# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天想和大家分享一种业务建模方法:Agent Ontology,Agent 本体论
Ontology 是我在研究 Palantir 时不断出现的一个词,仔细研究后觉得很有必要单独拿出来,和大家分享。

首先,Ontology 不是单纯的方法论,也不是单独一个工具。
Ontology 是一种业务建模方法,落地后会变成一套企业语义层/业务对象层,最后可能被包装成平台或工具。
也就是说,Ontology 本质上是一套让 AI Agent 看懂企业业务、并按企业规则办事的建模方法。
简单来说,Agent Ontology,就是给 AI Agent 建一张企业里的业务地图。
有了这张地图,AI Agent 才知道:
企业里有哪些对象,这些对象之间是什么关系,哪些动作能做,哪些动作不能做,哪些动作必须让人审批,做完以后要写回哪个系统。
这也就是为什么 Palantir、Databricks、Skan AI 这些 AI 巨头现在都在讲 Ontology。
先举个供应链的例子。
用户问 Agent:“为什么这个客户的订单还没发?”
没有 Ontology,AI 可能只能去查几份表,然后回答:
“订单可能因为库存不足或物流延迟导致未发货,建议联系仓库确认。”
这就是泛泛而谈。
有 Ontology 后,它看到的不是一句“订单没发”,而是一串业务对象和关系:
这时候,实际业务问题的处理就不是 AI 在凭空推理,而是 Agent 沿着企业预先定义好的对象、关系、状态和动作去排查。
如果说大模型是 Agent 的大脑,工具是 Agent 的手脚,那 Ontology 就是 Agent 对企业业务的理解方式。
它告诉 Agent:你面对的是什么对象,这些对象之间怎么关联,哪些动作可以做,哪些动作不能做,做完以后会影响什么。
传统做 AI,很多人是先把大模型接进来,再让它回答问题、调用工具。
Ontology 的思路相反:
先把企业里的关键对象定义清楚。
比如客户、订单、库存、仓库、合同、工单、供应商、产线、审批人。
再把它们之间的关系定义清楚。
比如订单属于哪个客户,订单占用哪些库存,库存在哪个仓库,仓库服务哪些区域,订单延误会影响哪个交付承诺。
再把动作和规则定义清楚。
比如哪些订单可以改地址,哪些退款必须人工审批,哪些库存可以自动调拨,哪些操作要写回 ERP、OMS、WMS 或 TMS。
所以从理念上说,Ontology 解决的是:
不要让 AI 直接面对一堆零散系统,而是先给它一套能理解企业业务的结构。
这就是 Agent Ontology 的意义。
它让 Agent 知道自己在企业里面对什么东西、能调用什么工具、应该遵守什么规则。
很多人会把 Ontology 理解成知识库,这不完全对。
知识库主要解决一个问题:AI 去哪里找资料。
比如公司制度、产品手册、合同条款、客服话术、培训资料,都可以放进知识库。AI 可以检索这些资料,然后回答问题。
但 Ontology 解决的是另一个问题:
企业里的真实业务对象,怎么被 AI 理解和操作。
举个例子,知识库里可能写着:“VIP 客户订单应优先处理。”
但 Ontology 里要定义得更具体:
Ontology 不是一句口号,而是把一个领域拆成机器能理解的结构。
放到企业 Agent 里,Ontology 可以简单拆成四步:
第一,定义对象:企业里所有重要对象都要被定义出来。
比如客户、订单、合同、供应商、仓库、工单、设备、医生、病床、航班、零件、发票。
这一步看起来简单,其实很关键。
因为同一个词,在不同系统里可能不是一个意思。
销售系统里的“客户”,可能是一个公司;财务系统里的“客户”,可能是开票主体;客服系统里的“客户”,可能是一个联系人。
如果不先统一,AI 很容易把几个概念混在一起。
第二,定义关系:光有对象不够,还要知道它们怎么连在一起。
一个订单属于哪个客户;
一个客户对应哪些合同;
一个合同涉及哪些付款节点;
一个付款节点影响哪些发货权限;
一个仓库服务哪些区域;
一个医生负责哪些患者;
一个航班关联哪些机组和飞机。
这些关系,决定了 AI 能不能真正理解业务。
第三,定义动作:这些对象可以做什么?
