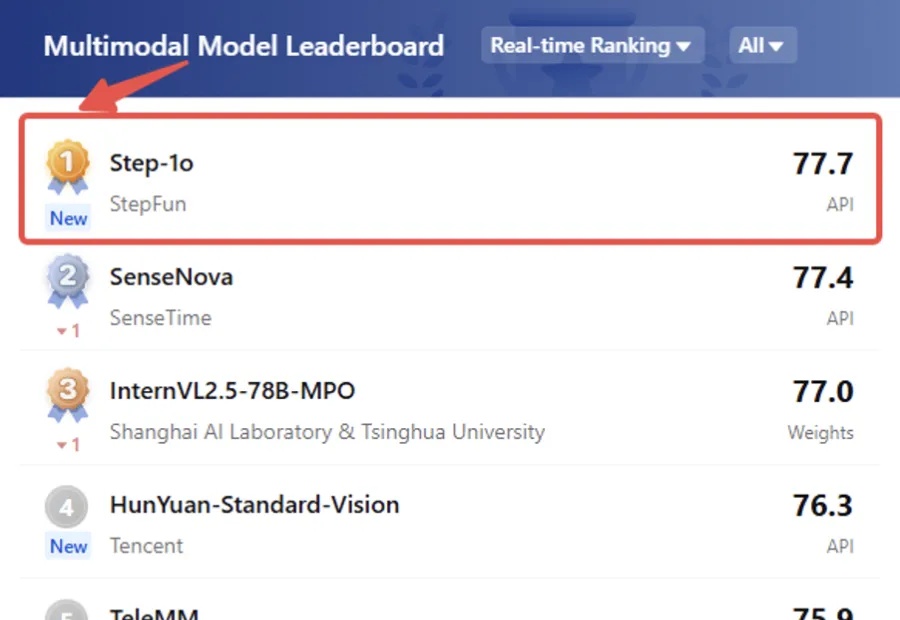
6天连发6模型,阶跃稳稳蝉联多模态卷王
6天连发6模型,阶跃稳稳蝉联多模态卷王我勒个老天奶,大模型六小强之一的阶跃星辰,给大家拜早年的方式可真不一样——
来自主题: AI技术研报
5682 点击 2025-01-23 10:50
 搜索
搜索
我勒个老天奶,大模型六小强之一的阶跃星辰,给大家拜早年的方式可真不一样——

2024年,智元机器人与北大成立联合实验室,8月发布“远征”与“灵犀”两大系列共五款商用人形机器人新品,10月旗下灵犀X1人形机器人官宣开源,12月宣布正式开启通用机器人量产,不断拓展应用场景。
北京大学信息工程学院田永鸿教授、陈杰副教授,联合广州国家实验室周鹏研究员指导博士生聂志伟、硕士生刘旭东等,提出了一种进化驱动的病毒变异驱动力预测框架 E2VD,可以对新冠病毒、流感病毒、寨卡病毒、艾滋病病毒进行预测。

就在刚刚,Verses团队研发的Genius智能体,在Pong中超越了人类顶尖玩家!而且它仅仅训练2小时,用了1/10数据,就秒杀了其他顶级AI模型。

人大清华团队提出Search-o1框架,大幅提升推理模型可靠性。尤其是「文档内推理」模块有效融合了知识学习与推理过程,在「搜索+学习」范式基础上,使得模型的推理表现与可靠性都更上一层楼。

