
迈向多语言医疗大模型:大规模预训练语料、开源模型与全面基准测试
迈向多语言医疗大模型:大规模预训练语料、开源模型与全面基准测试在医疗领域中,大语言模型已经有了广泛的研究。然而,这些进展主要依赖于英语的基座模型,并受制于缺乏多语言医疗专业数据的限制,导致当前的医疗大模型在处理非英语问题时效果不佳。
来自主题: AI技术研报
10135 点击 2024-09-29 22:38
 搜索
搜索
在医疗领域中,大语言模型已经有了广泛的研究。然而,这些进展主要依赖于英语的基座模型,并受制于缺乏多语言医疗专业数据的限制,导致当前的医疗大模型在处理非英语问题时效果不佳。

在人工智能技术发展最快的美国,人们对生成式人工智能的使用情况怎样? 美国全国经济研究所(NBER)日前发布的最新一篇工作论文《The Rapid Adoption of Generative AI》给出了答案。NBER是美国最大的经济学研究组织,其发布的工作论文代表着经济学研究最新的成果。

想参加陶哲轩发起的「众包」数学研究项目吗? 机会来了!
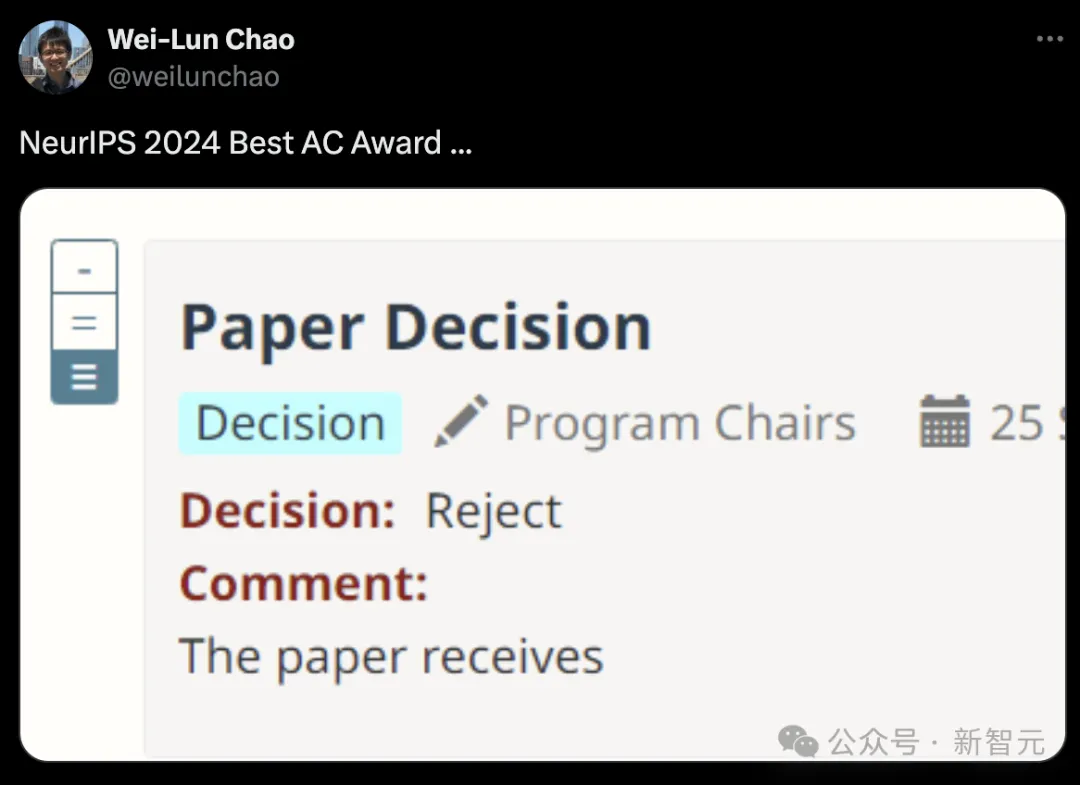
NeurIPS 2024评审结果已经公布了! 收到邮件的小伙伴们,就像在开盲盒一样,纷纷在社交媒体上晒出了自己的成绩单。
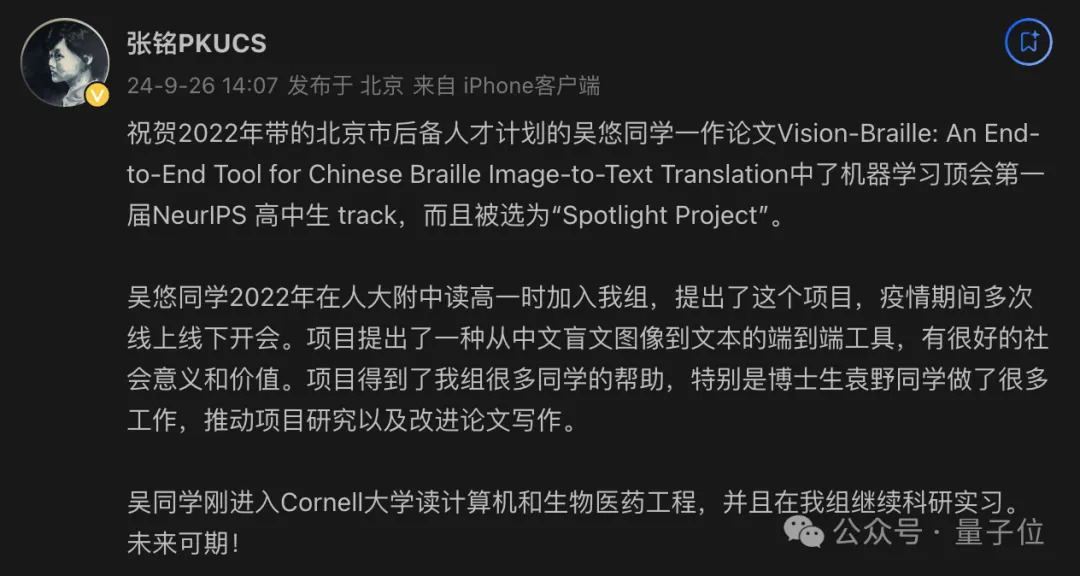
NeurIPS 2024放榜,人大附中有高中生一作入选。
