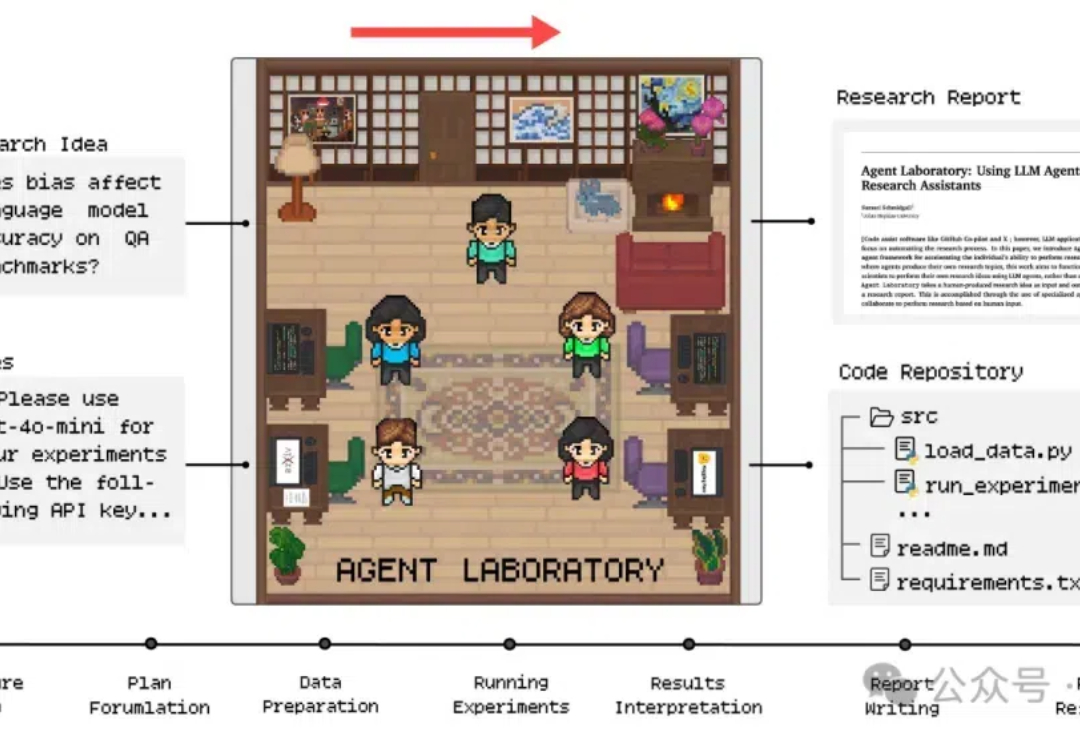
AMD把o1炼成了实验室助手,自动科研经费节省84%
AMD把o1炼成了实验室助手,自动科研经费节省84%芯片强者AMD最新推出科研AI,o1-preview竟成天选打工人?! 注意看,只需将科研idea和相关笔记一股脑丢给AI,研究报告甚至是代码就能立马出炉了。
来自主题: AI技术研报
9792 点击 2025-01-10 16:25
 搜索
搜索
芯片强者AMD最新推出科研AI,o1-preview竟成天选打工人?! 注意看,只需将科研idea和相关笔记一股脑丢给AI,研究报告甚至是代码就能立马出炉了。

2024年11月30日是ChatGPT上线两周年的日子。这个家喻户晓的AI产品是怎样诞生的?展望2025年,ChatGPT又会有怎样的改进?

