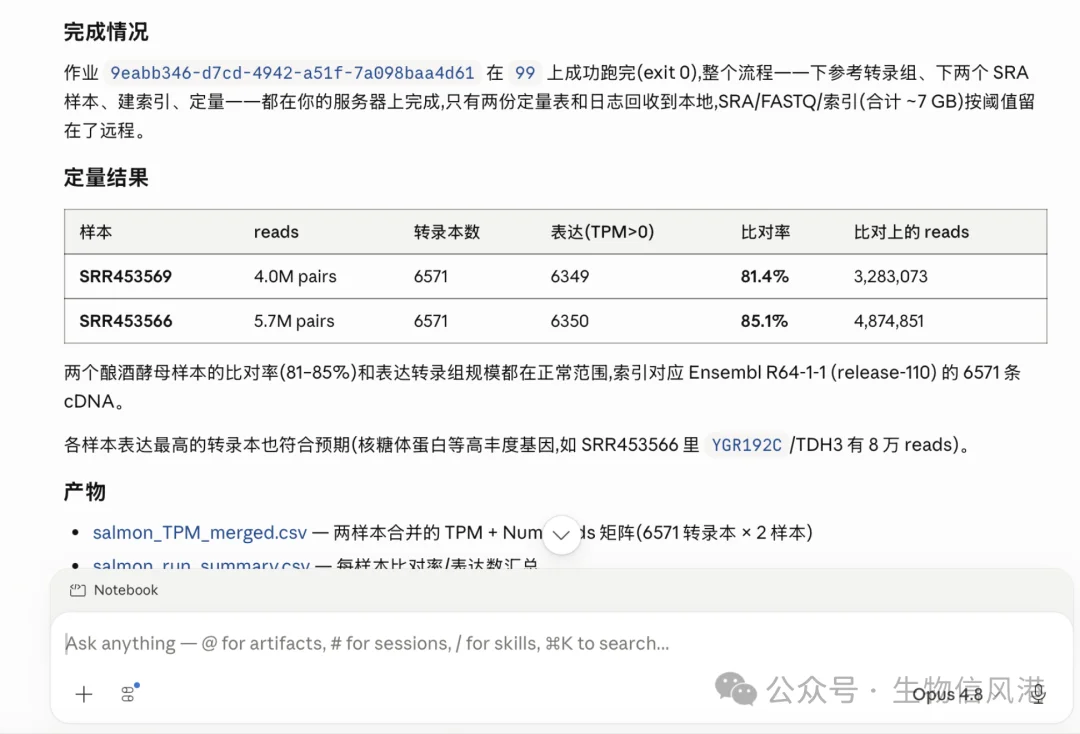
这个结果看起来是合理的。
酵母参考转录组 6571 条 cDNA,两个样本 TPM>0 的转录本都在 6350 左右,比对率 81% 到 85%。它还检查了高表达转录本,看到核糖体蛋白、TDH3 这类高丰度基因,符合常识。
这一步不能说是很深入的生物学分析,但作为一次冒烟测试足够了。
我关心的不是这两个酵母样本有什么新发现,而是 Claude Science 能不能完成从远程环境检查到结果合理性判断的闭环。至少这一次,它做到了。
产物也整理得比较清楚
本地取回的 artifact、远程服务器保留的文件以及关键资产都列举的很清晰:

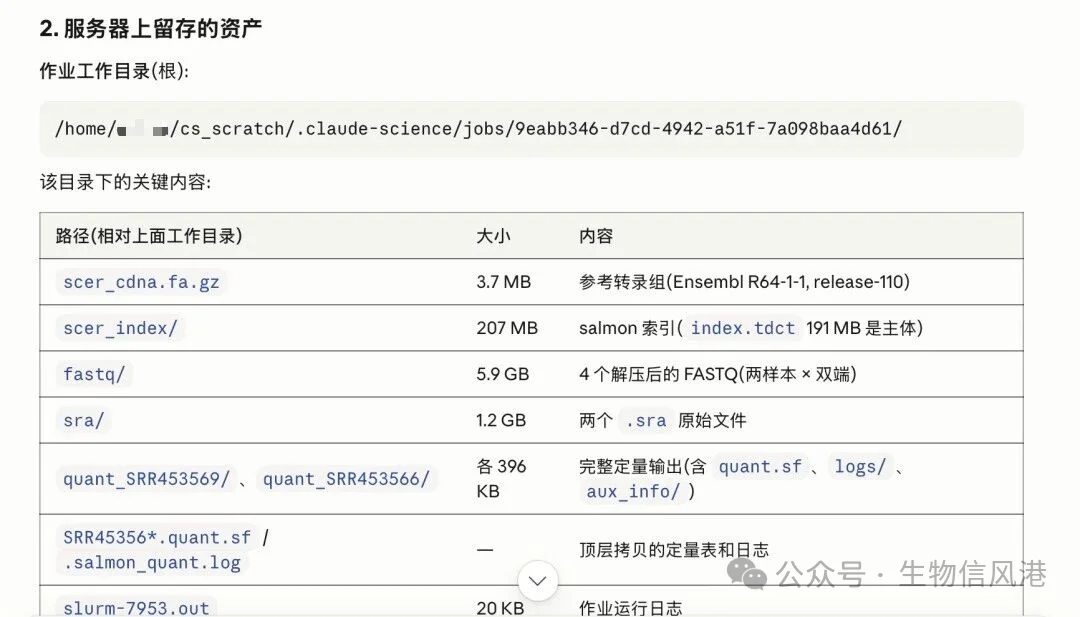
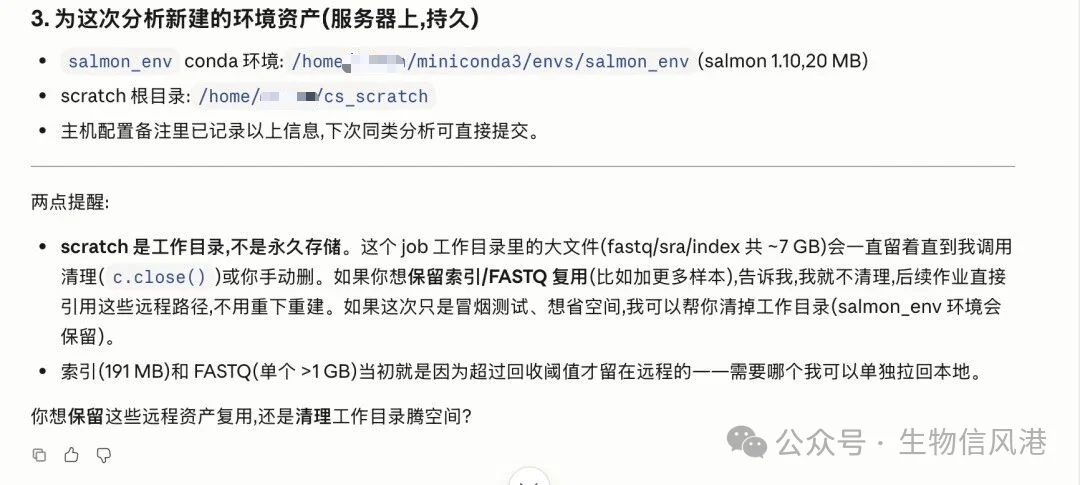
它还提醒我:scratch 是工作目录,不是永久存储;如果后面要加更多样本,可以保留索引和 FASTQ 复用;如果只是冒烟测试,可以清理工作目录腾空间。
这个提醒很像真实生信工作里的收尾动作。
很多 AI 工具能帮你生成结果,但不会提醒你远程文件到底在哪里、哪些可以复用、哪些该清理。Claude Science 这次把资产分成“本地 artifact”“远程留存文件”“服务器环境资产”三层,我觉得这个整理方式很适合团队协作。
我觉得它最有价值的地方
这次实战下来,我觉得 Claude Science 最有价值的地方不是写代码。
Salmon 定量的命令本身并不难。很多生信人都能写:
salmon index
salmon quant
真正麻烦的是把这件事放到一台陌生服务器上,并且从头到尾跑完。
它做了几类我平时很不想重复做的工作:
这些工作没有哪个特别高深,但每一个都真实存在。
如果一个 AI 工具只能帮我写脚本,它只是一个代码助手。如果它能把这些上下游杂事一起处理掉,它才开始接近“科研工作台”。
这也是 Claude Science 和普通聊天助手最大的区别。
它还不能替代什么
这里要说谨慎一点。
这次测试成功,只能说明 Claude Science 在我的这个任务里,打通了远程服务器环境检查、软件安装、SLURM 提交、SRA 下载、Salmon 定量、结果回收和资产整理这一条链路。
