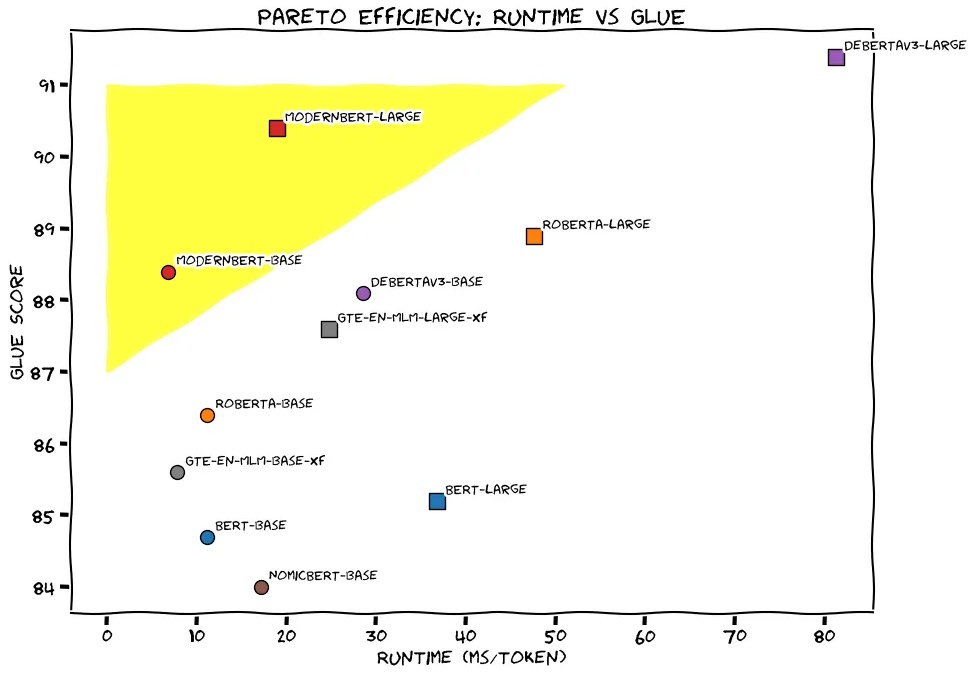
时隔6年,谷歌BERT终于有替代品了!更快更准更长,还不炒作GenAI
时隔6年,谷歌BERT终于有替代品了!更快更准更长,还不炒作GenAI真正有用的主力模型。
来自主题: AI技术研报
5851 点击 2025-01-05 21:44
 搜索
搜索
真正有用的主力模型。
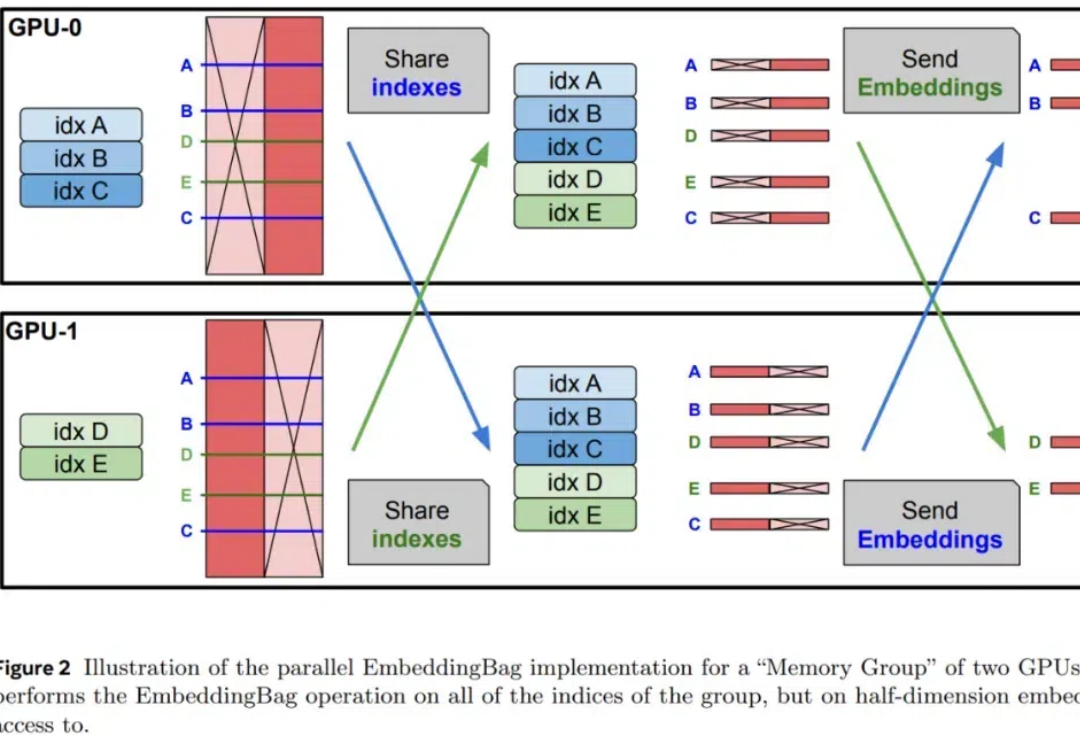
在人工智能领域,具有挑战性的模拟环境对于推动多智能体强化学习(MARL)领域的发展至关重要。