大连理工大学的研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,克服了传统KL散度在Logit和Feature知识迁移中的局限性,在图像分类和目标检测任务上表现更好。
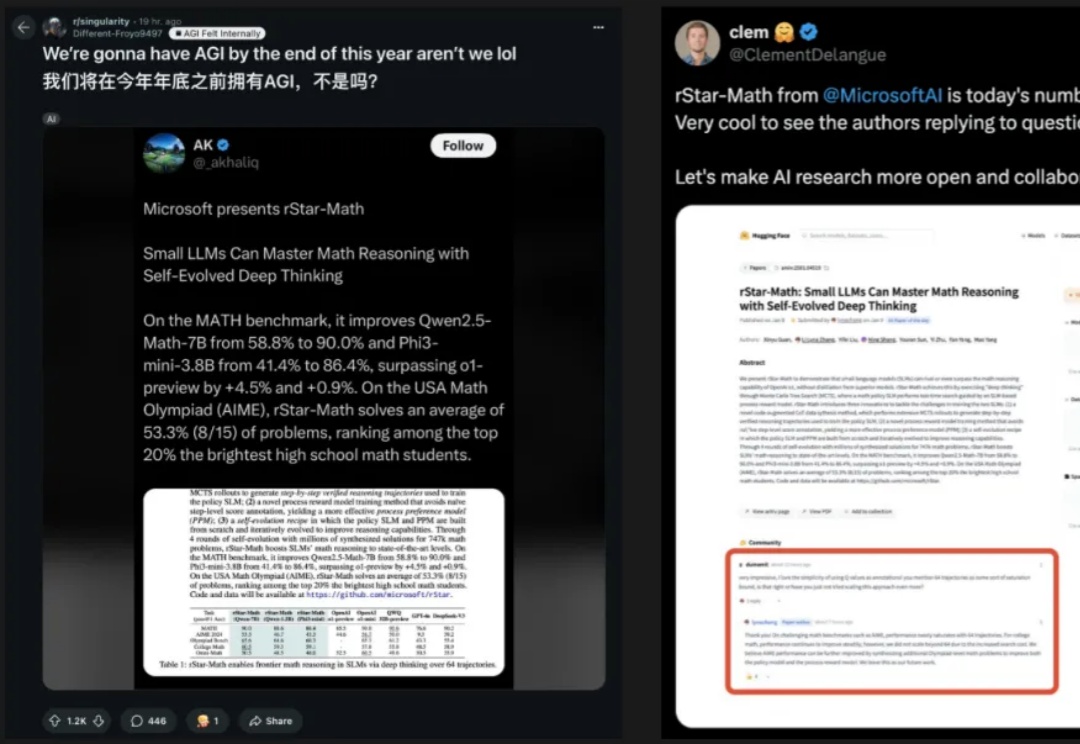
小模型也能击败o1?微软全华人团队提出rStar-Math算法,三大革命性技术突破,不仅让SLM在数学推理能力上刷新SOTA,更是挤进了全美20%顶尖高中生榜单。
通义万相视频模型,再度迎来史诗级升级!处理复杂运动、还原真实物理规律等方面令人惊叹,甚至业界首创了汉字视频生成。现在,通义万相直接以84.70%总分击败了一众顶尖模型,登顶VBench榜首。

最新综述论文探讨了知识蒸馏在持续学习中的应用,重点研究如何通过模仿旧模型的输出来减缓灾难性遗忘问题。通过在多个数据集上的实验,验证了知识蒸馏在巩固记忆方面的有效性,并指出结合数据回放和使用separated softmax损失函数可进一步提升其效果。
10个AI领域,50篇精品论文,每周看一篇,到2026就能成「AI工程」专家!

今天,银河通用机器人发布了端到端具身抓取基础大模型「GraspVLA」,全球第一个预训练完全基于仿真合成大数据的具身大模型,展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。
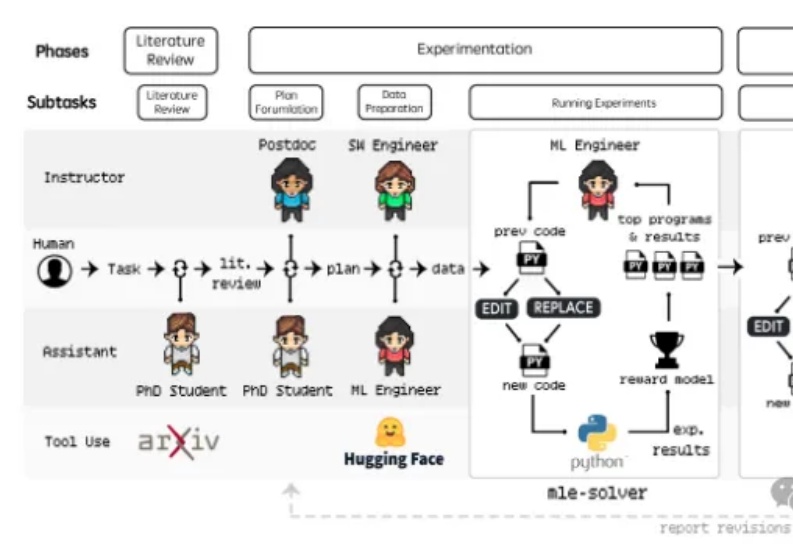
发表于昨天的论文《Agent Laboratory: Using LLM Agents as Research Assistants》对于科研界具有划时代意义,过去几周才能完成的科研任务现在仅需20分钟到一两个小时左右(不同LLM),花费2-13个美金的Token即可完成!

