
UC伯克利等最新实锤:LLM就是比人类啰嗦,「提问的艺术」仍难参透
UC伯克利等最新实锤:LLM就是比人类啰嗦,「提问的艺术」仍难参透基于一段文本提问时,人类和大模型会基于截然不同的思维模式给出问题。大模型喜欢那些需要详细解释才能回答的问题,而人类倾向于提出更直接、基于事实的问题。
来自主题: AI技术研报
5803 点击 2025-01-29 13:32
 搜索
搜索
基于一段文本提问时,人类和大模型会基于截然不同的思维模式给出问题。大模型喜欢那些需要详细解释才能回答的问题,而人类倾向于提出更直接、基于事实的问题。

「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。
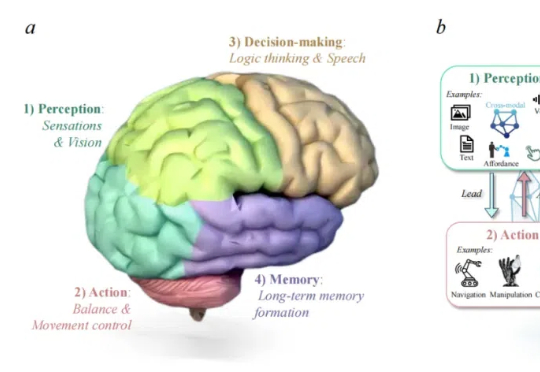
由港科广、中南、西湖大学、UIUC、新加坡国立大学、上海 AI Lab、宾夕法尼亚大学等团队联合发布的首篇聚焦医疗领域具身智能的综述论文《A Survey of Embodied AI in Healthcare: Techniques, Applications, and Opportunities》正式上线,中南大学刘艺灏为第一作者

ETH Zurich等机构提出了推理语言模型(RLM)蓝图,超越LLM局限,更接近AGI,有望人人可用o3这类强推理模型。

VARGPT是一种新型多模态大模型,能够在单一框架内实现视觉理解和生成任务。通过预测下一个token完成视觉理解,预测下一个scale完成视觉生成,展现出强大的混合模态输入输出能力。
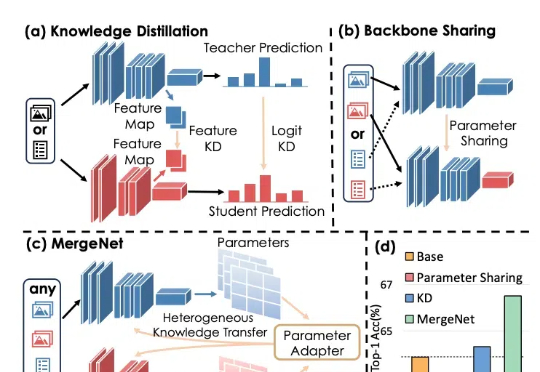
知识蒸馏通过训练一个紧凑的学生模型来模仿教师模型的 Logits 或 Feature Map,提高学生模型的准确性。迁移学习则通常通过预训练和微调,将预训练阶段在大规模数据集上学到的知识通过骨干网络共享应用于下游任务。

