
RSS 2025|物理驱动的世界模型PIN-WM:直接从视觉观测估计物理属性,可用于操作策略学习
RSS 2025|物理驱动的世界模型PIN-WM:直接从视觉观测估计物理属性,可用于操作策略学习在机器人操作中,物体运动往往涉及摩擦、碰撞等复杂物理机制。准确的物理属性描述可以实现对物体运动结果更准确的预测,并提升机器人在操作技能学习中的表现。
来自主题: AI技术研报
8815 点击 2025-05-23 12:09
 搜索
搜索
在机器人操作中,物体运动往往涉及摩擦、碰撞等复杂物理机制。准确的物理属性描述可以实现对物体运动结果更准确的预测,并提升机器人在操作技能学习中的表现。
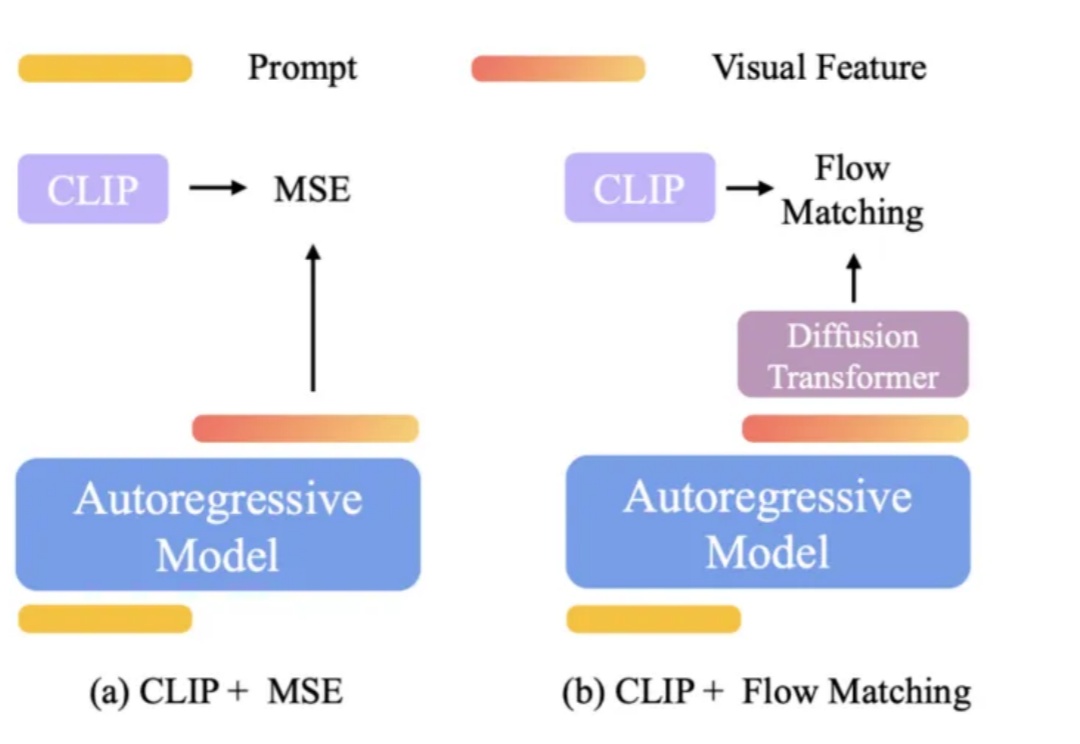
OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:

在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。
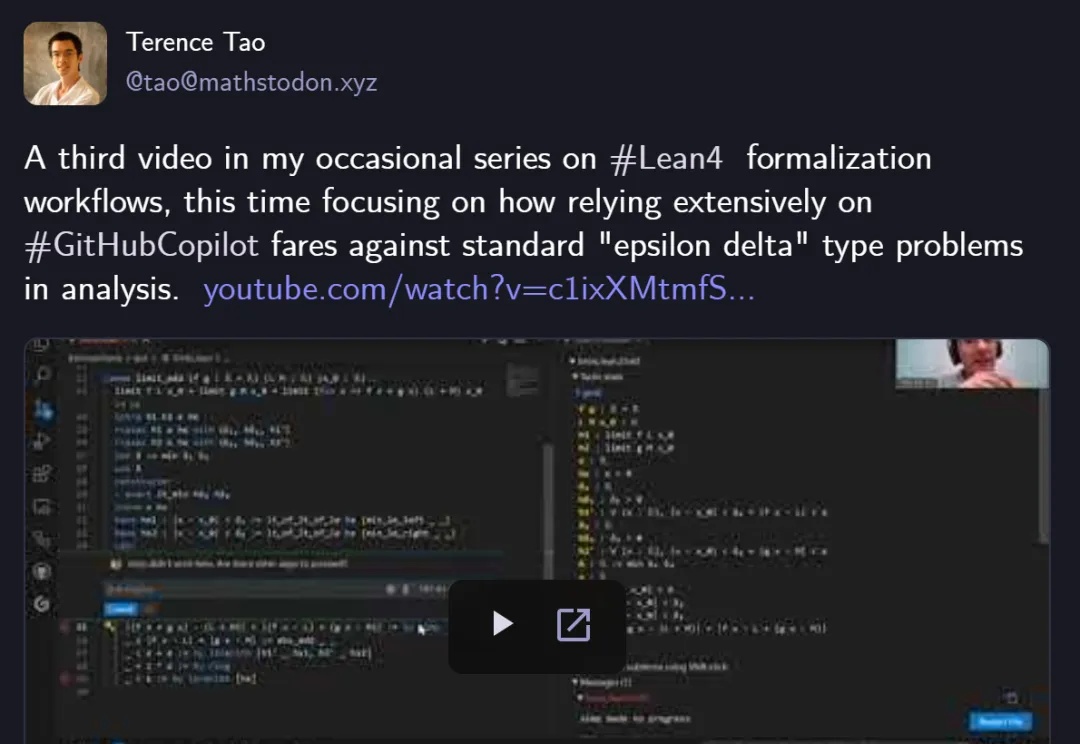
数学大师陶哲轩的第三支Lean 4自动化数学证明视频来了!他携手GitHub Copilot挑战分析学经典的「ε-δ」极限问题:加法定理Copilot挥洒自如,减法开始卡壳,乘法更是全面失控。Copilot究竟是神助攻还是添乱?
判断AI是否智能,评价维度如今已不仅限于刷榜成绩。

随着业务规模的不断扩大和用户需求的快速增长,传统的单体架构在扩展性、灵活性和运维效率等方面逐渐暴露出瓶颈,微服务架构成为当下企业技术架构转型的主流选择。智谱清言作为国内领先的大模型应用之一,基于自主研发的 GLM 模型打造了全能 AI 助手,提供多平台支持和强大的智能体创建能力。