检索-增强生成 (RAG) 是一个永不过时的话题,并在不断扩展以增强LLMs 的功能。对于那些不太熟悉RAG 的人来说:这种方法利用外部知识来增强模型的能力,从外部资源中检索您实际需要的信息。

电子表格也迎来了自己的ChatGPT时刻。 就在这两天,一个名为TabPFN的表格处理模型登上Nature,随后在数据科学领域引发热烈讨论。

2025 年来了,3D 生成也迎来了新突破。 刚刚,Stability AI 在 CES 上宣布为 3D 生成推出一种两阶段新方法 ——SPAR3D(Stable Point Aware 3D),旨在为游戏开发者、产品设计师和环境构建者开拓 3D 原型设计新方式。
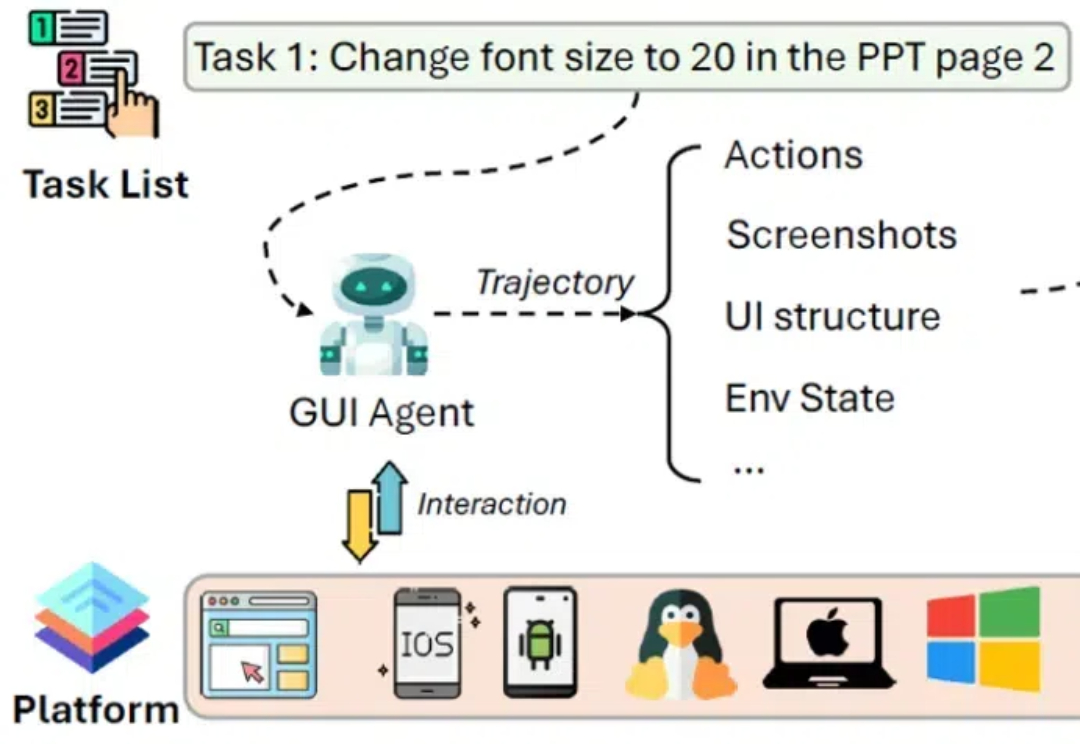