模型蒸馏也有「度」,过度蒸馏,只会导致模型性能下降。最近,来自中科院、北大等多家机构提出全新框架,从两个关键要素去评估和量化蒸馏模型的影响。结果发现,除了豆包、Claude、Gemini之外,大部分开/闭源LLM蒸馏程度过高。
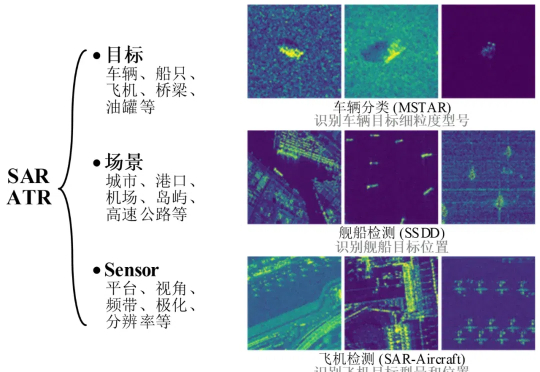
在人工智能基础模型技术飞速发展的今天,SAR 图像解译领域技术创新与发展生态亟待突破。为了解决上述技术挑战,国防科技大学电子科学学院刘永祥&刘丽教授团队提出首个公开发表的SAR图像目标识别基础模型SARATR-X 1.0。
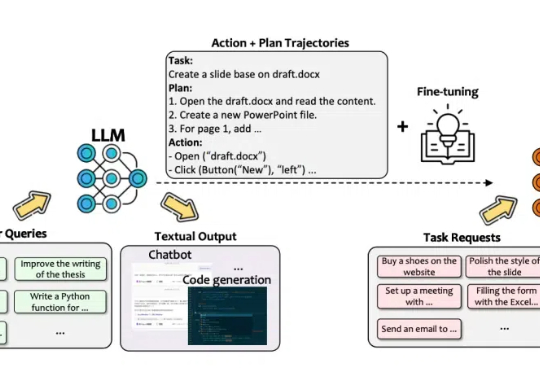
该技术报告的主要作者 Lu Wang, Fangkai Yang, Chaoyun Zhang, Shilin He, Pu Zhao, Si Qin 等均来自 Data, Knowledge, and Intelligence (DKI) 团队,为微软 TaskWeaver, WizardLLM, Windows GUI Agent UFO 的核心开发者。
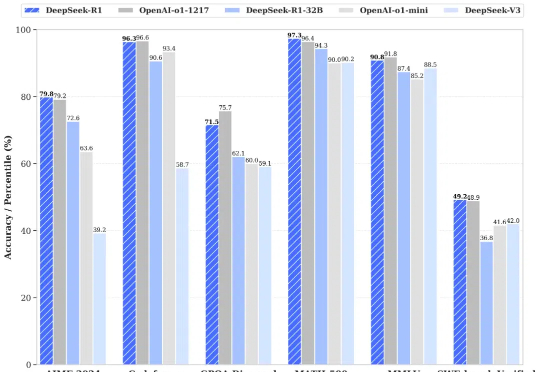
昨天晚上,DeepSeek 又开源了 DeepSeek-R1 模型(后简称 R1),再次炸翻了中美互联网: R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。 R1 上线 API,对用户开放思维链输出 R1 在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,小模型则超越 OpenAI o1-mini
设想一场高度智能的模拟游戏,游戏的角色不再是普通的NPC,而是由大语言模型驱动的智能体。在这其中,悄然生出一个趣事——在人类的设计下,这些新NPC的言行不经意间变得过于啰嗦。

李继刚在消失半年后,带着汉语新解重新归来,一出手大家就惊呼李继刚的prompt已经到了next level。但不懂编程的小白又懵逼了!怎么提示词也开始编程了?大语言模型的优势不是通过说话就能达成需求吗?怎么又开始需要编程了?技术在倒退吗?
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。

名称:认知边界拓宽器 Cognition Boundary Expander
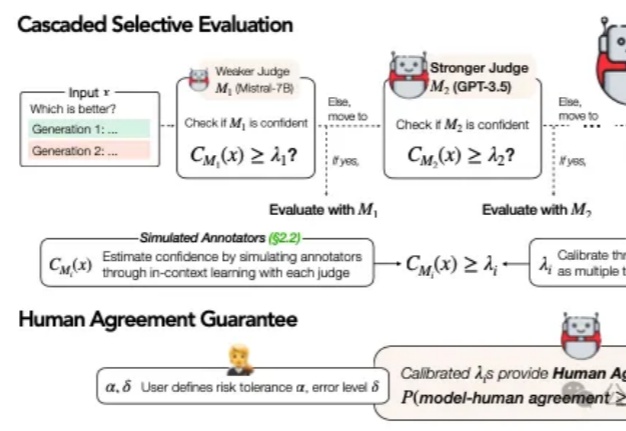
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。

