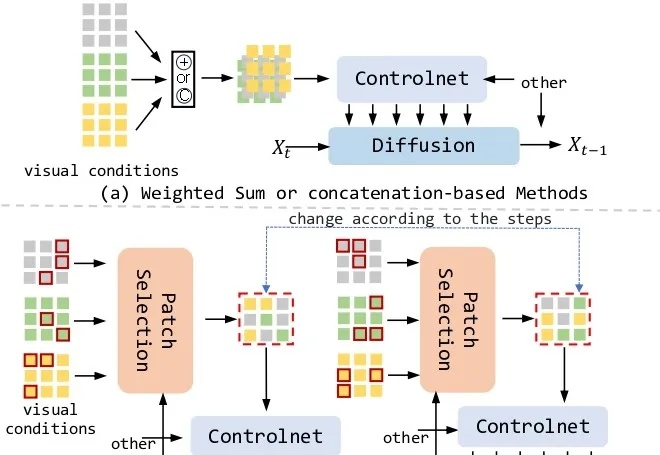
超越ControlNet!复旦联合腾讯优图提出AI生图新框架,解决多条件生成难题
超越ControlNet!复旦联合腾讯优图提出AI生图新框架,解决多条件生成难题文生图新架构来了!
来自主题: AI技术研报
8707 点击 2025-04-15 15:04
 搜索
搜索
文生图新架构来了!
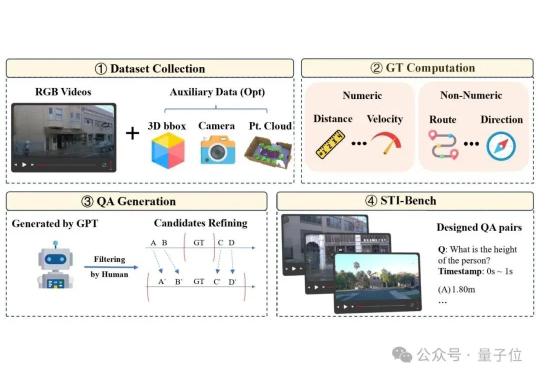
多模态大语言模型(MLLM)在具身智能和自动驾驶“端到端”方案中的应用日益增多,但它们真的准备好理解复杂的物理世界了吗?