过去的数据系统更多是“看”,看报表,看库存,看销售额,看风险。
但 AI Agent 要进入企业,就一定会涉及“做”,比如:
Ontology 要把这些动作也定义出来。
AI 不是随便点一个按钮,而是要知道:这个动作能不能做,谁能做,什么条件下能做,做完以后影响什么。
第四,定义规则:什么能自动做,什么只能建议,什么必须审批?
比如:
所以从方法论上说,Ontology 就是:
把业务拆成 Agent 能识别、能推理、能执行、能受约束的一套结构。
回到和知识库的区别,简单来说就是:知识库告诉 AI 公司知道什么,Ontology 告诉 AI 公司怎么运转。
再看一个客服退款的例子
用户说:“这个客户要退款,能不能自动处理?”
没有 Ontology,AI 可能说:“公司退款政策是XXX,建议根据公司退款政策判断。”
有 Ontology 后,agent 会先把这个业务问题拆解成:
最后它可能给出更具体的判断:
“这笔退款金额 286 元,未超过自动退款上限;订单未发货;客户无异常风险;符合自动退款规则。可以自动发起退款,并同步更新 OMS 订单状态和财务退款单。”
或者:
“这笔退款金额超过 5000 元,且客户为企业合同客户,需要销售负责人和财务审批。Agent 只能生成退款说明,不能直接执行。”
这就是 Ontology 的价值。
它让 Agent 从“回答政策”,变成“根据业务结构判断一个动作能不能做”。
这也是为什么到了 Palantir、Databricks 这些公司手里,Ontology 就不只是方法论了,而是产品能力。
Palantir 官方说,它的 Ontology 位于架构核心,不只是表达数据,而是表达企业里复杂、相互关联的决策;它通过数据、逻辑、动作和安全四个部分来建模决策。
这句话翻成简单大白话就是:
它不仅知道数据在哪里,还知道数据代表什么、能触发什么动作、谁有权限做这个动作。
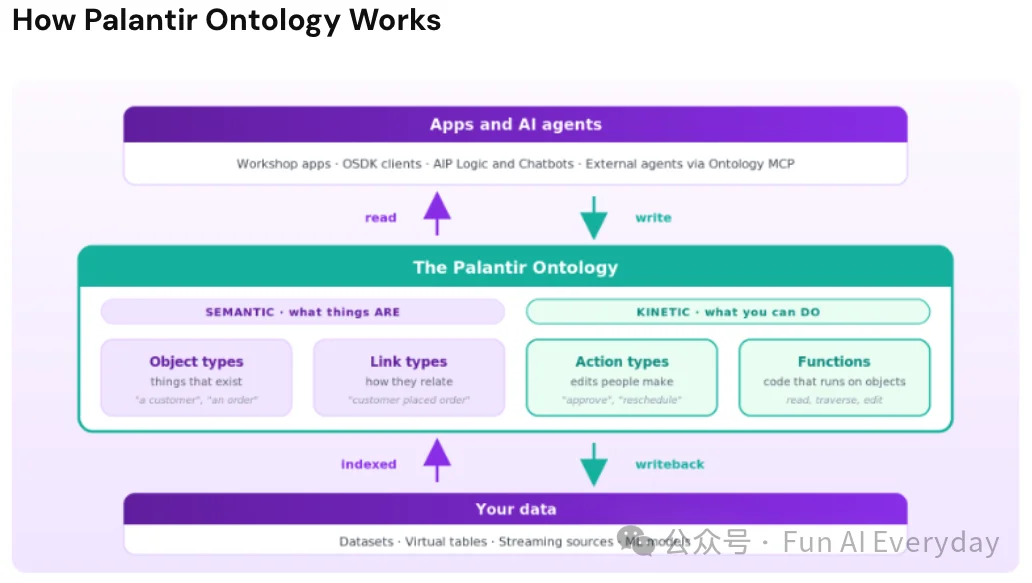
Databricks 最新再讲 Genie Ontology 时,也把它称为企业的上下文层,能从表、查询、仪表盘、数据管道和连接的业务工具中提取知识,整理成一张“公司如何运转、数据到底是什么意思”的动态关系图。
所以落地到工具层,Ontology 可能表现为:
这时它就不是一篇方法论文档,而是企业 IT 架构中的一层。
过去一年,很多企业做 AI,第一步都是做 RAG。也就是把企业文档接进大模型,让 AI 回答得更准确一点。