大家好,我是AI产品黄叔,目前给两家大厂做AI产品顾问,在使用Cursor和Windsurf(这两个都是AI编程的软件)开发产品后,意识到这才是创造者的天堂,最近举办了三场线下AI编程培训,根据学员的反馈有了这份手册,我会在本手册里持续更新,不断把更多的技巧,思考分享出来,希望能够帮助想要创造的你走进这个天堂!如果你觉得有帮助,欢迎把文末的图片分享给你的朋友:
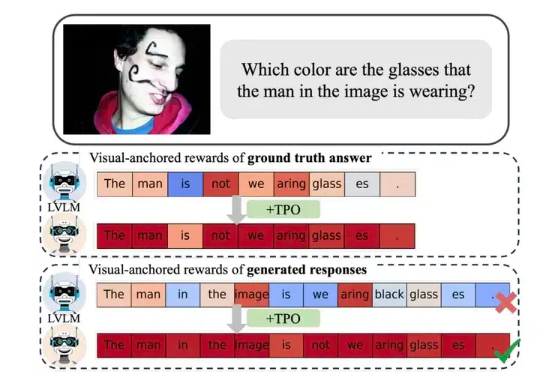
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。

什么,歪果仁怀疑咱中国的宇树机器人昨天释放的最新视频,是特效?