它不能直接外推成“Claude Science 已经能接管所有组学分析”。
不是说它做不到,而是我这次还没有测试到。
这次任务本质上是一个 RNA-seq 定量冒烟测试。任务边界很清楚:两个酵母样本、一个参考转录组、一个 Salmon 定量流程。它更像是在验证“能不能把远程生信作业跑通”,而不是验证“能不能完成一个完整组学研究”。
后面至少还有几类能力需要继续测:
第一,多样本统计分析。
这次只有两个样本,没有真正进入差异表达的统计检验,也没有处理分组、批次、重复数、离群样本这些问题。下一步如果要测试完整 RNA-seq 分析,就应该让它从 sample metadata 开始,完成 Salmon 定量、tximport、DESeq2、PCA、相关性热图、MA plot、火山图和差异基因表。
第二,生物学解释能力。
这次它判断比对率 81% 到 85% 合理,也检查了高表达转录本是否符合酵母 RNA-seq 常识。但这还不等于它能可靠解释复杂生物学问题。比如换成环境胁迫、肿瘤队列、单细胞亚群或多组学整合,它能不能把差异基因、通路、文献和数据库证据串起来,还需要专门测试。
第三,复杂数据和复杂环境。
这次数据规模不大,物种也简单。后面如果换成人类 bulk RNA-seq、单细胞矩阵、空间转录组、蛋白组或多组学,数据量、环境依赖和中间文件都会复杂很多。它能不能稳定处理更大的数据、更多样本和更长流程,还不能从这次结果里直接推出。
第四,人工介入边界。
scratch_root 这次就是例子。它能识别问题,也能指出应该怎么改,但最终面板配置还是需要我来完成。这不是坏事,反而说明这种系统更适合人机协作,而不是完全无人值守。
第五,可复查和可复现。
我愿意继续用它的前提,是它能留下脚本、日志、路径、参数、环境和产物。没有这些,AI 跑出来的结果再快,也不适合进入严肃分析。这次它在这方面表现不错,但后面流程变长以后,还要继续看它能不能把证据链保持住。
所以这一节不是给 Claude Science 下结论,而是给这次测试划边界。
第一期我只能说:它把一个真实远程 RNA-seq 定量作业跑通了。
但这个“只能说”,其实已经不低了。