移动GUI自动化智能体V-Droid采用「验证器驱动」架构,通过离散化动作空间并利用LLM评估候选动作,实现了高效决策。在AndroidWorld等多个基准测试中任务成功率分别达到59.5%、38.3%和49%,决策延迟仅0.7秒,接近实时响应。
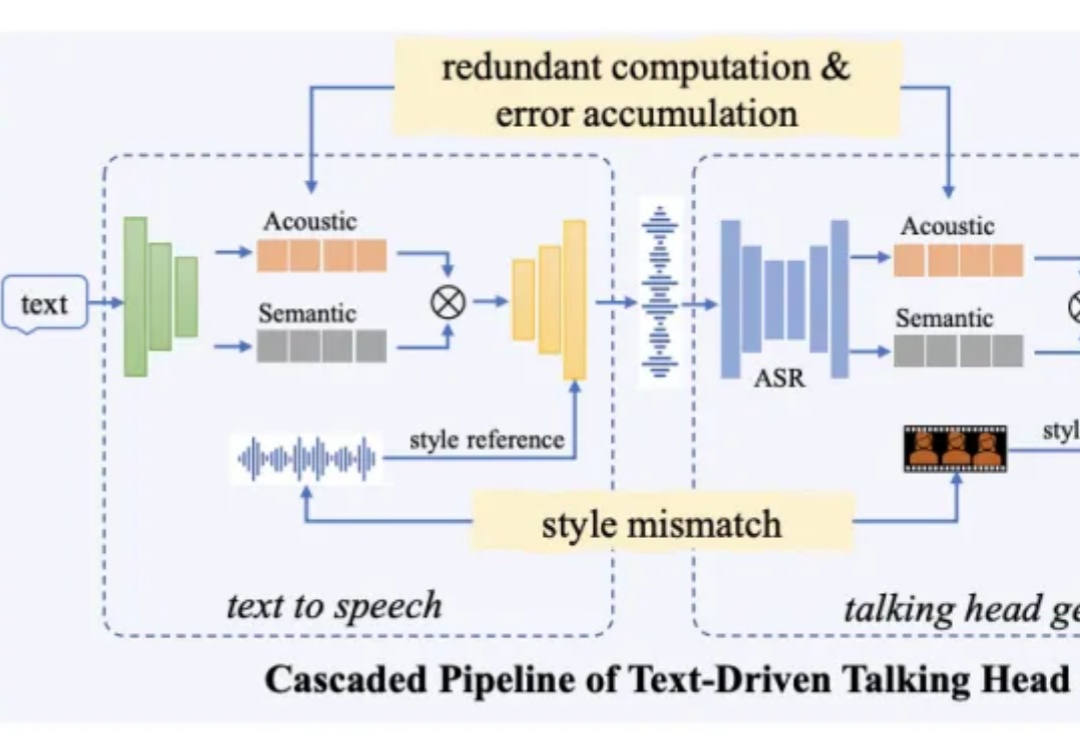
近日,阿里通义实验室推出了全新数字人视频生成大模型 OmniTalker,只需上传一段参考视频,不仅能学会视频中人物的表情和声音,还能模仿说话风格。相比传统的数字人生产流程,该方法能够有效降低制作成本,提高生成内容的真实感和互动体验,满足更广泛的应用需求。目前该项目已在魔搭社区、HuggingFace 开放体验入口,并提供了十多个模板,所有人可以直接免费使用。