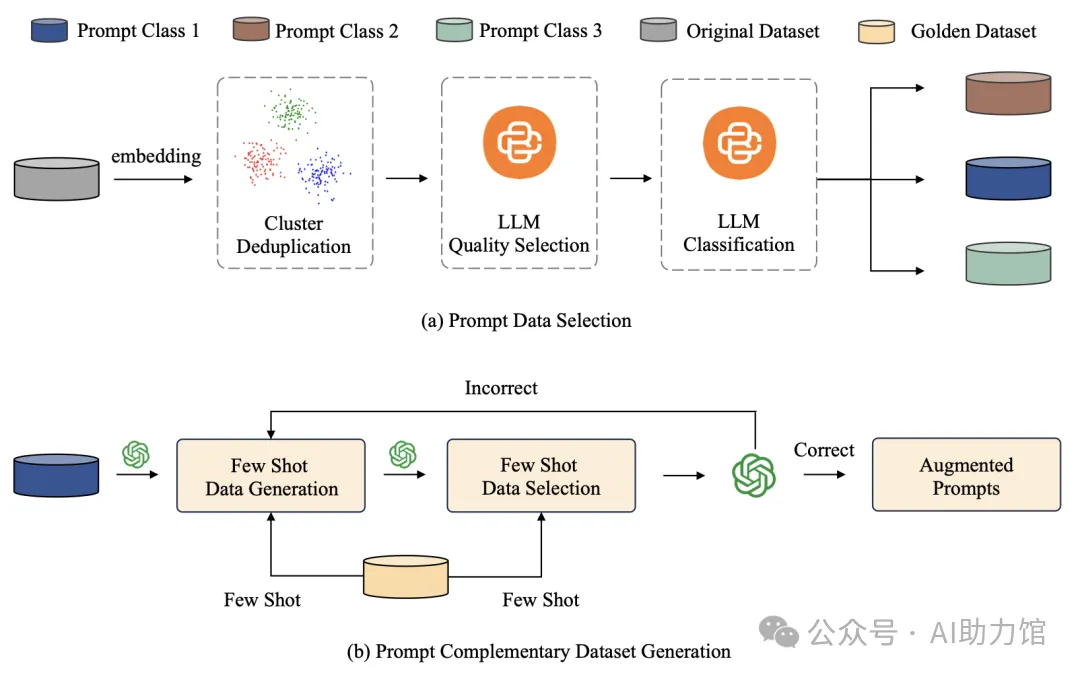
在人工智能的世界里,大型语言模型(LLM)已经成为我们探索未知、解决问题的得力助手。但是,你在编写AI提示词时,是否觉得这个过程就像在“炼丹”,既神秘又难以掌握?别担心,自动提示工程(APE)来帮你了!
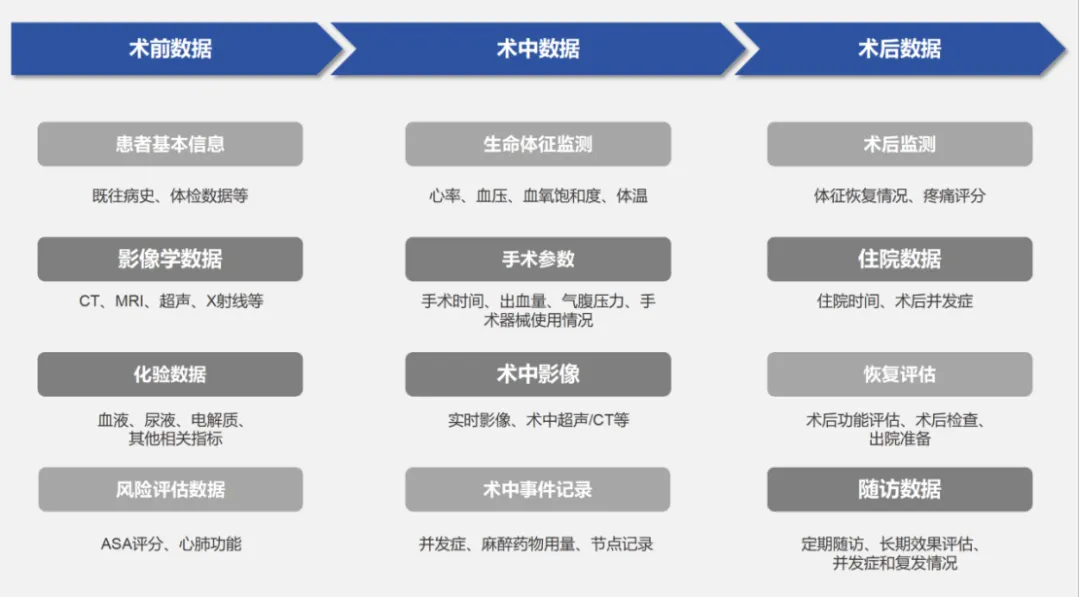
外科医生Dr. Lee在一次美敦力的学术讨论上说到,“外科医生和精英运动员非常相似,都在团队环境中工作,不断的重复训练已达到顶尖的成绩。但运动员往往花费更多的时间在影像室,回顾和研究过去的表现。而医生目前还没有得到足够、及时的信息反馈,以学习和提升手术技能。”