这当然有价值,但 RAG 更适合解决“问答问题”,比如:
但企业真正想要的,不只是问答,企业想要的是:
这时候,只靠 RAG 就不够了。
因为 RAG 可以找资料,但它不一定知道业务对象之间的关系,也不一定知道哪些动作被允许,更不一定知道执行后要写回哪里。
所以,Agent Ontology 可以看成是 RAG 之后的一层。
RAG 解决“ AI 从哪里拿信息”,Ontology 解决“ AI 怎么理解企业,并在企业里做事”。
下面我尝试举几个业务用例来说明用 Ontology 本体论来构建 Agent 的差异。
用例一:制造业排产
一家工厂突然收到一个大客户的加急订单。
如果有 Agent Ontology,AI 可以把问题拆得更细:
然后,Agent 可以给出几个方案:
接下来,它不是直接改系统,而是把方案推给生产负责人、销售负责人和供应链负责人确认。
确认之后,再把调整结果写回排产系统、库存系统和客户通知流程。
这就是 Agent Ontology 的作用。
用例二:医院床位和护理排班
一个床位,不只是一个空房间。
它关联科室、医生、护士、患者病情、手术安排、出院计划、医保规则和院感要求。
如果急诊突然来了多个患者,AI 需要判断:
如果只有大模型,它很难知道这些细节。
但如果医院有 Ontology,AI Agent 就可以在安全边界内做更具体的工作:
这里的重点不是 AI 替医生做决定。
重点是 AI 能把医院复杂的运行关系整理出来,减少人工来回查系统、打电话、问人、等确认的时间。
用例三:客服工单处理
用户投诉“订单没收到”。普通客服 AI 可以回答物流政策,也可以安抚用户。
有了 Ontology,AI Agent 可以先判断问题类型:
如果用户情绪很激烈,它可以升级给人工客服。
这时候,AI 不再只是“自动回复”,而是在按企业规则处理工单。
用例四:销售线索跟进
销售场景里,很多 AI 工具已经可以写邮件、总结会议、生成客户纪要。
但这还只是表层。
真正有价值的是,AI 能不能知道一个客户现在处在什么阶段,下一步应该做什么。
这需要把 CRM、邮件、日历、合同、报价单、产品使用数据、客户支持记录连起来。
比如一个 Agent 可以发现:
如果没有 Ontology,这些信息分散在不同系统里,AI 很难形成完整判断。
如果有 Ontology,AI 就可以生成一个很具体的跟进动作:
Palantir、Databricks 和 Skan AI 为什么总讲 Ontology?