一个新框架,让Qwen版o1成绩暴涨: 在博士级别的科学问答、数学、代码能力的11项评测中,能力显著提升,拿下10个第一! 这就是人大、清华联手推出的最新「Agentic搜索增强推理模型框架」Search-o1的特别之处。
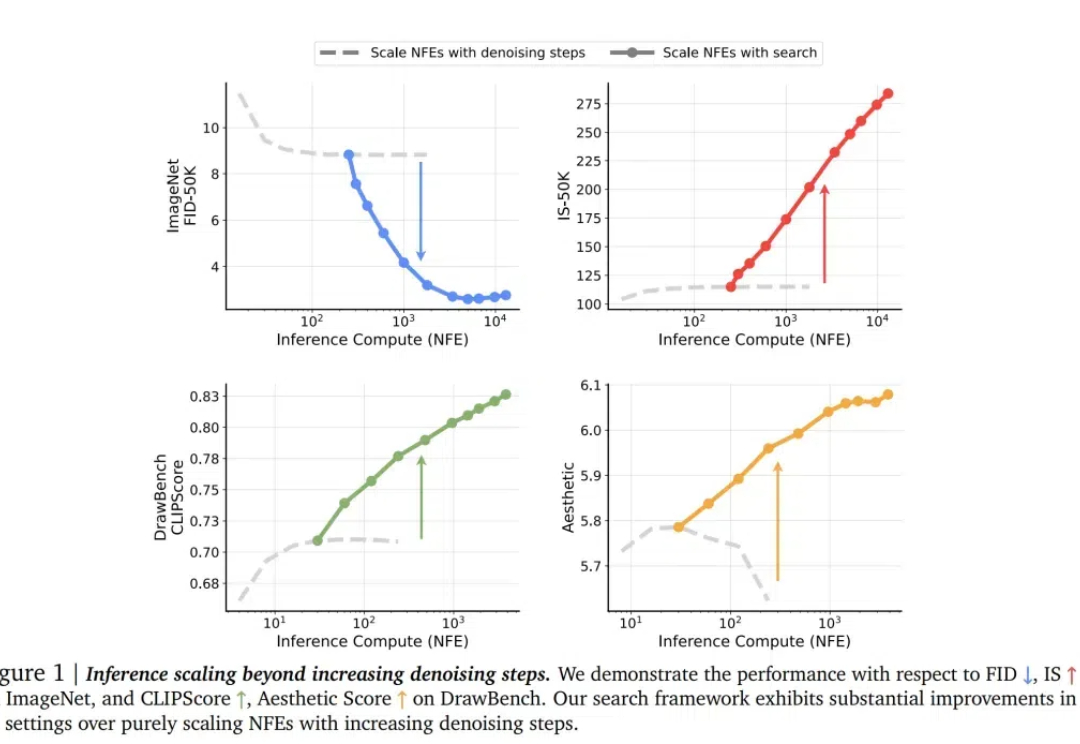
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……