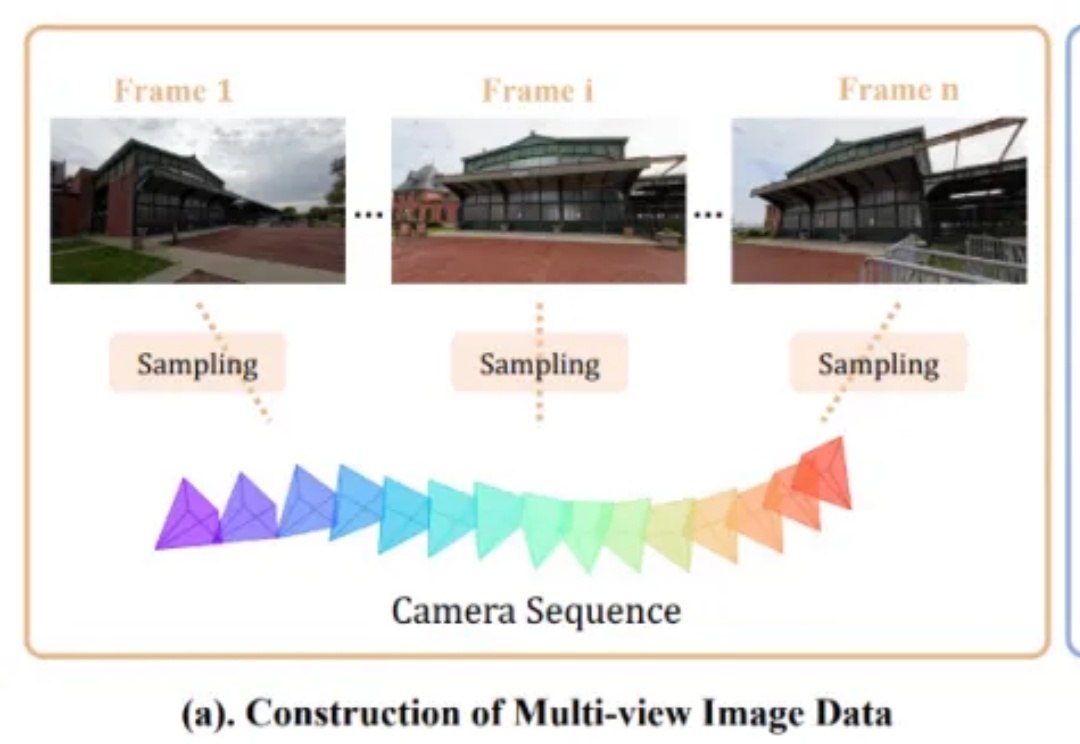
在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?

2028年,预计高质量数据将要耗尽,数据Scaling走向尽头。2025年,测试时计算将开始成为主导AI通向通用人工智能(AGI)的新一代Scaling Law。近日,CMU机器学习系博客发表新的技术文章,从元强化学习(meta RL)角度,详细解释了如何优化LLM测试时计算。
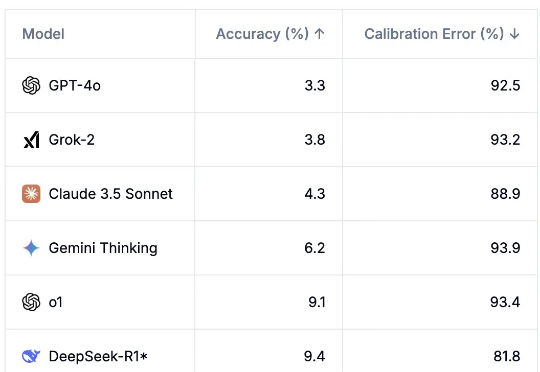
AI模型可能并没有想象中强大。在最新的AI基准测试「人类最后一次考试」中,所有顶尖LLM通过率不超过10%,而且模型都表现得过度自信。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。

