对话周光:自动驾驶实现AGI,RoadAGI比L5更快 | GTC 2025
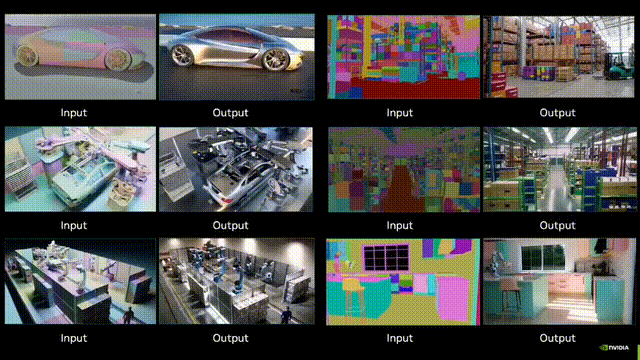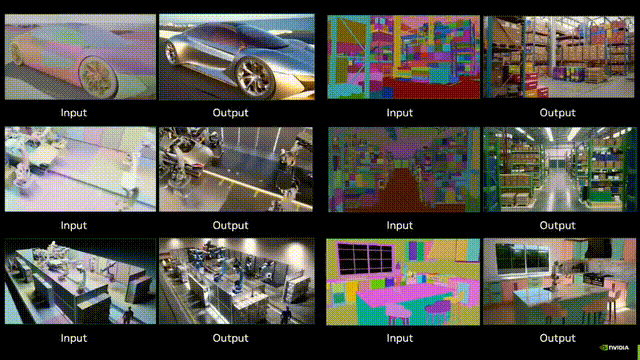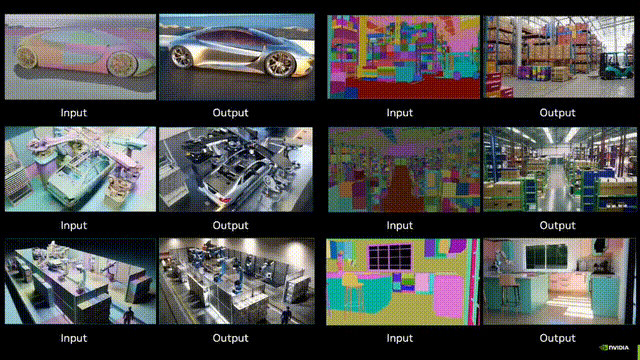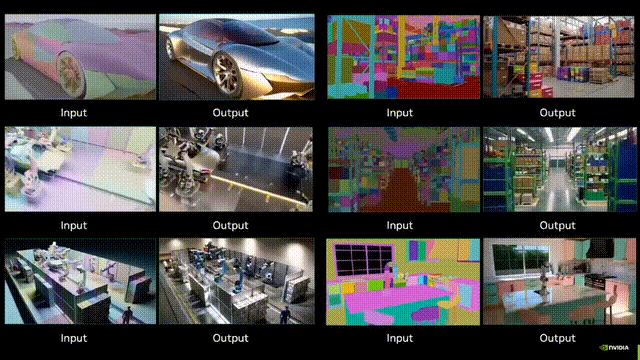
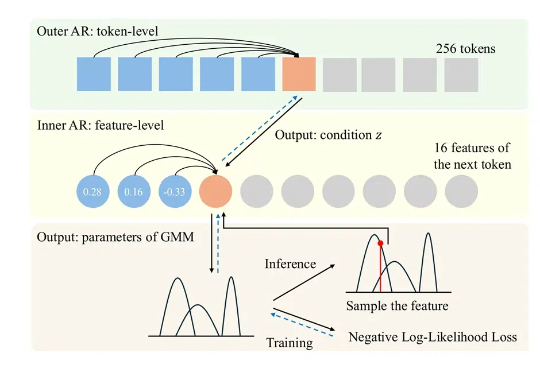
对话周光:自动驾驶实现AGI,RoadAGI比L5更快 | GTC 2025自动驾驶实现垂直领域的AGI,有了新路径。不是Robotaxi,而是RoadAGI。在英伟达GTC 2025上,元戎启行CEO周光受邀分享,提出用RoadAGI,能更快大规模商用自动驾驶,实现垂直道路场景下的AGI,RoadAGI的实施平台,是元戎最新分享的AI Spark:
来自主题: AI技术研报
8841 点击 2025-03-22 14:32