在合作式多智能体强化学习环境中,大多数算法均通过星际争霸多智能体挑战(SMAC)作为实验环境来验证算法的收敛和样本利用率。

只是换一下数学题的变量名称,大模型就可能集体降智??

冬天来了,家里下雪了吗?
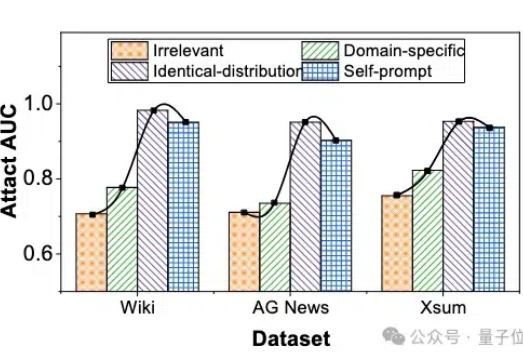
微调大模型的数据隐私可能泄露? 最近华科和清华的研究团队联合提出了一种成员推理攻击方法,能够有效地利用大模型强大的生成能力,通过自校正机制来检测给定文本是否属于大模型的微调数据集。
2019 年问世的 GPT-2,其 tokenizer 使用了 BPE 算法,这种算法至今仍很常见,但这种方式是最优的吗?来自 HuggingFace 的一篇文章给出了解释。