图形用户界面(Graphical User Interface, GUI)作为数字时代最具代表性的创新之一,大幅简化了人机交互的复杂度。

如何让机器人在任务指引和实时观测的基础上规划未来动作,一直是具身智能领域的核心科学问题。

Aria-UI通过纯视觉理解,实现了GUI指令的精准定位,无需依赖后台数据,简化了部署流程;在AndroidWorld和OSWorld等权威基准测试中表现出色,分别获得第一名和第三名,展示了强大的跨平台自动化能力。
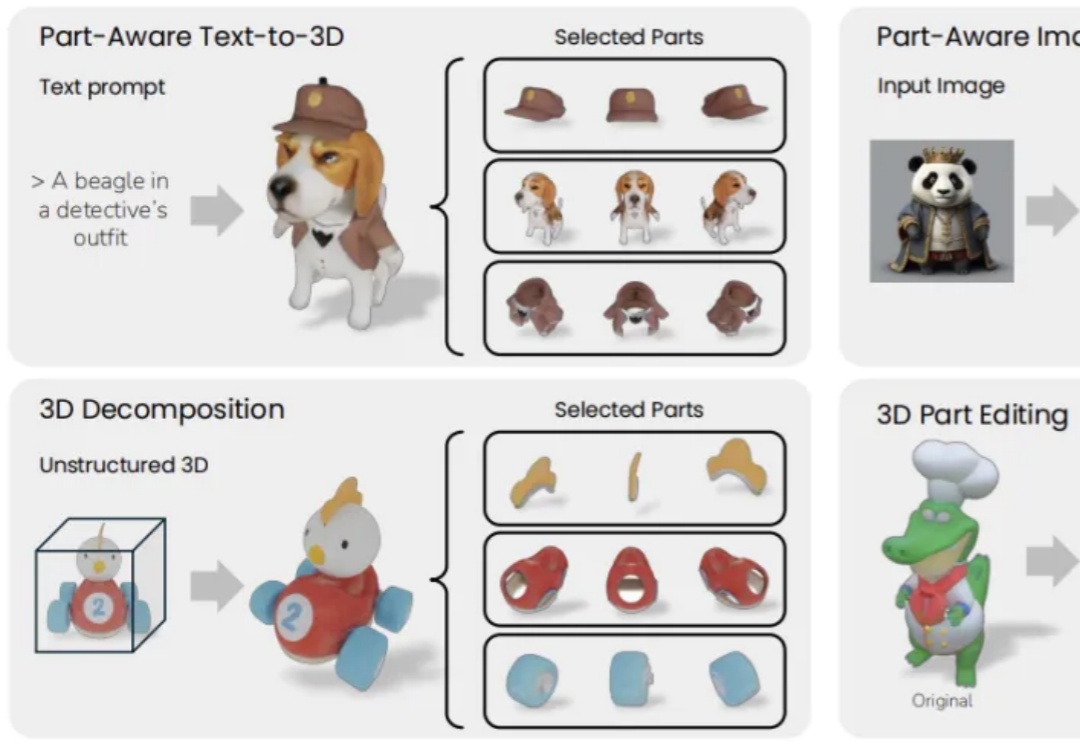
对于专业应用和创意工作流来说,除了高质量的形状和纹理,更需要可以独立操作的「零部件级3D模型」。为此,Meta与牛津大学的研究人员推出了全新的多视图扩散模型。
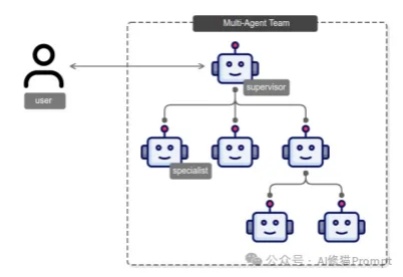