智能体究竟能否应对现实世界的复杂性?The Agent Company近日提出了一项评估基准,让多个智能体尝试自主运营一个软件公司。结果表明,即使是当前最先进的智能体,也无法自主完成大多数任务。
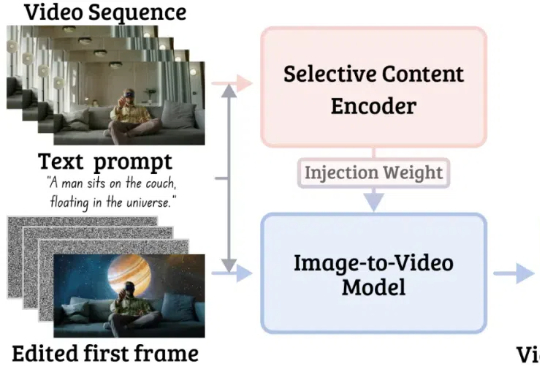
论文一作刘少腾,Adobe Research实习生,香港中文大学博士生(DV Lab),师从贾佳亚教授。主要研究方向是多模态大模型和生成模型,包含图像视频的生成、理解与编辑。作者Tianyu Wang、Soo Ye Kim等均为Adobe Research Scientist。
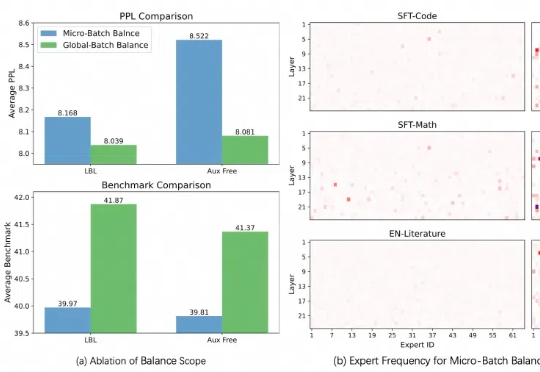
本周,在阿里云通义千问 Qwen 团队提交的一篇论文中,研究人员发现了目前最热门的 MoE(混合专家模型)训练中存在的一个普遍关键问题,并提出一种全新的方法——通过轻量的通信将局部均衡放松为全局均衡,使得 MoE 模型的性能和专家特异性都得到了显著的提升。
视觉版o1的初步探索,阶跃星辰&北航团队推出“慢感知”。研究人员认为:1)目前多模领域o1-like的模型,主要关注文本推理,对视觉感知的关注不够。2)精细/深度感知是一个复杂任务,且是未来做视觉推理的重要基础。
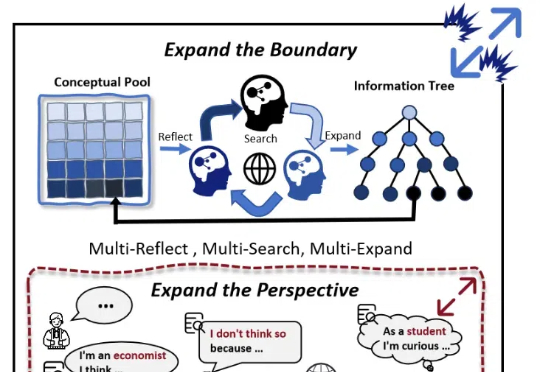
随着大模型(LLMs)的发展,AI 写作取得了较大进展。然而,现有的方法大多依赖检索知识增强生成(RAG)和角色扮演等技术,其在信息的深度挖掘方面仍存在不足,较难突破已有知识边界,导致生成的内容缺乏深度和原创性。

非营利研究机构AI2近日推出的完全开放模型OLMo 2,在同等大小模型中取得了最优性能,且该模型不止开放权重,还十分大方地公开了训练数据和方法。

AI智能体正悄然成为我们工作和生活中的得力助手。从自动化任务到复杂规划,它们不仅能帮我们做市场调研、准备面试,还能完成复杂的决策任务。

瞄准推理时扩展(Inference-time scaling),DeepMind新的进化搜索策略火了! 所提出的“Mind Evolution”(思维进化),能够优化大语言模型(LLMs)在规划和推理中的响应。

OpenAI的新Scaling Law,含金量又提高了。

苏格拉底曾提到的门诺悖论(Meno's paradox)认为,人只能学会自己已经知道的事情;而关于AI辅助编程,谷歌资深工程师最近的一篇博客告诉我们,类似的知识悖论同样存在。

OpenAI 在 “双十二” 发布会的最后一天公开了 o 系列背后的对齐方法 - deliberative alignment,展示了通过系统 2 的慢思考能力提升模型安全性的可行性。

未来,掌握持续提示工程技术的开发者,将主导下一代智能系统的进化方向。

新年第一天,陈天奇团队的FlashInfer论文出炉!块稀疏、可组合、可定制、负载均衡......更快的LLM推理技术细节全公开。
ChatGPT等聊天机器人背后的算法能从各种各样的网络文本中抓取万亿字节的素材,文本来源可以是网络文章,也可以是社媒平台的帖子,还可以是视频里的字幕或评论。

时隔不到一个月,DeepSeek又一次震动全球AI圈。去年 12 月,DeepSeek推出的DeepSeek-V3在全球AI领域掀起了巨大的波澜,它以极低的训练成本,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。