组合优化问题(COPs)在科学和工业领域无处不在,从物流调度到芯片设计,从社交网络分析到人工智能算法,其高效求解一直是研究热点。
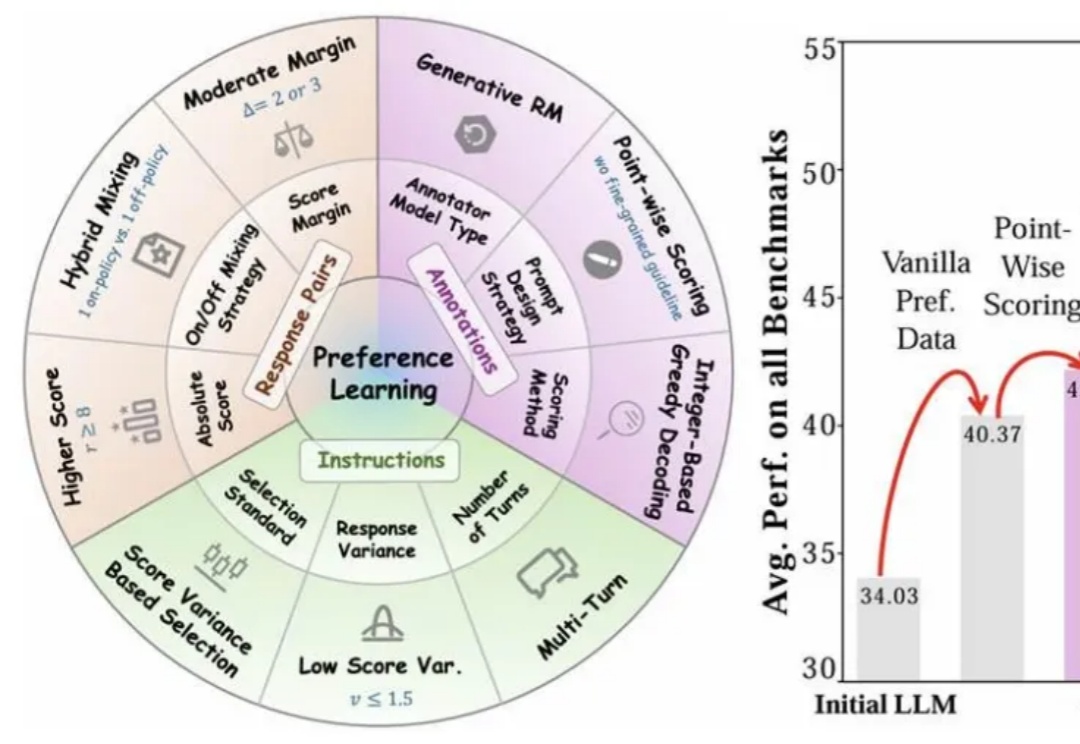
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
今天凌晨,OpenAI 的新系列模型 GPT-4.1 如约而至。

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
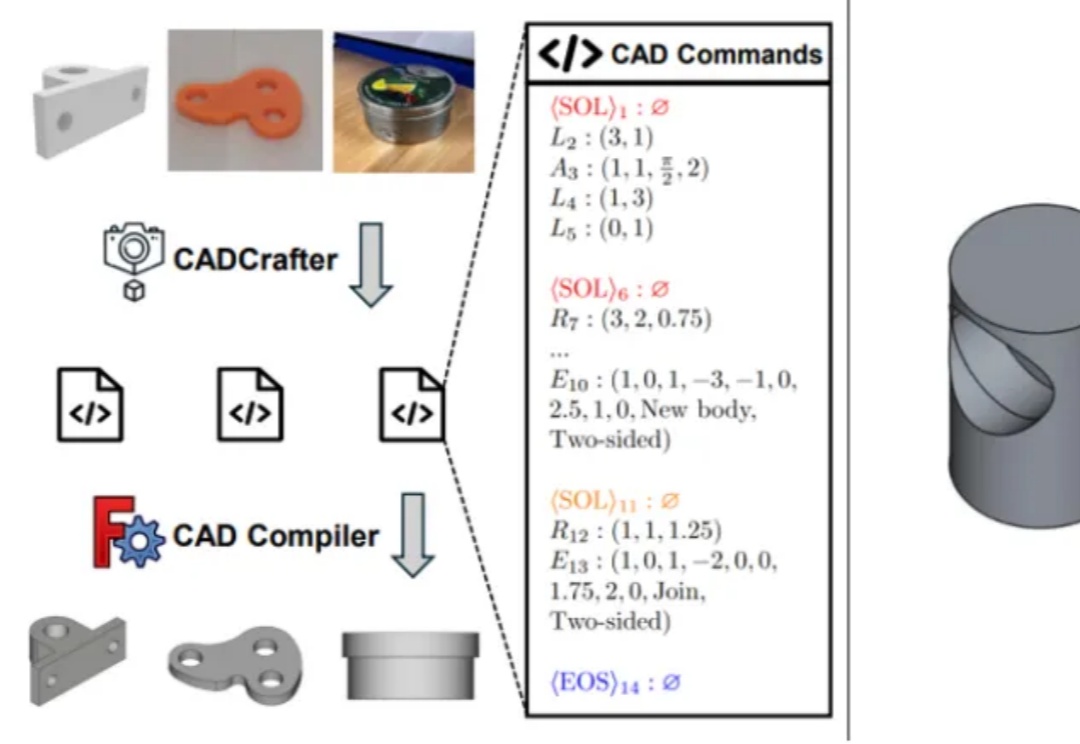
单张图直接就能生成可编辑的CAD工程文件!