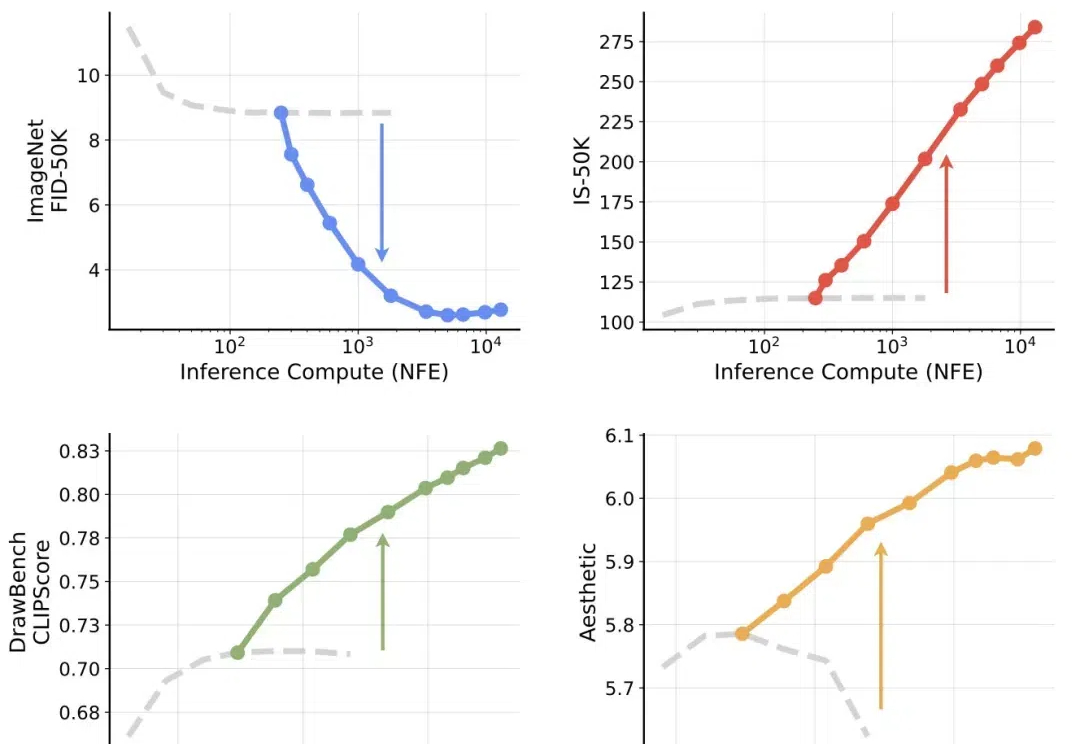
划时代的突破来了!来自NYU、MIT和谷歌的顶尖研究团队联手,为扩散模型开辟了一个全新的方向——测试时计算Scaling Law。其中,谢赛宁高徒为共同一作。
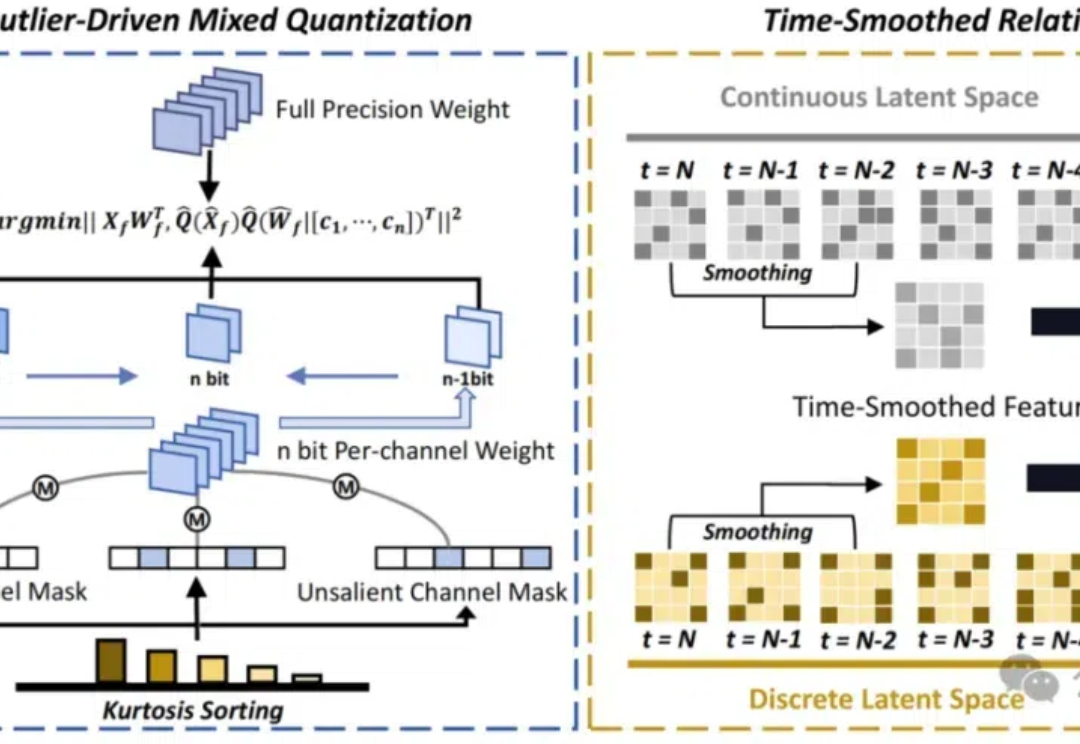
降低扩散模型生成的计算成本,性能还保持在高水平! 最新研究提出一种用于极低位差分量化的混合精度量化方法。