随着大语言模型(LLM)技术的快速发展,单一AI智能体已经展现出强大的问题解决能力。然而,在面对复杂的企业级应用场景时,单一智能体的能力往往显得捉襟见肘。
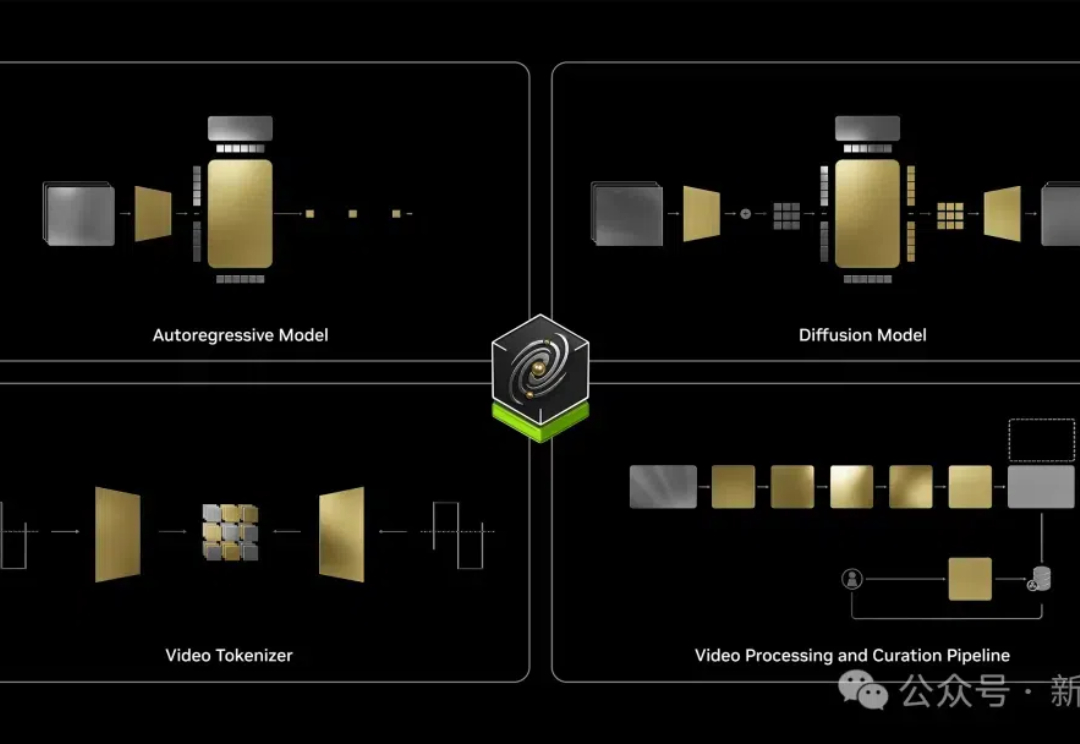
昨天,英伟达官宣了首个「世界基础模型」Cosmos。从此,物理AI数据不够的问题将有望解决!而就在刚刚,75页技术报告火热出炉,GitHub项目更是冲破了2k星。
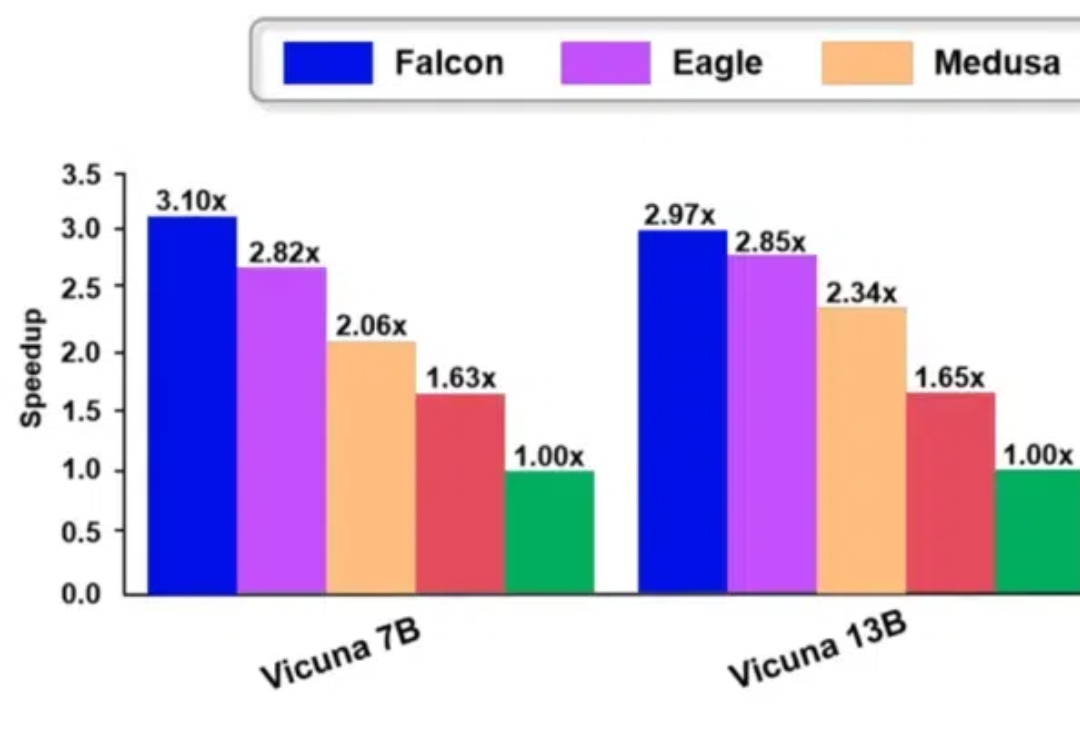
Falcon 方法是一种增强半自回归投机解码框架,旨在增强 draft model 的并行性和输出质量,以有效提升大模型的推理速度。Falcon 可以实现约 2.91-3.51 倍的加速比,在多种数据集上获得了很好的结果,并已应用到翼支付多个实际业务中。
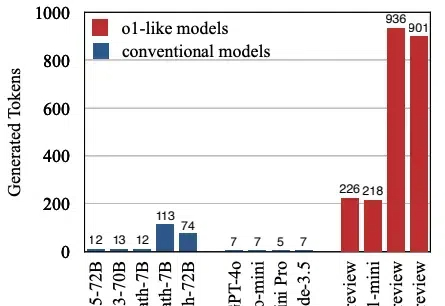