开发Agent的工程师们都曾面临同一个棘手问题:当任务步骤增多,你的Agent就像患上"数字健忘症",忘记之前做过什么,无法处理用户的修改请求,甚至在多轮对话中迷失自我。不仅用户体验受损,token开销也居高不下。TME树状记忆引擎通过结构化状态管理方案,彻底解决了这一痛点,让你的Agent像拥有完美记忆力的助手,在复杂任务中游刃有余,同时将token消耗降低26%。

AI辅助人类,完成了首个非平凡研究数学证明,破解了50年未解的数学难题!在南大校友的研究中,这个难题中q=3的情况,由o3-mini-high给出了精确解。
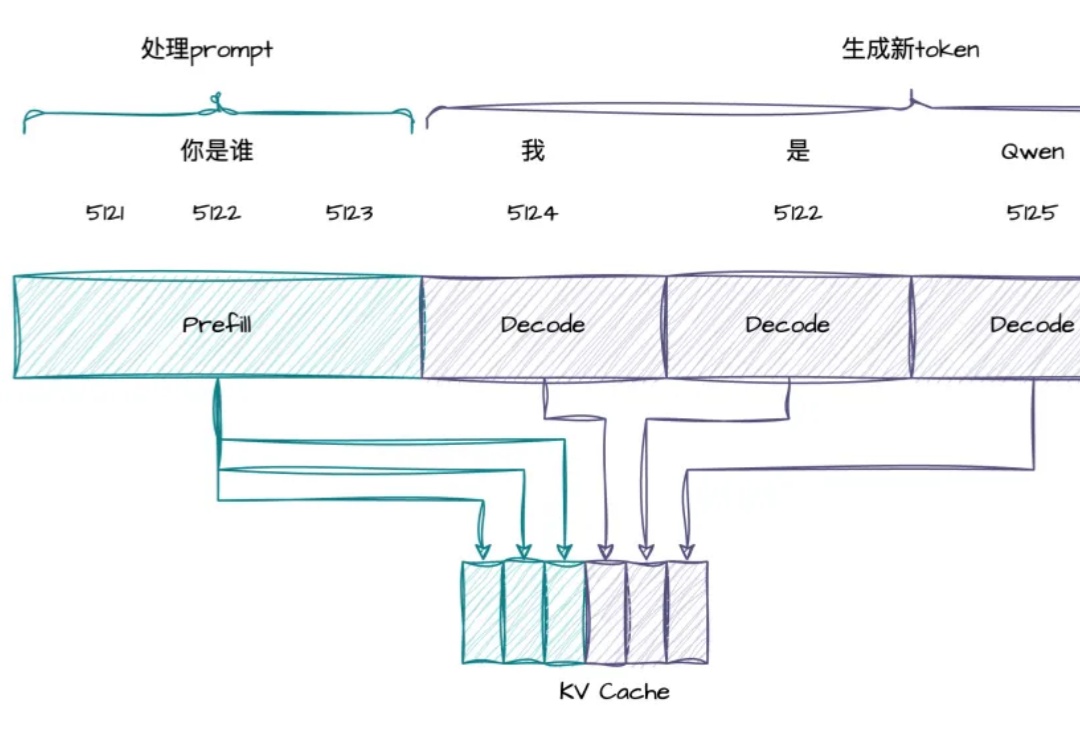
RTP-LLM 是阿里巴巴大模型预测团队开发的高性能 LLM 推理加速引擎。它在阿里巴巴集团内广泛应用,支撑着淘宝、天猫、高德、饿了么等核心业务部门的大模型推理需求。在 RTP-LLM 上,我们实现了一个通用的投机采样框架,支持多种投机采样方法,能够帮助业务有效降低推理延迟以及提升吞吐。