因为它不是在一个准备好的 notebook 里运行几行命令,而是在一台真实服务器上完成了环境探测、依赖安装、scratch 配置排查、SLURM 投递、下载进度跟踪、结果回收和资产整理。这里面任何一步出问题,普通 AI 聊天助手都很容易停在“给你一段建议”。
Claude Science 这次至少证明了一点:它已经不只是能告诉我怎么做,而是能在一定边界内替我把事情推进下去。
至于它能不能从文献问题出发,选择数据集,跑完整差异表达,再把结果解释成一个可审查的小型组学分析,这是下一期要测的内容。
这次测试给我的判断
Claude Science 这次让我看到的,不是一个“更会聊天的 Claude”,而是一个能接入真实计算环境的科研执行层。
它的价值不在于替代生信人,而在于替你处理那些重复、琐碎、但必须认真做的流程工作。这个能力如果稳定下来,对生信人是很有吸引力的。
如果你每天只是让 AI 改几段代码,Claude Science 可能显得有点重。
但如果你的工作经常涉及远程服务器、SLURM、conda 环境、公共数据库下载、分析流程追踪、结果回收和团队复用,那它的意义就不一样了。
不是因为这次 Salmon 定量有多难,而是因为它证明了一件事:AI 工具开始能从“给建议”走向“接作业”。它不只是告诉我该怎么做,而是真的在服务器上把任务跑完,并且把中间资产整理清楚。
这对生信人来说,是一个很重要的变化。
过去我们说 AI for Science,很多时候还停留在“模型能不能解决科学问题”。但这次测试让我觉得,另一个同样重要的方向是:AI 能不能把科研里的工程杂活组织起来。
生信工作本来就站在科学问题、数据资源、计算环境和软件流程的交叉点上。谁能把这些碎片连接起来,谁就能真正改变工作效率。
Claude Science 现在还只是 beta,也肯定还有很多边界需要测试。
但至少这一次,它不是在 demo 里看起来有用,而是在一台真实服务器上,把一次 RNA-seq 定量作业跑完了。
这已经足够让我认真关注它的下一步。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
文章来自于微信公众号 “生物信风港”,作者 “生物信风港”