本文将介绍首个关于 o1 类长思维链模型过度思考现象。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。

这份《2024年AI应用行业年度报告》是由Xsignal打造的AI年终盘点大餐。全报告共78页,数据之翔实和页面之精美程度冠绝2024。添加客服微信 openai178,免费获取完整PDF。

1/10训练数据激发高级推理能力!近日,来自清华的研究者提出了PRIME,通过隐式奖励来进行过程强化,提高了语言模型的推理能力,超越了SFT以及蒸馏等方法。
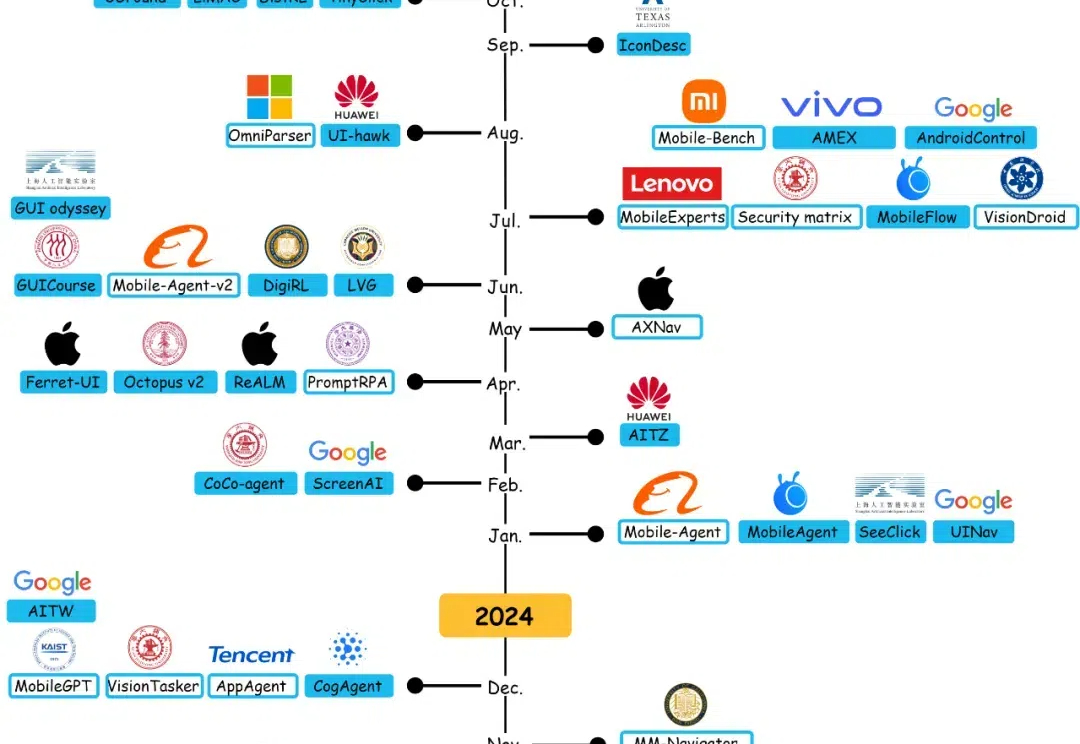
最近国内外的手机厂商和 AI 公司纷纷发布了手机 AI 智能体相关产品,让曾经的幻想逐渐有了可行性。