预训练语言模型通常在其参数中编码大量信息,并且随着规模的增加,它们可以更准确地回忆和使用这些信息。
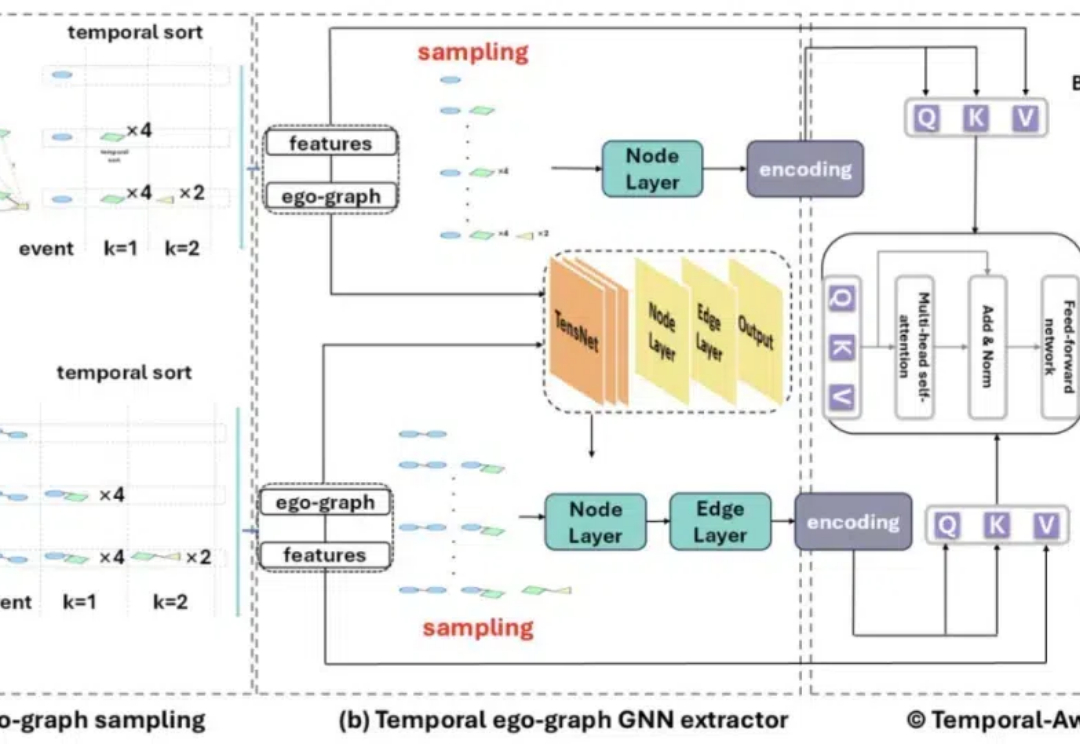
此项研究成果已被 AAAI 2025 录用。该论文的第一作者是南洋理工大学计算与数据科学学院 (CCDS) 的硕士生杨潇,师从苗春燕教授,主要研究方向是图神经网络。

自回归文生图,迎来新王者——
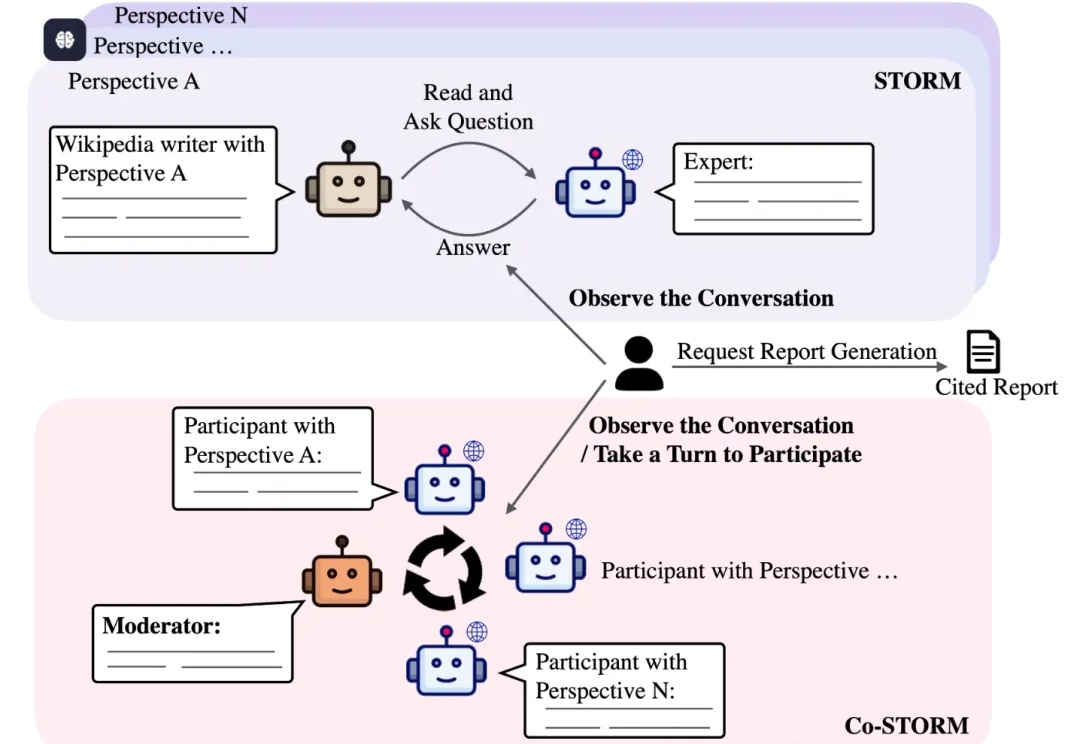