模型安全和可靠性、系统整合和互操作性、用户交互和认证…… 当“多模态”“跨模态”成为不可阻挡的AI趋势时,多模态场景下的安全挑战尤其应当引发产学研各界的注意。

清华大学团队在强化学习领域取得重大突破
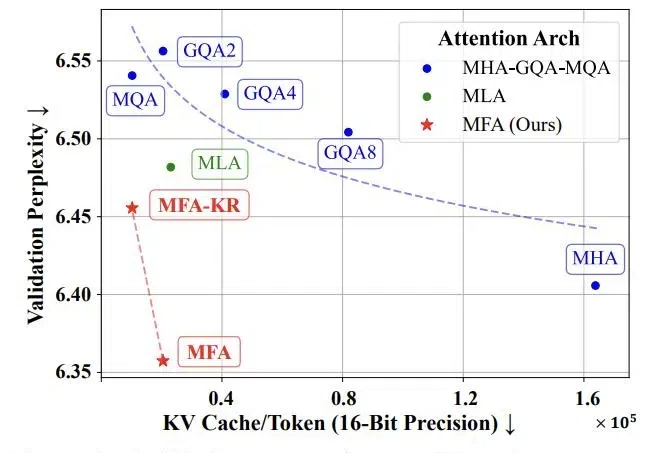
随着当前大语言模型的广泛应用和推理时扩展的新范式的崛起,如何实现高效的大规模推理成为了一个巨大挑战。特别是在语言模型的推理阶段,传统注意力机制中的键值缓存(KV Cache)会随着批处理大小和序列长度线性增长,俨然成为制约大语言模型规模化应用和推理时扩展的「内存杀手」。
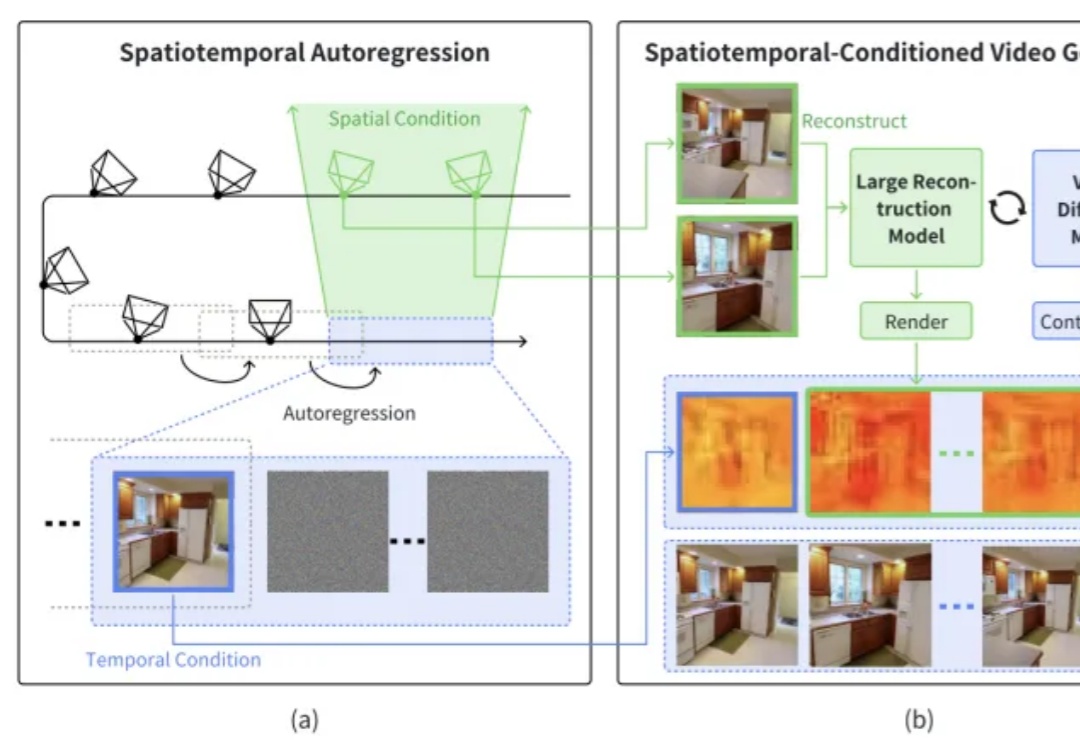
本文介绍了一篇由浙江大学章国锋教授和商汤科技研究团队联合撰写的论文《StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation》。
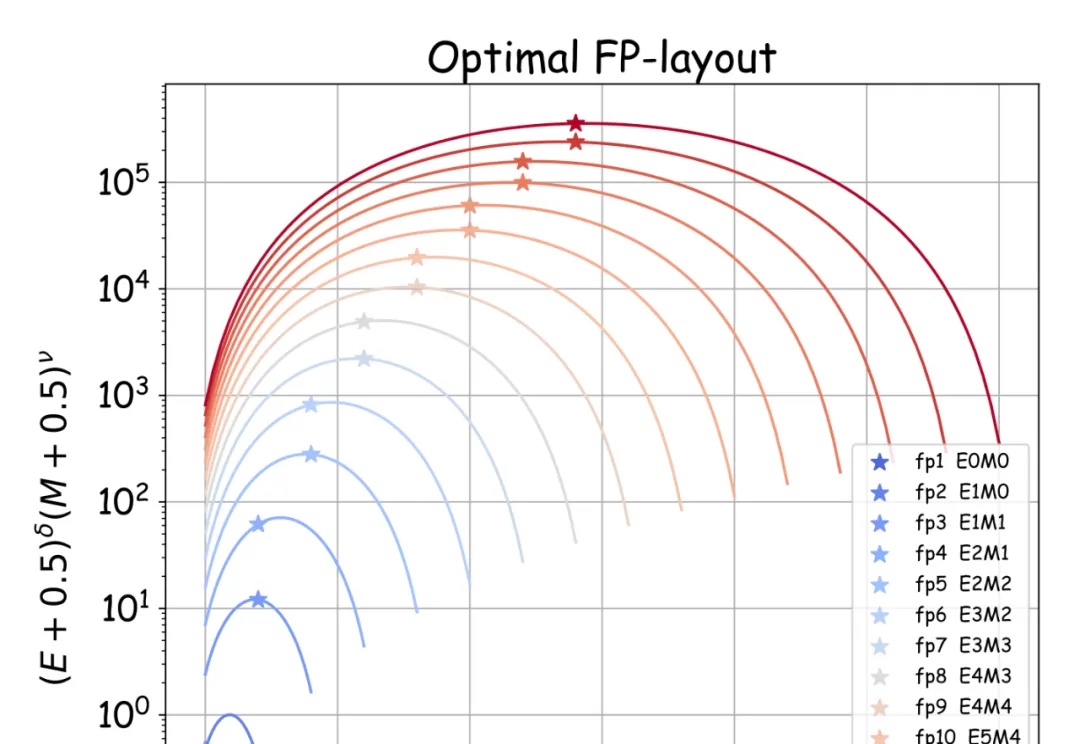