可靠的地球系统预测对于推动人类进步和预防自然灾害至关重要。人工智能(AI)为提高该领域的预测精度和计算效率提供了巨大潜力,但在许多领域仍未得到充分开发。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!
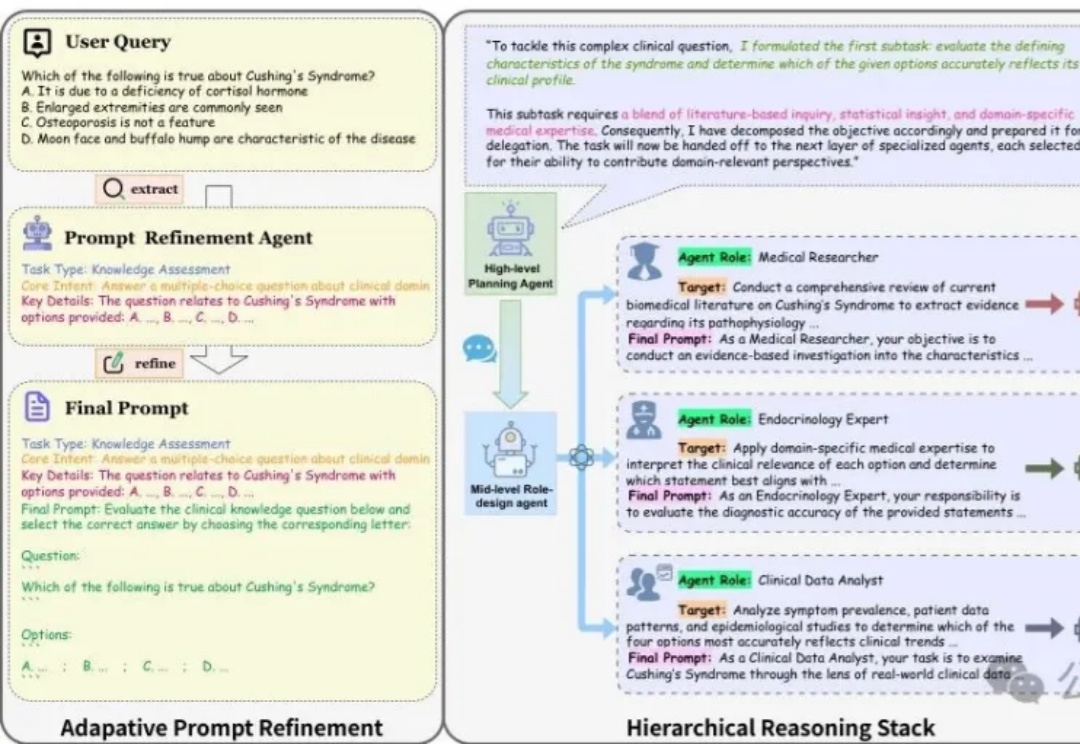
HALO框架通过三大创新机制重塑多Agent(MAS)协作方式:层次化推理架构克服了认知过载问题,让智能体各司其职;动态角色实例化能针对不同任务匹配专业智能体;基于MCTS的搜索引擎自动探索最优推理路径。它能将模糊的用户查询转化为专业提示,分解复杂任务并动态调整执行计划。
大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow。大家好,我是袋鼠帝 一直以来,分享了不少关于工作流平台、LLM应用平台的不少干货文章。 主要包含:Dify、Coze、n8n、Fastgpt、Ragflow
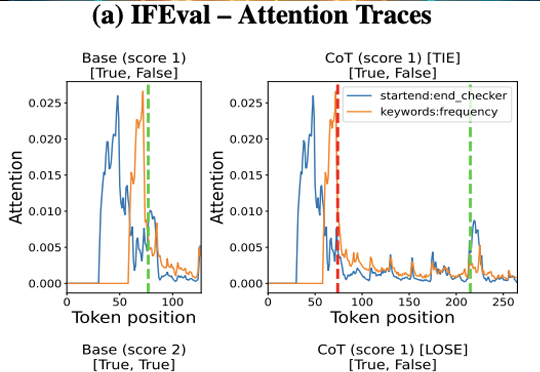
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!

不再依赖语言,仅凭图像就能完成模型推理?

何恺明团队又一力作!这次他们带来的是「生成模型界的降维打击」——MeanFlow:无需预训练、无需蒸馏、不搞课程学习,仅一步函数评估(1-NFE),就能碾压以往的扩散与流模型!

刚刚,昇腾两大技术创新,突破速度瓶颈重塑AI推理。FusionSpec创新的框架设计配合昇腾强大的计算能力,将投机推理框架耗时降至毫秒级,打破延迟魔咒。OptiQuant支持灵活量化,让推理性价比更高。

大语言模型(LLM)的生成范式正在从传统的「单人书写」向「分身协作」转变。传统自回归解码按顺序生成内容,而新兴的异步生成范式通过识别语义独立的内容块,实现并行生成。

看到朋友在网上的分享: 用Deep Research 的时候就怕在研究来源中看到ZHIHU、SINA、CSDN 这样的网址,这简直就是报告结果的灾难! 垃圾进 垃圾出。。 在大模型还没有进化出反思修正和推理新知识能力的时候,务必屏蔽掉低质量信息源,AI无脑文越演越烈。