在这种背景下,研究团队提出了一个全新的框架:SubgoalXL,结合了子目标(subgoal)证明策略与专家学习(expert learning)方法,在 Isabelle 中实现了形式化定理证明的性能突破。

香港中文大学等机构的研究团队通过深度强化学习(DQN)开发了一种3D打印路径规划器,有效提升了打印效率和精度,为智能制造开辟了新途径。

Google DeepMind的SCoRe方法通过在线多轮强化学习,显著提升了大型语言模型在没有外部输入的情况下的自我修正能力。该方法在MATH和HumanEval基准测试中,分别将自我修正性能提高了15.6%和9.1%。
谷歌的AlphaChip,几小时内就能设计出芯片布局,直接碾压人类专家!这种超人芯片布局,已经应用在TPU、CPU在内的全球硬件中。人类设计芯片的方式,已被AI彻底改变。

通往AGI的路径只有一条吗?实则不然。这家国产AI黑马认为,「群体智能」或许是一种最佳的尝试。他们正打破惯性思维,打造出最强AI大脑,要让世界每一台设备都有自己的智能。

2024年,生成式人工智能技术正引领客户联络中心经历一场革命性变革。客户服务和支持的重要性对企业不言而喻,卓越的客户体验尤其是当下激烈竞争的市场环境中企业制胜的关键。
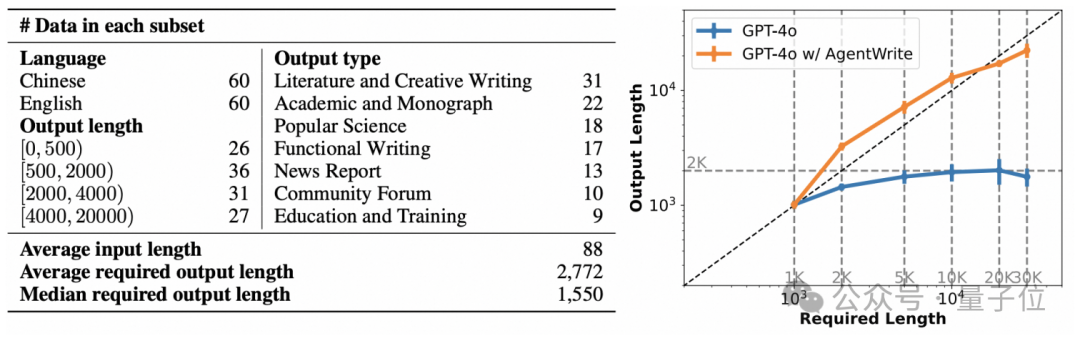
仅需600多条数据,就能训练自己的长输出模型了?!

服务器CPU领域持续多年的核心数量大战,被一举终结了!
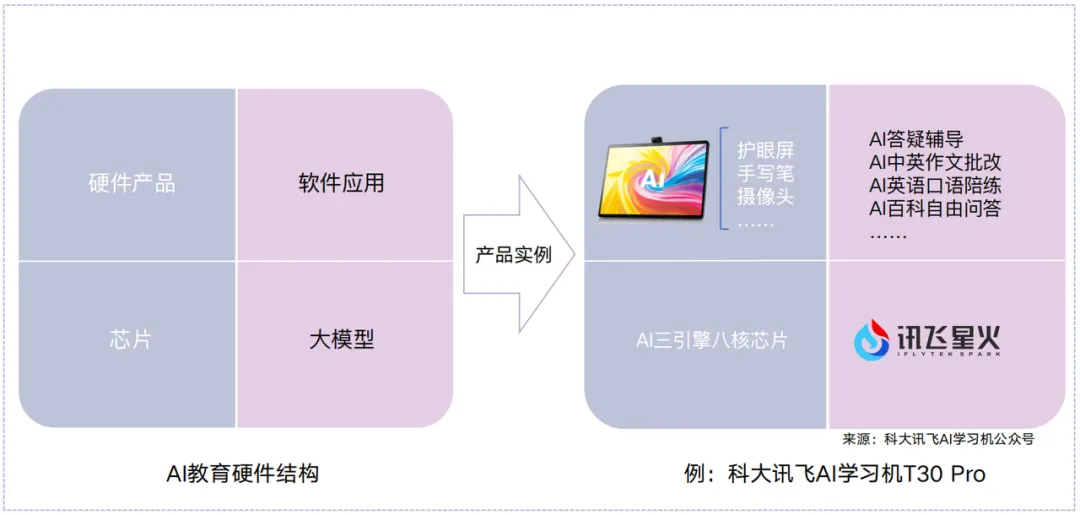
近一年来,AI硬件在教育领域迎来爆发式增长