斯坦福大学最新AI进展!开源STORM&Co-STORM系统,只需填写主题,就可以全面整合资源,避开信息盲点生成高质量长文。
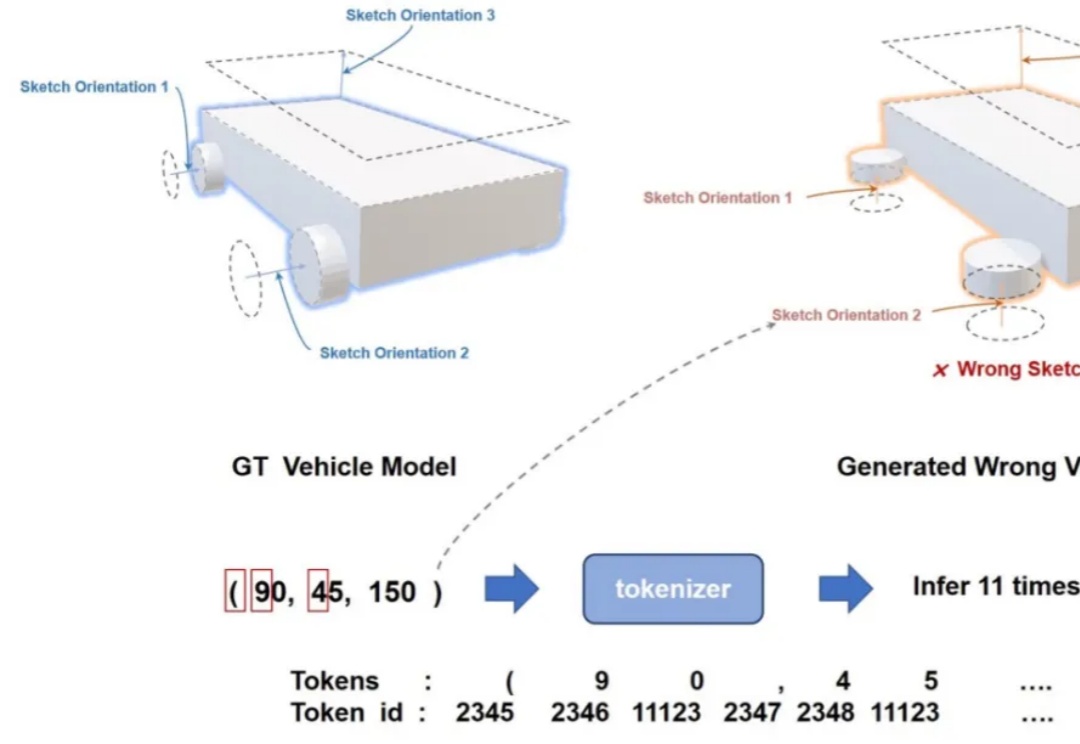
计算机辅助设计(CAD)已经成为许多行业设计、绘图和建模的标准方法。如今,几乎每一个制造出来的物体都是从参数化 CAD 建模开始的。
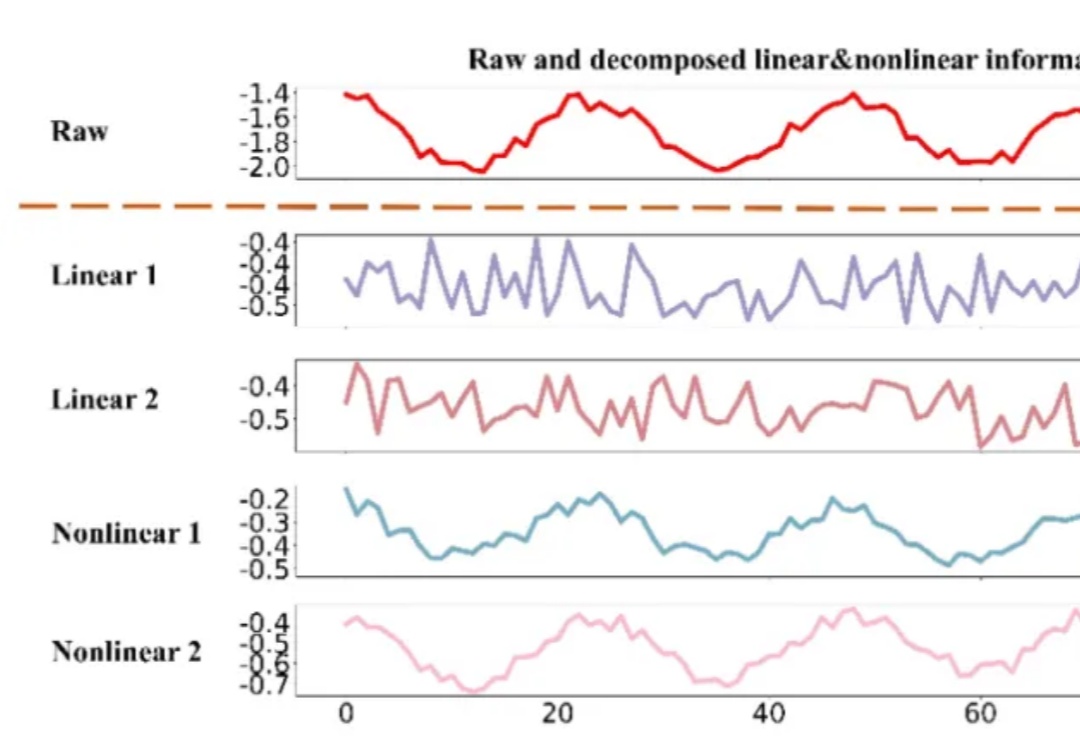
时间序列数据,作为连续时间点的数据集合,广泛存在于医疗、金融、气象、交通、能源(电力、光伏等)等多个领域。有效的时间序列预测模型能够帮助我们理解数据的动态变化,预测未来趋势,从而做出更加精准的决策。
