被DeepSeek带火的知识蒸馏,开山之作曾被NeurIPS拒收,Hinton坐镇都没用
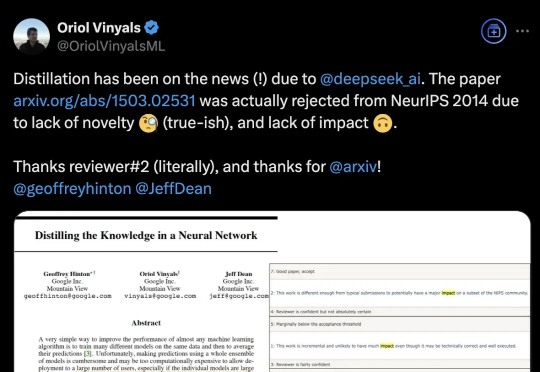
被DeepSeek带火的知识蒸馏,开山之作曾被NeurIPS拒收,Hinton坐镇都没用DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的《Distilling the Knowledge in a Neural Network》,当年被NeurIPS 2014拒收。
来自主题: AI技术研报
8158 点击 2025-02-07 15:43