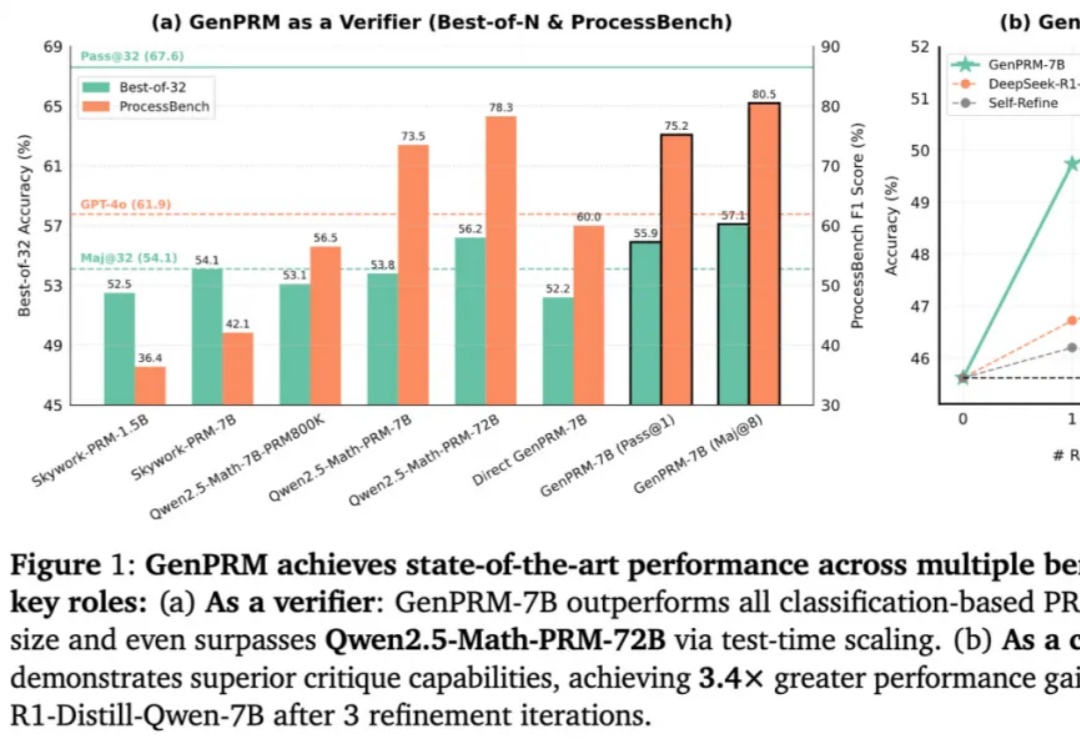
随着 OpenAI o1 和 DeepSeek R1 的爆火,大语言模型(LLM)的推理能力增强和测试时扩展(TTS)受到广泛关注。然而,在复杂推理问题中,如何精准评估模型每一步回答的质量,仍然是一个亟待解决的难题。传统的过程奖励模型(PRM)虽能验证推理步骤,但受限于标量评分机制,难以捕捉深层逻辑错误,且其判别式建模方式限制了测试时的拓展能力。
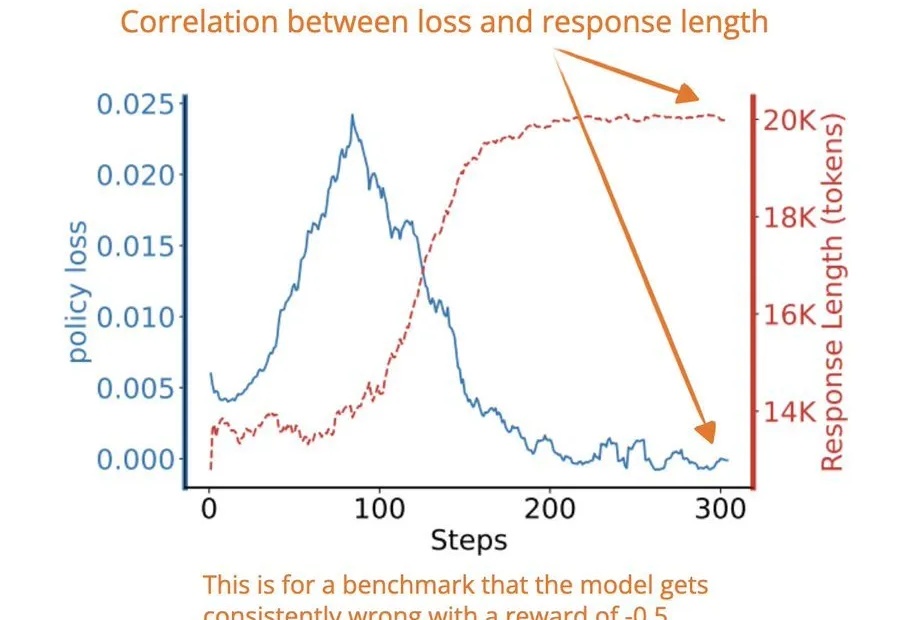
今天早些时候,著名研究者和技术作家 Sebastian Raschka 发布了一条推文,解读了一篇来自 Wand AI 的强化学习研究,其中分析了推理模型生成较长响应的原因。