在人类的认知中,从单张图像中感知并想象三维世界是一项天然的能力。我们能直观地估算距离、形状,猜想被遮挡区域的几何信息。然而,将这一复杂的认知过程赋予机器却充满挑战。
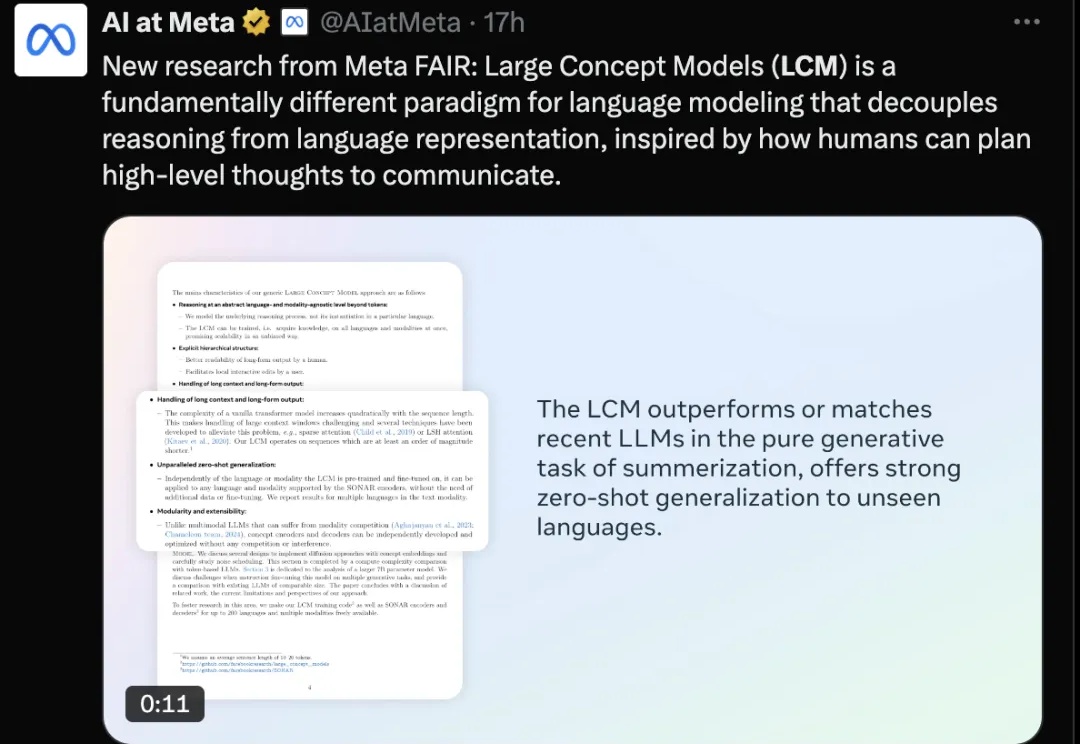
Meta提出大概念模型,抛弃token,采用更高级别的「概念」在句子嵌入空间上建模,彻底摆脱语言和模态对模型的制约。
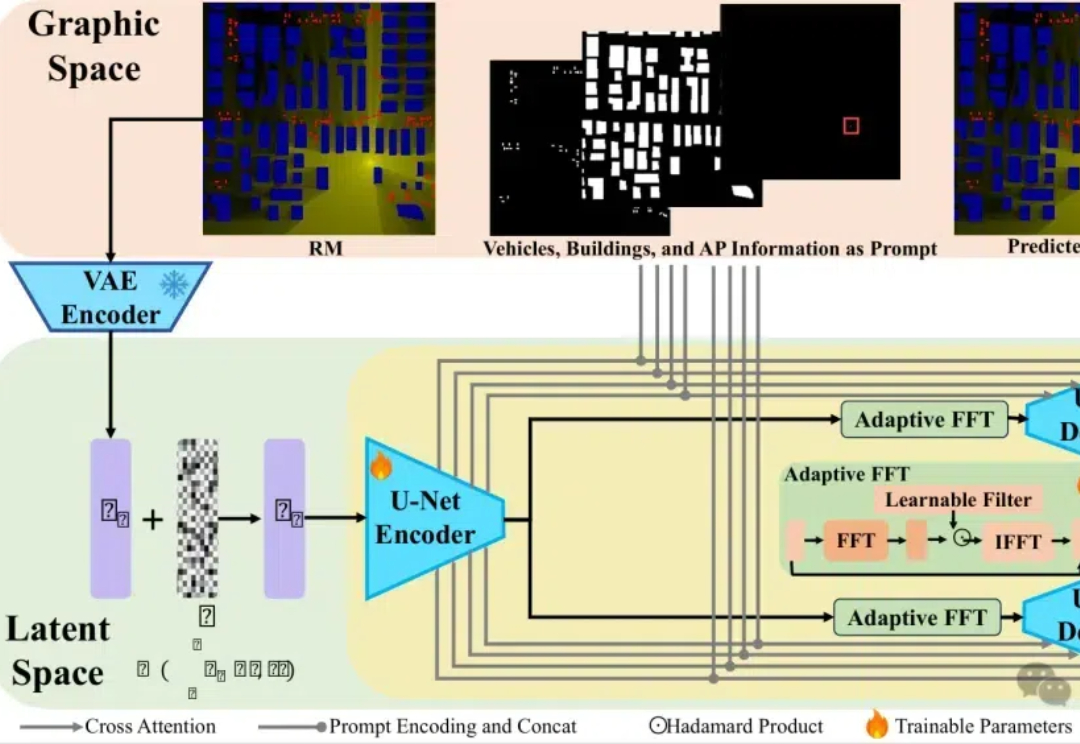
西安电子科技大学等首次通过理论分析揭示了无线电地图构建是生成问题,并提出RadioDiff模型,在无采样动态无线电地图构建的准确性、结构相似度和峰值信噪比三大指标上全面领先。
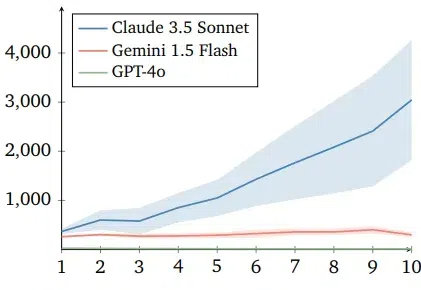