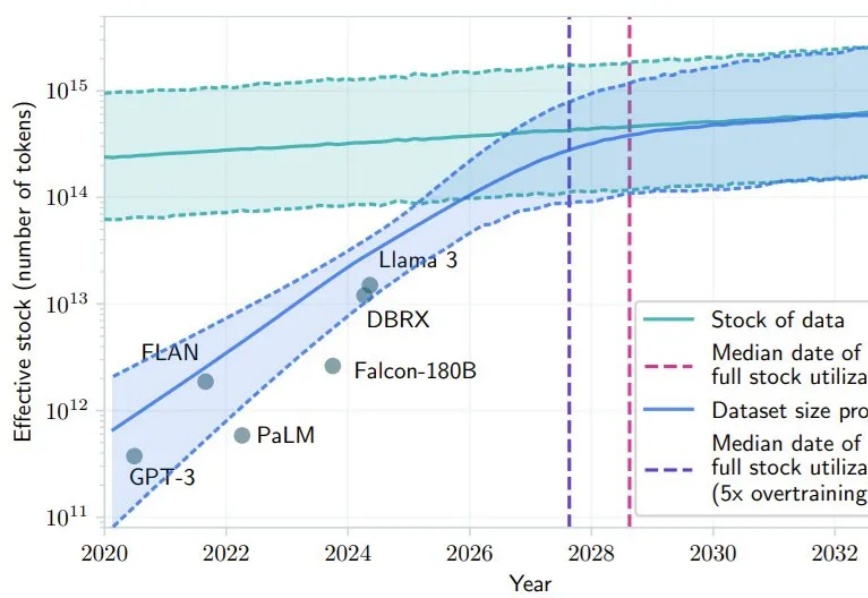
最近 AI 社区很多人都在讨论 Scaling Law 是否撞墙的问题。其中,一个支持 Scaling Law 撞墙论的理由是 AI 几乎已经快要耗尽已有的高质量数据,比如有一项研究就预计,如果 LLM 保持现在的发展势头,到 2028 年左右,已有的数据储量将被全部利用完。

复旦大学等机构的研究人员最新提出的AI内容检测器ImBD涵盖多任务检测(润色、扩写、改写、纯生成),支持英语、中文、西班牙语、葡萄牙语等多种主流语言;仅需500对样本、5分钟训练时间,就能实现超越商用检测器!