研究者提出了FAST,一种高效的动作Tokenizer。通过结合离散余弦变换(DCT)和字节对编码(BPE),FAST显著缩短了训练时间,并且能高效地学习和执行复杂任务,标志着机器人自回归Transformer训练的一个重要突破。
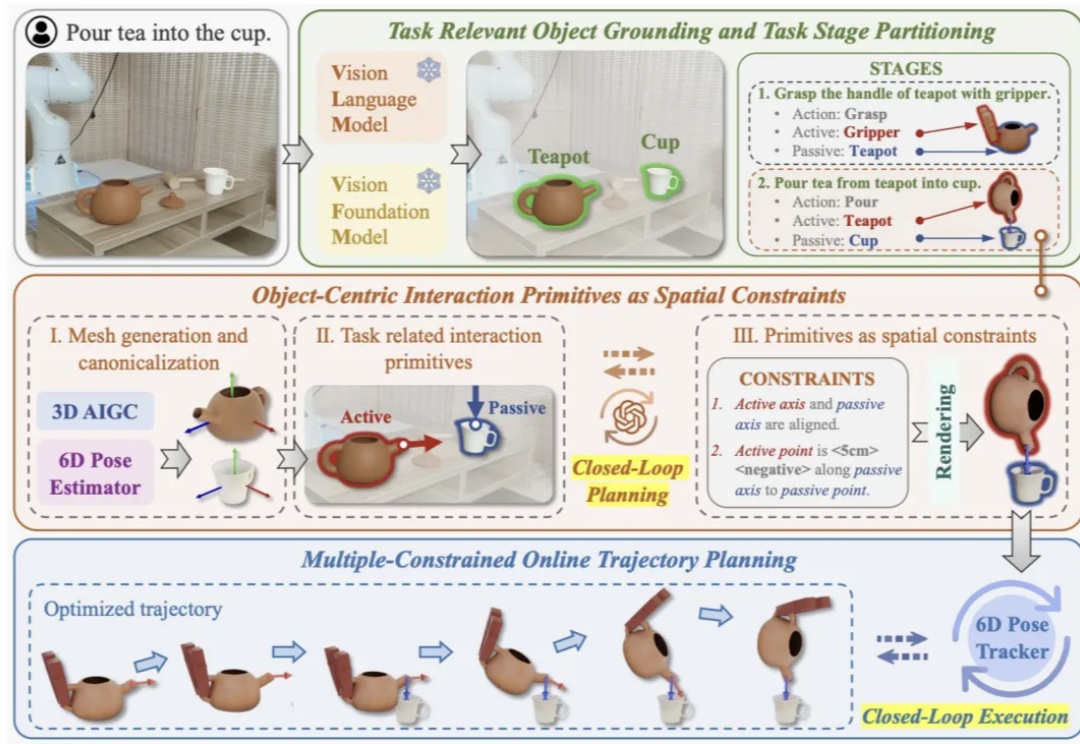
近年来视觉语⾔基础模型(Vision Language Models, VLMs)在多模态理解和⾼层次常识推理上⼤放异彩,如何将其应⽤于机器⼈以实现通⽤操作是具身智能领域的⼀个核⼼问题。这⼀⽬标的实现受两⼤关键挑战制约:
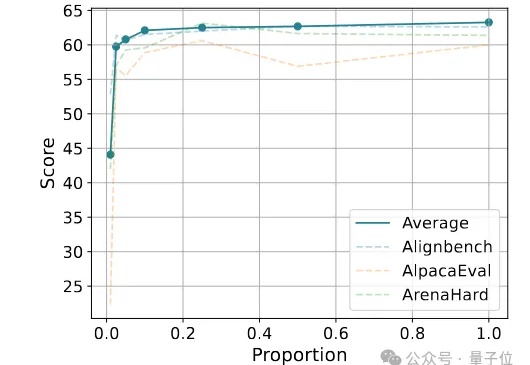
仅使用20K合成数据,就能让Qwen模型能力飙升——
可灵,视频生成领域的佼佼者,近来动作不断。继发布可灵 1.6 后,又公开了多项研究揭示视频生成的洞察与前沿探索 ——《快手可灵凭什么频繁刷屏?揭秘背后三项重要研究》。
今天是个好日子,DeepSeek 与 Kimi 都更新了最新版的推理模型,吸引了广泛关注。与此同时,谷歌 DeepMind、加州大学圣地亚哥分校、阿尔伯塔大学的一篇新的研究论文也吸引了不少眼球,并直接冲上了 Hugging Face 每日论文榜第一(1 月 20 日)。