研究发现,推理模型(如DeepSeek-R1、o1)遇到「缺失前提」(MiP)的问题时,这些模型往往表现失常:回答长度激增、计算资源浪费。本文基于马里兰大学和利哈伊大学的最新研究,深入剖析推理模型在MiP问题上的「过度思考」现象,揭示其背后的行为模式,带你一窥当前AI推理能力的真实边界。
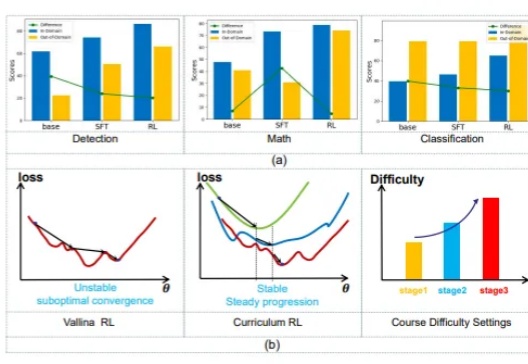
近年来,随着大型语言模型(LLMs)的快速发展,多模态理解领域取得了前所未有的进步。像 OpenAI、InternVL 和 Qwen-VL 系列这样的最先进的视觉-语言模型(VLMs),在处理复杂的视觉-文本任务时展现了卓越的能力。
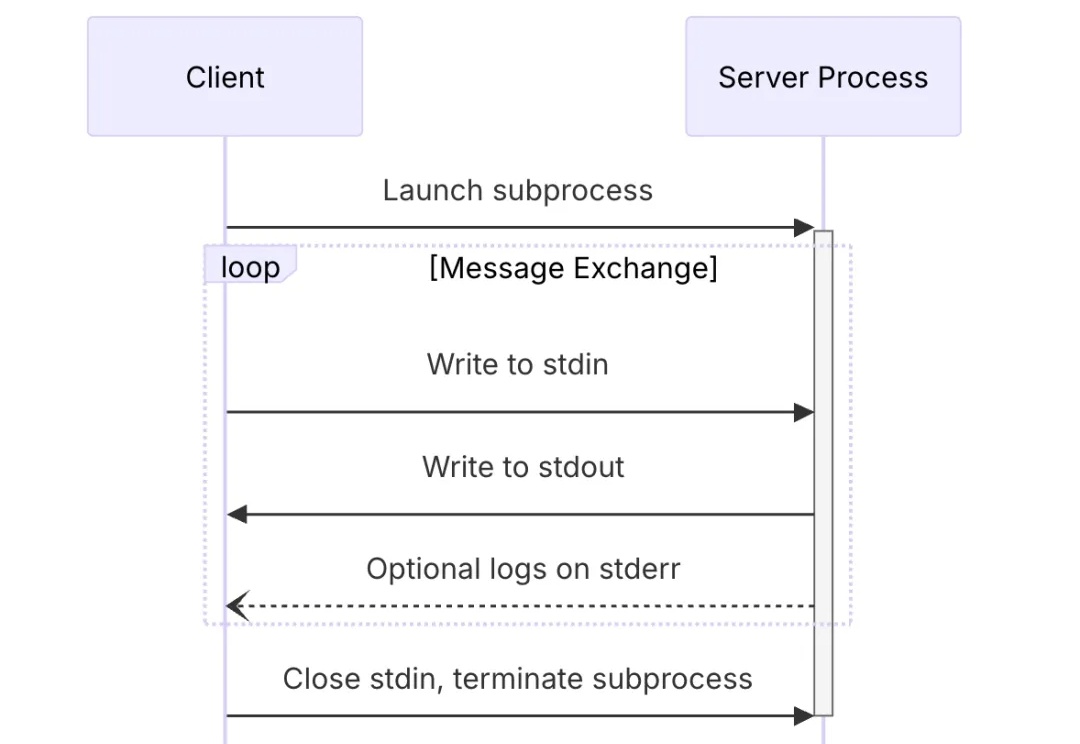
MCP 传输机制(Transport)是 MCP 客户端与 MCP 服务器通信的一个桥梁,定义了客户端与服务器通信的细节,帮助客户端和服务器交换消息。
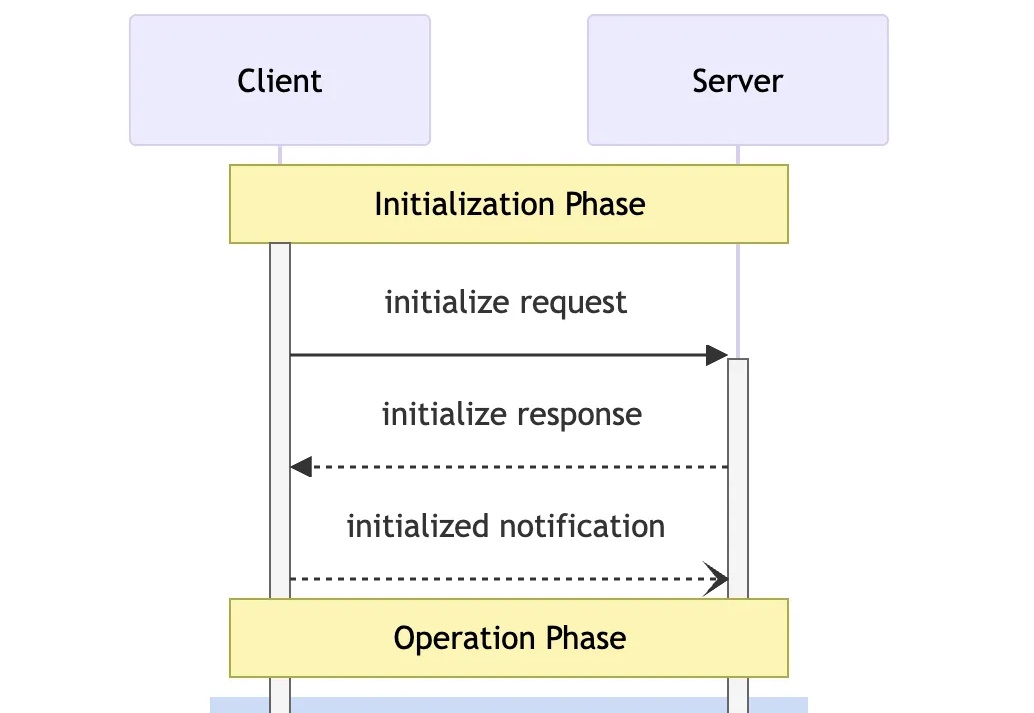