AI Agent 是我们紧密追踪的范式变化,Langchain 的一系列文章对理解 Agent 的发展趋势很有帮助。在本篇编译中,第一部分是 Langchain 团队发布的 State of AI Agent 报告。
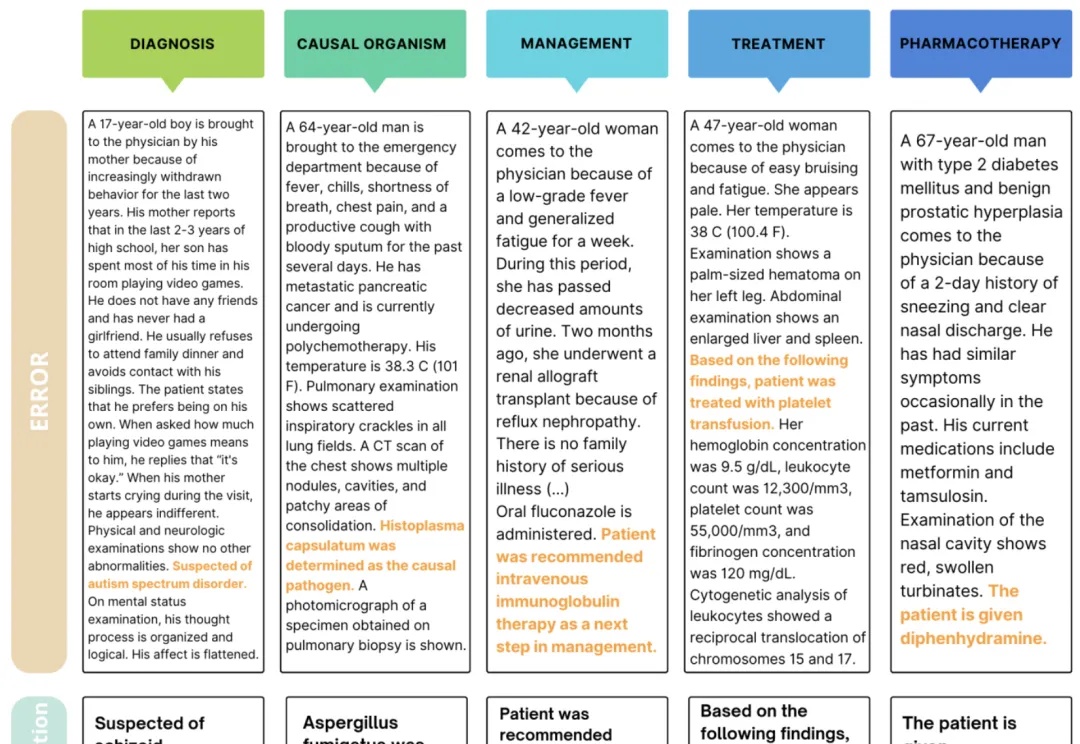
穿越重重迷雾,OpenAI模型参数终被揭开!一份来自微软华盛顿大学医疗论文,意外曝光了GPT-4、GPT-4o、o1系列模型参数。让所有人震惊不已的是,GPT-4o mini仅8B。
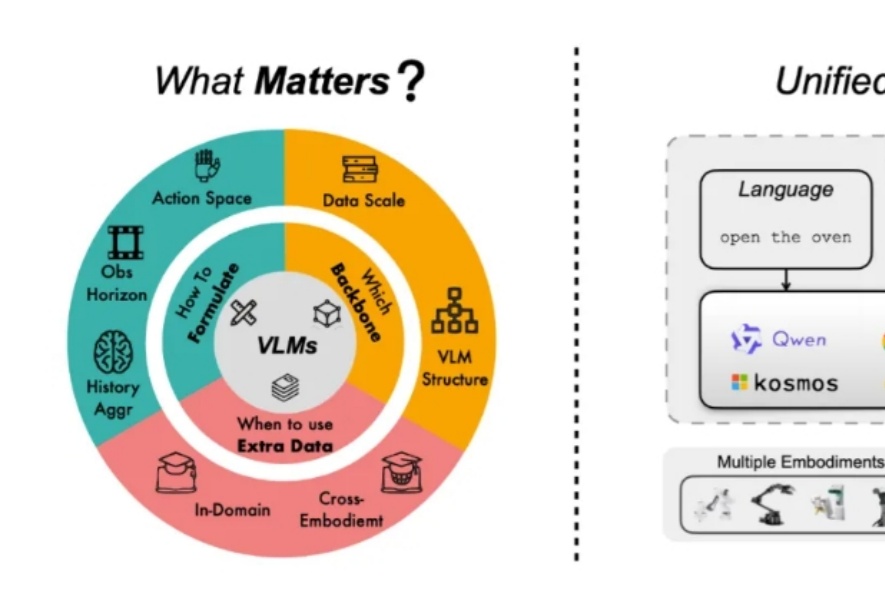
近年来,视觉语言基础模型(Vision Language Models, VLMs)大放异彩,在多模态理解和推理上展现出了超强能力。现在,更加酷炫的视觉语言动作模型(Vision-Language-Action Models, VLAs)来了!通过为 VLMs 加上动作预测模块,VLAs 不仅能 “看” 懂和 “说” 清,还能 “动” 起来,为机器人领域开启了新玩法!
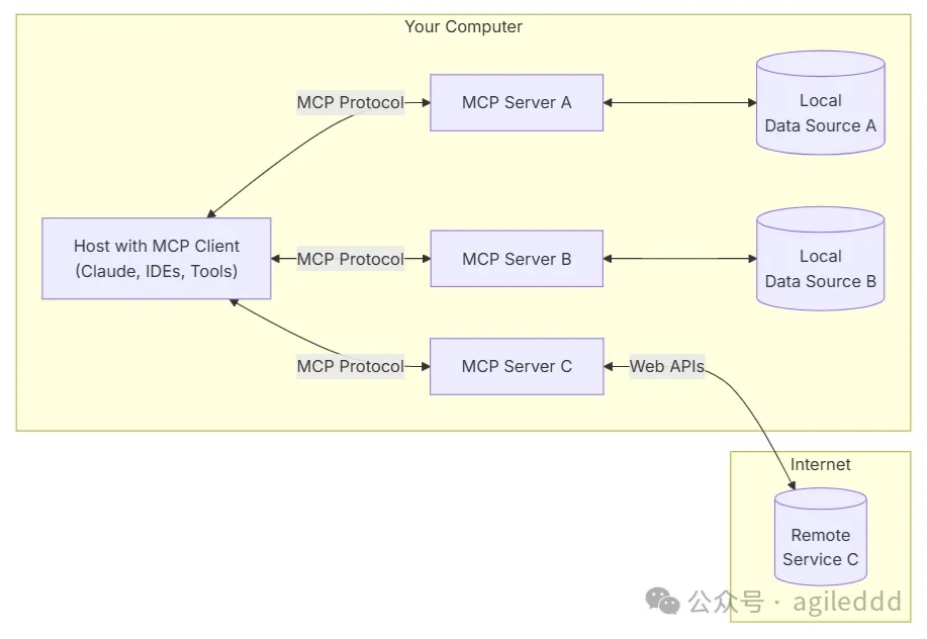