智能体在模拟人类合作行为的捐赠者游戏中表现出不同策略,其中Claude 3.5智能体展现出更有效的合作和惩罚搭便车行为的能力,而Gemini 1.5 Flash和GPT-4o则表现得更自私,结果揭示了不同LLM智能体在合作任务中的道德和行为差异,对未来人机协同社会具有重要意义。
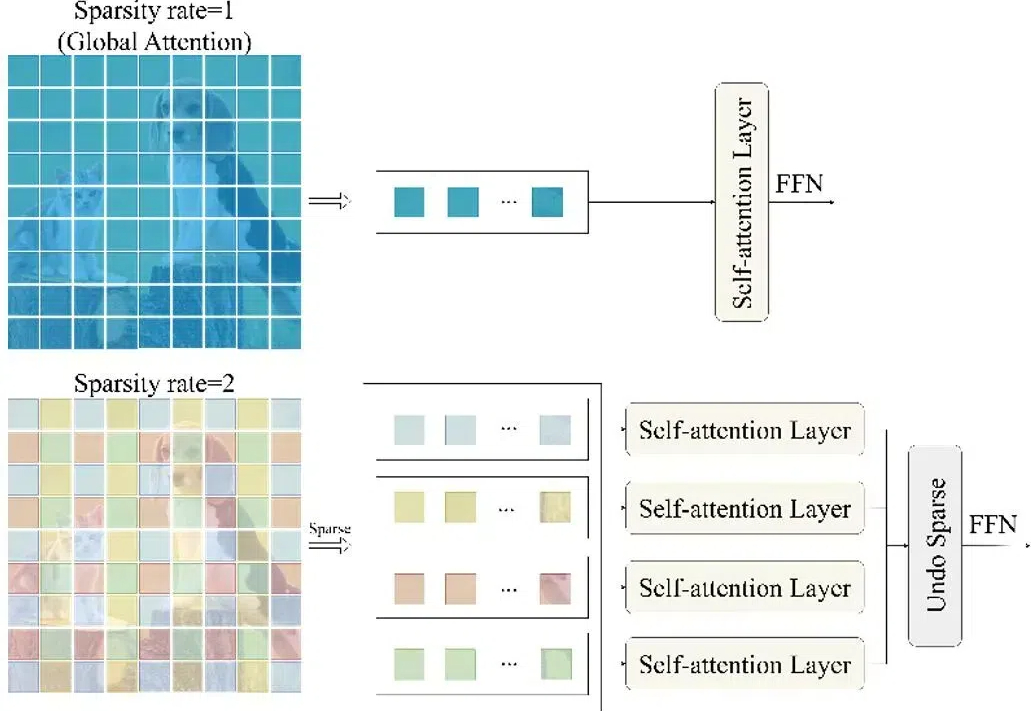
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。
在人工智能领域,大语言模型(LLMs)展现出了令人惊叹的能力,但在因果推理这一人类智能的核心能力上仍面临重大挑战。特别是在从相关性信息推断因果关系这一任务上,现有的大语言模型表现出明显的不足。

OpenAI o1和o3模型的秘密,竟传出被中国研究者「破解」?今天,复旦等机构的这篇论文引起了AI社区的强烈反响,他们从强化学习的角度,分析了实现o1的路线图,并总结了现有的「开源版o1」。