提到 Agent Ontology,就绕不开 Palantir。
Palantir 的核心能力,是帮政府和大型企业把分散的数据、业务逻辑、操作流程和权限控制放到一套系统里。
它讲的 Ontology,本质上就是把企业里的对象、关系、动作和安全规则组织起来,让人和 AI Agent 可以在同一个业务语境里做决策。
Palantir 的意义在于,它很早就把企业 AI 的问题从“模型能力”拉回到“业务结构”。
模型可以换,但企业内部这张业务地图很难临时搭出来。
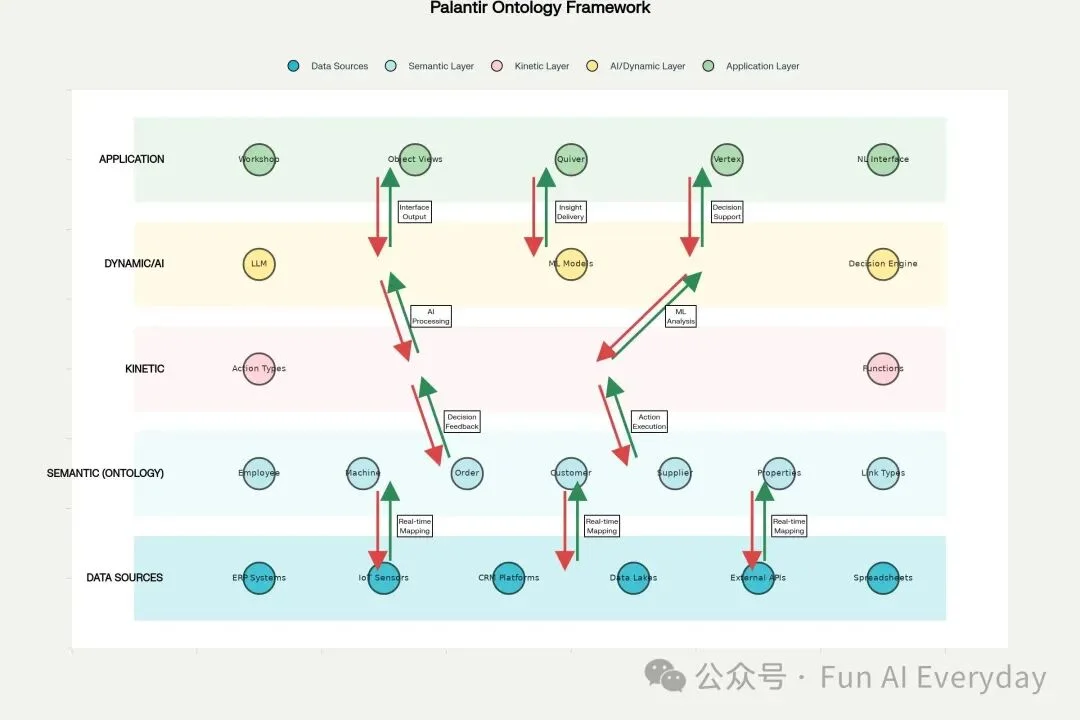
Databricks 最近推出 Genie Ontology,核心也是解决企业上下文问题。
很多企业的数据、指标、报表、文档、聊天记录、工单,都分散在不同地方。
AI 如果不知道哪个指标定义可信、哪个表是最新的、哪个团队负责这个数据,就很容易答错。
所以 Databricks 讲的 Genie Ontology,本质上是帮 Agent 建一张企业上下文图,让它知道去哪里找、相信什么、怎么按照公司真实用法回答问题。
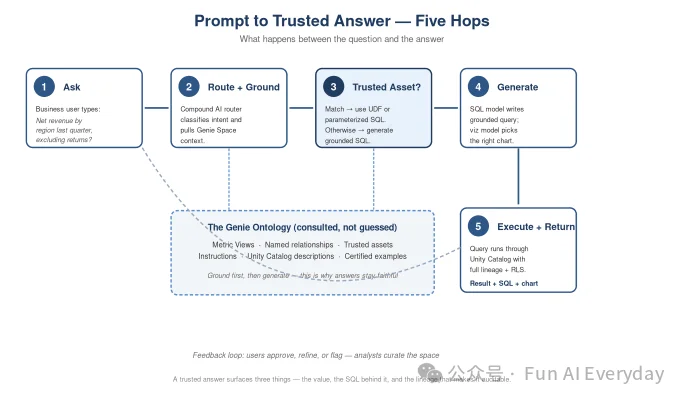
Skan AI 提出的 Agentic Ontology of Work,角度更偏“工作过程”。
它想定义人和 AI Agent 协作时的共同语言,比如 Agent、技能、意图、上下文、规则、记忆、置信度和结果。
这说明一个趋势:
企业 AI 进入 Agent 阶段后,大家都发现,只接模型和工具是不够的。
还需要一层共同语言,把人、系统、数据、流程和 AI Agent 组织起来。
以上,祝你今天开心。
文章来自于微信公众号 “Fun AI Everyday”,作者 “Fun AI Everyday”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