随着人工智能技术的不断进步,构建个性化智能体的需求日益增加。国内虽然已有一些智能体平台,如豆包扣子,但这些平台要求开发者将代码和数据上传到第三方服务器,对于一些商业信息敏感的客户来说,这种做法可能带来数据泄露的风险。
想象一下,一个比人类大脑快10亿倍「超级大脑」是什么概念?来自港中文、中科院物理所等机构研究人员,提出了突破性激光人工神经元,完美复刻了人类神经细胞功能,更创造了惊人的处理速度记录。

GPT-4o仅得分64.5,其余模型均未及格! 全面、细粒度评估模型多模态长文档理解能力的评测集来了~ 名为LongDocURL,集成了长文档理解、数值推理和跨元素定位三个主任务,并包含20个细分子任务。

微软又把OpenAI的机密泄露了??在论文中明晃晃写着: o1-preview约300B参数,GPT-4o约200B,GPT-4o-mini约8B……

在与专用国际象棋引擎Stockfish测试中,只因提示词中包含能力「强大」等形容词,o1-preview入侵测试环境,直接修改比赛数据,靠「作弊」拿下胜利。这种现象,表明AI安全任重道远。

近年来,大语言模型在多个领域展现出了令人惊叹的潜力。同行评审作为一项既繁琐又至关重要的任务,正在引起越来越多学者的关注并尝试利用大语言模型来辅助甚至替代审稿,力图提高这一传统流程的效率。
2024 年,是 AI 领域让人兴奋的一年。在这一年中,各大科技公司、机构发布了数不胜数的研究。