得益于AI上下文和审美能力的提升,现在做HTML已经没什么门槛了,可以应用到很多方面,例如小红书封面、PPT、原型图、数据看板等等。
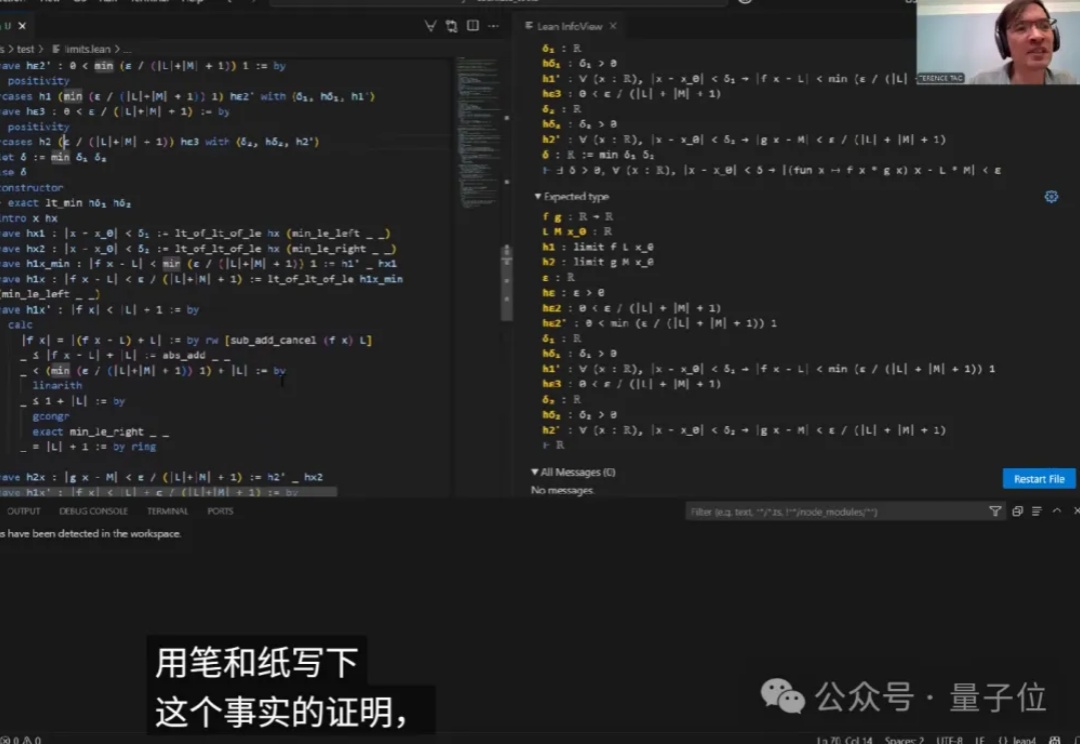
视频新人博主陶哲轩又更新了!这次是“喂饭级”AI教程—— 手把手演示如何只用GitHub Copilot证明函数极限问题。

洛桑联邦理工学院研究团队发现,当GPT-4基于对手个性化信息调整论点时,64%的情况下说服力超过人类。实验通过900人参与辩论对比人机表现,结果显示个性化AI达成一致概率提升81.2%。研究警示LLM可能被用于传播虚假信息,建议利用AI生成反叙事内容应对威胁,但实验环境与真实场景存在差异。

今天橘子的新产品可以一分钟将任何内容变成播客的 ListenHub发布了,照例想用提示词为他做一张长图。

有多久没喝雪碧了,记不清了。
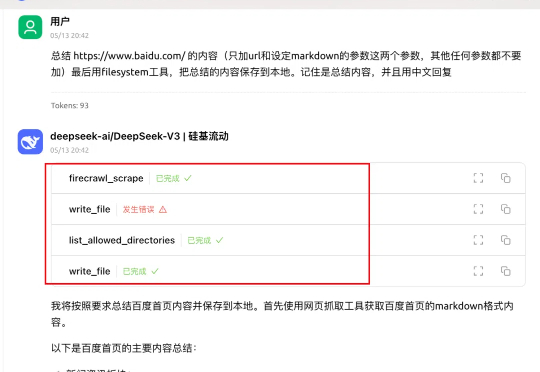
大家好,我是袋鼠帝前几天收到一个客朋友的咨询:“有没有什么爬虫软件推荐?”