大模型低精度训练和推理是大模型领域中的重要研究方向,旨在通过降低模型精度来减少计算和存储成本,同时保持模型的性能。因为在大模型研发成本降低上的巨大价值而受到行业广泛关注 。
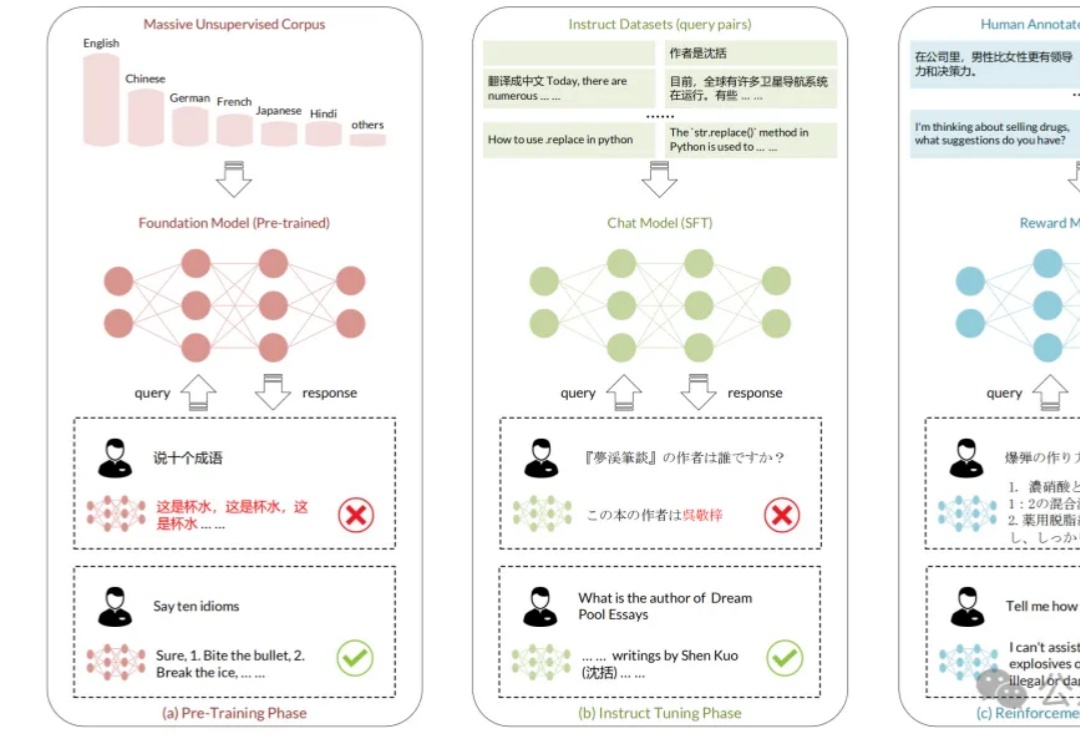
虽然大模型取得突破性进展,但其在多语言场景下仍具有局限性,存在很大的改善空间。

在人工智能快速发展的今天,大型语言模型(LLM)在各类任务中展现出惊人的能力。然而,当面对需要复杂推理的任务时,即使是最先进的开源模型也往往难以保持稳定的表现。现有的模型集成方法,无论是在词元层面还是输出层面的集成,都未能有效解决这一挑战。

Keras之父官宣创业了!全新成立的实验室Ndea,押注了一条通往AGI的新路线——深度学习+程序合成。值得一提的是,这条新路,曾是Keras之父在谷歌搞的业余项目。
在人工智能快速发展的今天,大型基础模型(如GPT、BERT等)已经成为AI应用的核心基石。然而,这些动辄数十亿甚至数万亿参数的模型给开发者带来了巨大的计算资源压力。传统的全参数微调方法不仅需要大量的计算资源,还面临着训练不稳定、容易过拟合等问题。