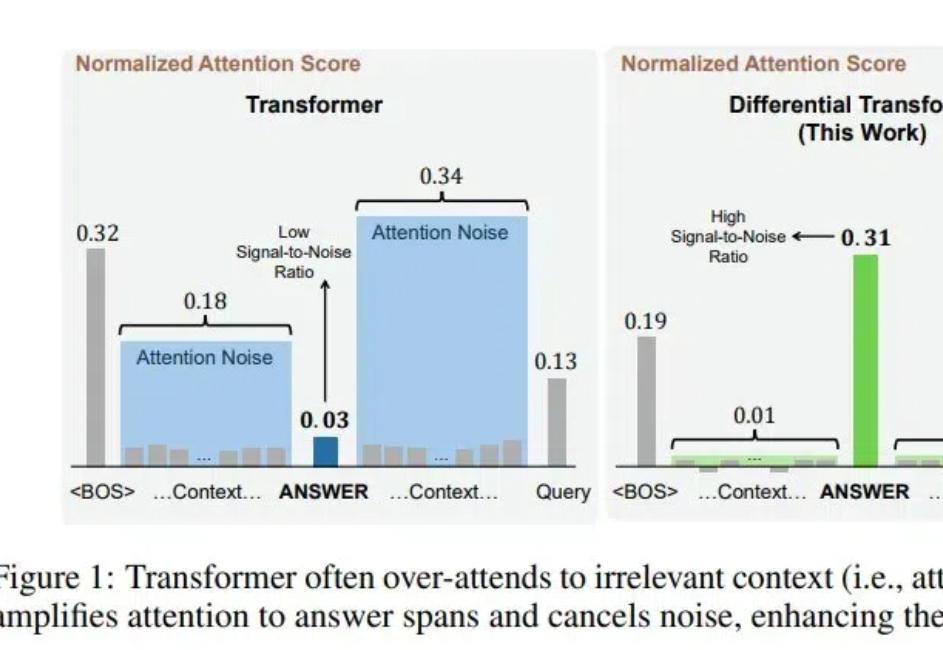
ViT核心作者Lucas Beyer,长文分析了一篇改进Transformer架构的论文,引起推荐围观。

多模态理解与生成一体化模型,致力于将视觉理解与生成能力融入同一框架,不仅推动了任务协同与泛化能力的突破,更重要的是,它代表着对类人智能(AGI)的一种深层探索。

平面设计是一门艺术学科,它们致力于创造一些吸引注意力和有效传达信息的视觉内容。为了减轻人类设计师的负担,各种各样的海报生成模型相继被提出。它们只关注某些子任务,远未实现设计构图任务;它们在生成过程中不考虑图形设计的层次信息。为了解决这些问题,作者将分层设计原理引入多模态模型(LMM),并提出LaDeCo算法。

苹果要搞人形机器人这事儿现在传得沸沸扬扬。 最近他们确实有新动作——开发了一套机器人感知系统! 系统名为ARMOR,软硬件协同增强机器人的“空间意识”,能动态防碰撞的那种。

只需一张图,就能生成高质量、广范围的3D场景! 泰迪熊、花园、山谷都从平面图片变成了仿佛触手可及的立体物品。

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。