在基本物理任务上,前沿AI模型仍会失败!ML研究院的测试案例显示白领将被Ai替代,而制造业等蓝领工作不受影响。未来已来,只是分布得不均匀。

要问最近哪个模型最火,混合专家模型(MoE,Mixture of Experts)绝对是榜上提名的那一个。
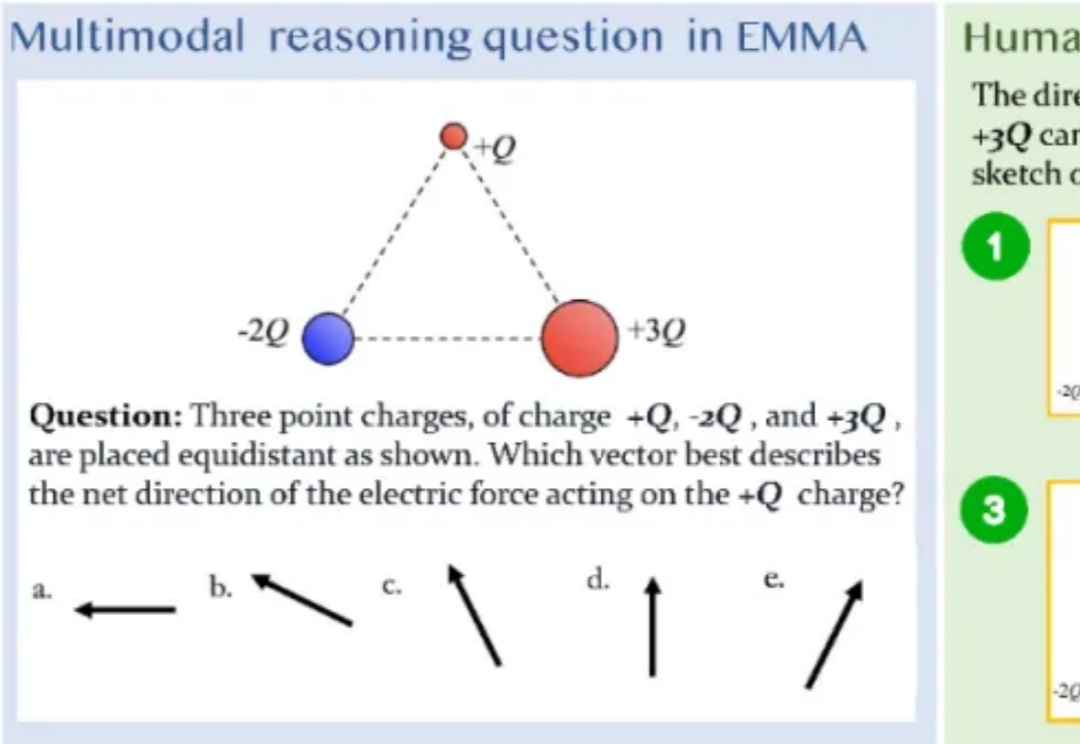
「三个点电荷 + Q、-2Q 和 + 3Q 等距放置,哪个向量最能描述作用在 + Q 电荷上的净电力方向?」
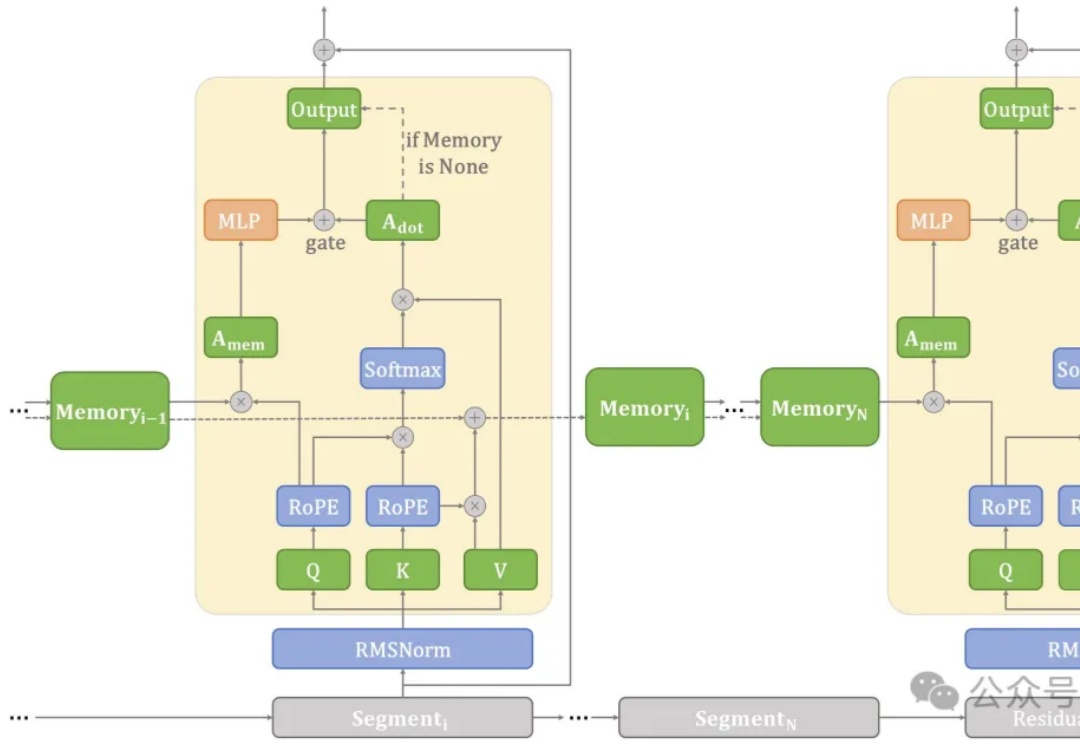
在端侧设备上处理长文本常常面临计算和内存瓶颈。
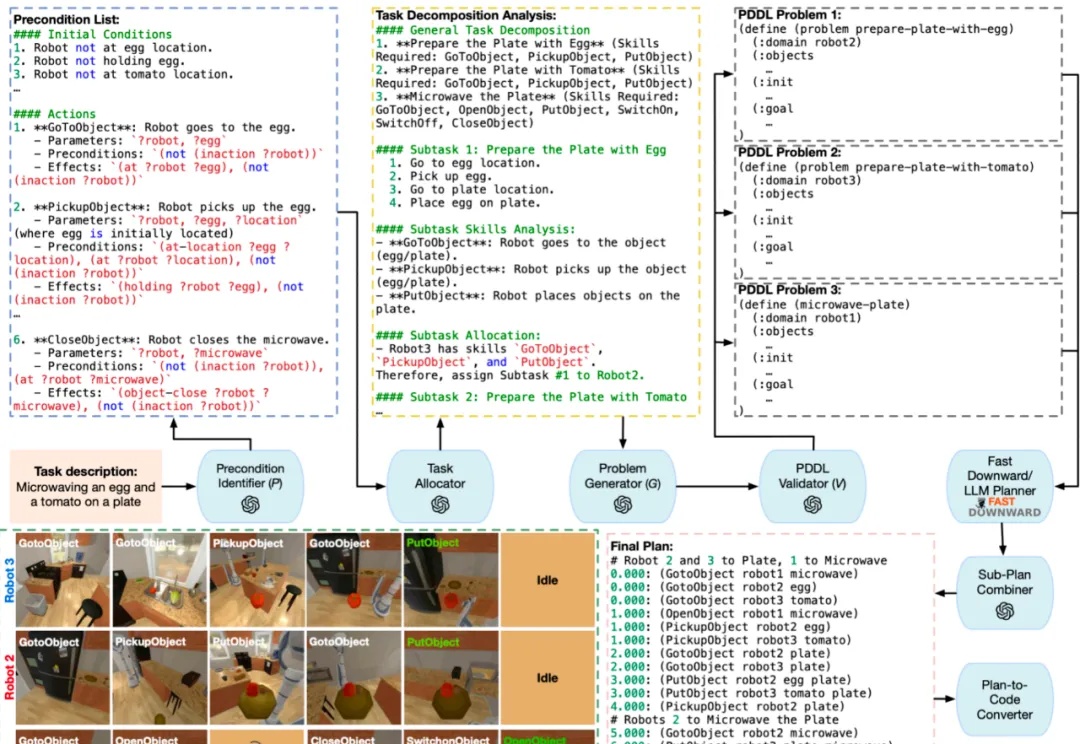
2025 年 5 月,美国加州大学河滨分校 (UC Riverside) 与宾夕法尼亚州立大学 (Penn State University) 联合团队在机器人领域顶级会议 ICRA 2025 上发布最新研究成果 LaMMA-P。

就在刚刚,智源研究员联合多所高校开放三款向量模型,以大优势登顶多项测试基准。其中,BGE-Code-v1直接击穿代码检索天花板,百万行级代码库再也不用怕了!

太震撼了,有开发者代码实证后发现,谷歌AlphaEvolve的矩阵乘法突破,被证明为真!Claude辅助下,他成功证明,它果然仅用了48次乘法,就正确完成了4×4矩阵的乘法运算。接下来,可以坐等AlphaEvolve更「奇点」的发现了。