SafeEar是一种内容隐私保护的语音伪造检测方法,其核心是设计基于神经音频编解码器的解耦模型,分离语音声学与语义信息,仅利用声学信息检测,包括前端解耦模型、瓶颈层和混淆层、伪造检测器、真实环境增强四部分。
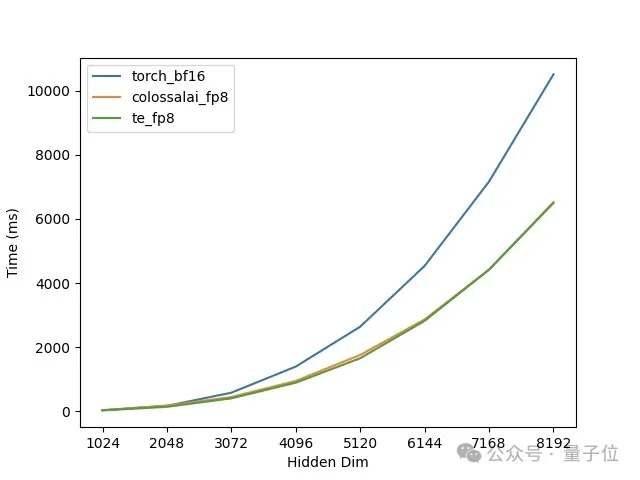
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。

自适应系统在动态和不确定的环境中具有关键作用,广泛应用于自动驾驶、智能制造、网络安全和智能医疗等领域。

指令调优(Instruction tuning)是一种优化技术,通过对模型的输入进行微调,以使其更好地适应特定任务。先前的研究表明,指令调优样本效率是很高效的,只需要大约 1000 个指令-响应对或精心制作的提示和少量指令-响应示例即可。

科学技术的快速发展过程中,机器学习研究作为创新的核心驱动力,面临着实验过程复杂、耗时且易出错,研究进展缓慢以及对专门知识需求高的挑战。近年来,LLM 在生成文本和代码方面展现出了强大的能力,为科学研究带来了前所未有的可能性。然而,如何系统化地利用这些模型来加速机器学习研究仍然是一个有待解决的问题。

深入探讨OpenAI o1模型的技术原理以及产业影响。

三维重建是计算机图形学的经典任务,具有很强的使用价值。近年来,诸如神经辐射场的隐式场方法 [1][2][3][4] 正成为重建任务广泛采用的表示。

NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。
两个多月前那个对标GPT-4o的端到端语音模型,终于开源了。大神Karpathy体验之后表示:nice!

语音合成大模型赛道,王者一夜易主。

这是关于垂直 SaaS (Vertical SaaS)的两部分系列的第一部分。

AI玩黑神话,第一个精英怪牯护院轻松拿捏啊。

OpenAI的o1系列一发布,传统数学评测基准都显得不够用了。

DeepMind最近的研究提出了一种新框架AligNet,通过模拟人类判断来训练教师模型,并将类人结构迁移到预训练的视觉基础模型中,从而提高模型在多种任务上的表现,增强了模型的泛化性和鲁棒性,为实现更类人的人工智能系统铺平了道路。