MCP 协议定义了一个严格的生命周期,用于客户端-服务器连接,确保了通信双方能进行适当的状态管理和能力协商。
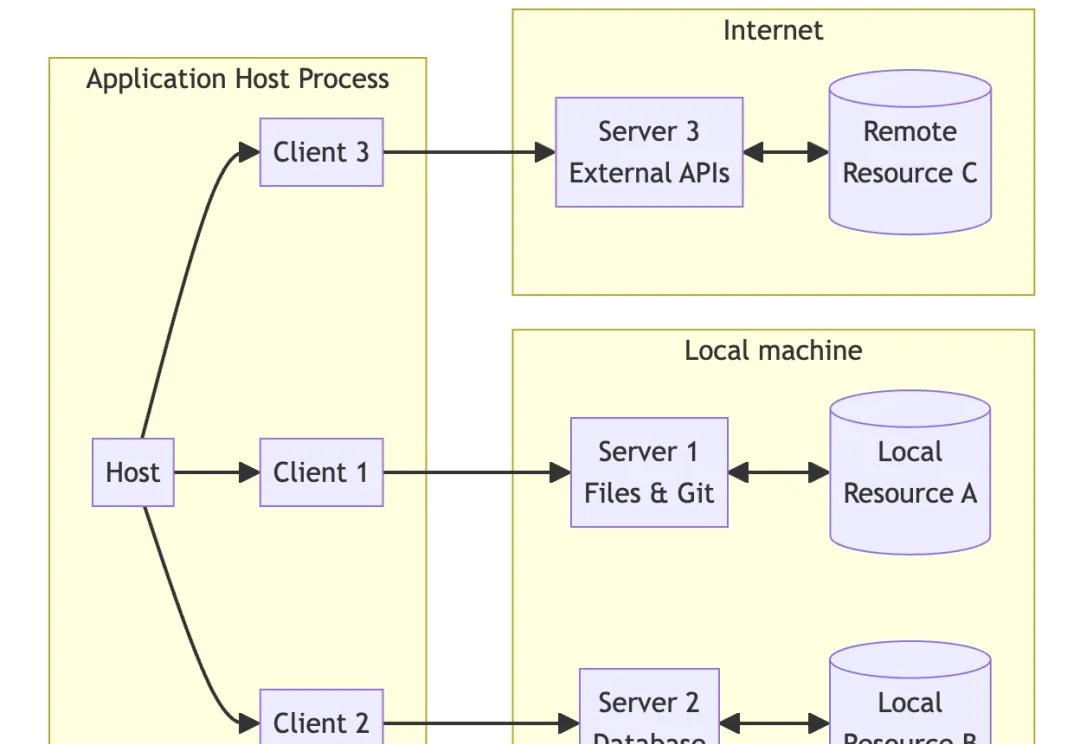
MCP 协议遵循互联网常见的 C / S 架构,即客户端(Client)- 服务器(Server)架构。
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。

终于,华为盘古大模型系列上新了,而且是昇腾原生的通用千亿级语言大模型。我们知道,如今各大科技公司纷纷发布百亿、千亿级模型。但这些大部分模型训练主要依赖英伟达的 GPU。
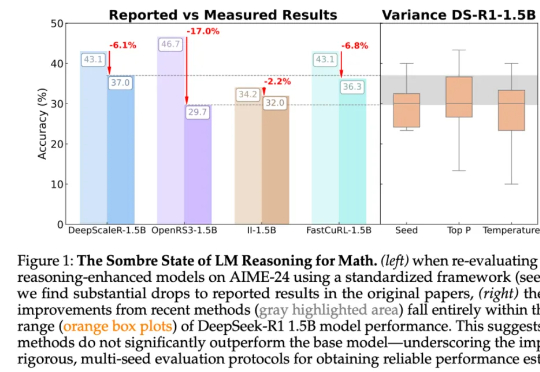
尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

来自Meta和NYU的团队,刚刚提出了一种MetaQuery新方法,让多模态模型瞬间解锁多模态生成能力!令人惊讶的是,这种方法竟然如此简单,就实现了曾被认为需要MLLM微调才能具备的能力。

GitHub 在其 Copilot 功能中引入了一项基于 AI 的密码扫描功能,该功能已经整合到 GitHub Secret Protection 中。

如果你没有杜蕾斯背后强大的5A广告公司、鬼才般的创意团队、句句封神的的金牌文案、审美爆辣的视觉艺术家。借助即梦刚上线的3.0生图模型以及 Deepseek生创意和文案,你也可以轻松复刻一个「杜蕾斯级别」的刷屏海报。

人和智能体共享奖励参数,这才是强化学习正确的方向?

仅用4090就能实现大规模城市场景重建!

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。

AI Agent 领域也存在 scaling law,甚至还在加速。