
OpenCity大模型预测交通路况,零样本下表现出色,来自港大百度
OpenCity大模型预测交通路况,零样本下表现出色,来自港大百度长时间交通状况预测,可以用大模型实现了。
来自主题: AI技术研报
10234 点击 2024-08-31 15:30
 搜索
搜索
长时间交通状况预测,可以用大模型实现了。

大模型竞技场规则更新,GPT-4o mini排名立刻雪崩,跌出前10。

本文第一作者为香港大学博士研究生谢知晖,主要研究兴趣为大模型对齐与强化学习。

Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。

终于有了点赛博朋克的样子。

美国警察开始使用人工智能工具Draft One辅助文书工作,犯罪报告秒生成,比人脑回忆更准确。

尽管不断招兵买马,依旧挡不住OpenAI的安全团队「集体出走」。半数员工已离职、公司处在风口浪尖,奥特曼却在此时选择对内部员工展开安全监控。
太突然!也没有任何理由的!

罗盟,本工作的第一作者。新加坡国立大学(NUS)人工智能专业准博士生,本科毕业于武汉大学。主要研究方向为多模态大语言模型和 Social AI、Human-eccentric AI。

当前的大型语言模型似乎能够通过一些公开的图灵测试。我们该如何衡量它们是否像人一样聪明呢?

在人工智能重塑各个行业的今天,法律界也迎来了前所未有的变革。传统的法律实践面临着效率低下、成本高昂等挑战,而AI技术的出现为解决这些问题提供了新的可能。

GPT-4o能挂在脖子上了?还能当手环、别在口袋上,实时AI转录。

免费的AI视频通话功能,就这么水灵灵地来了。

AI 硬件领域最近掀起一波小高潮。
OpenAI估值,超1000亿美元!
“比Sora还震撼”,AI可以实时生成游戏了!
我一直认为人工智能将改变世界,但我们总是不得不面对技术的局限性和不确定性。因此我们需要弄清楚今天行之有效的方法,同时不忘展望明天。

让AI像人类一样借助多模态线索定位感兴趣的物体,有新招了!
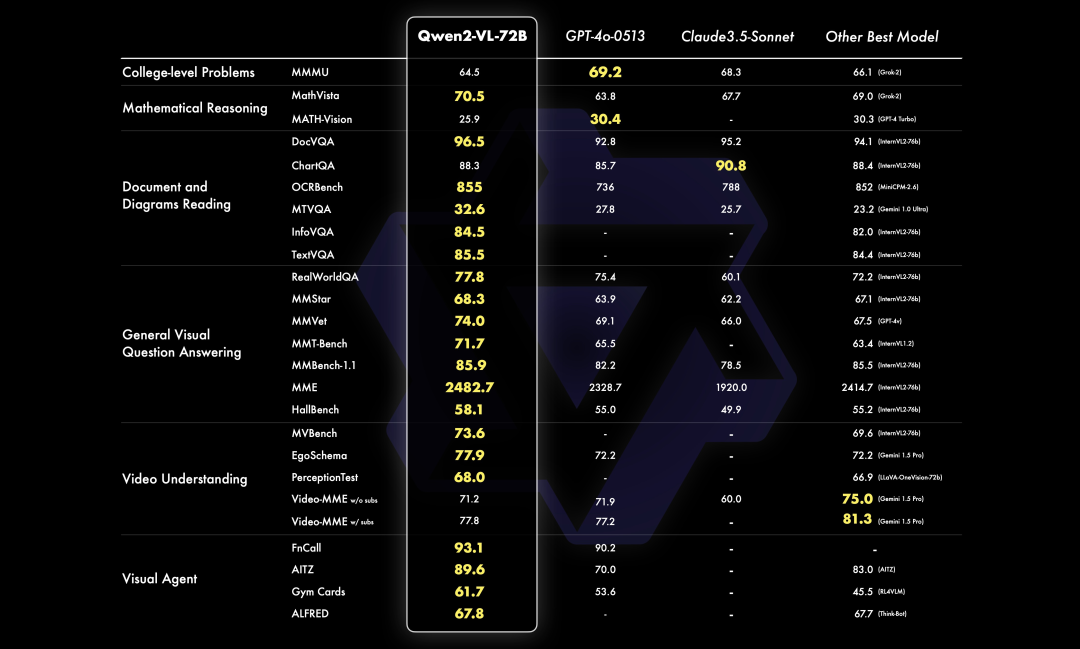
新的最强开源多模态大模型来了!

现有的大模型已经能够创作令人惊叹画作,那鉴赏艺术画作岂不是信手拈来?
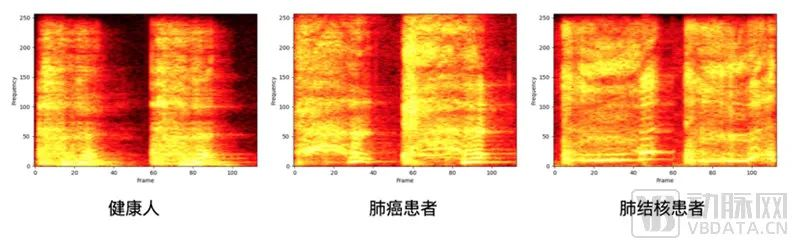
通过患者体内发出的声音“听音辨病”成为现实又近了一步
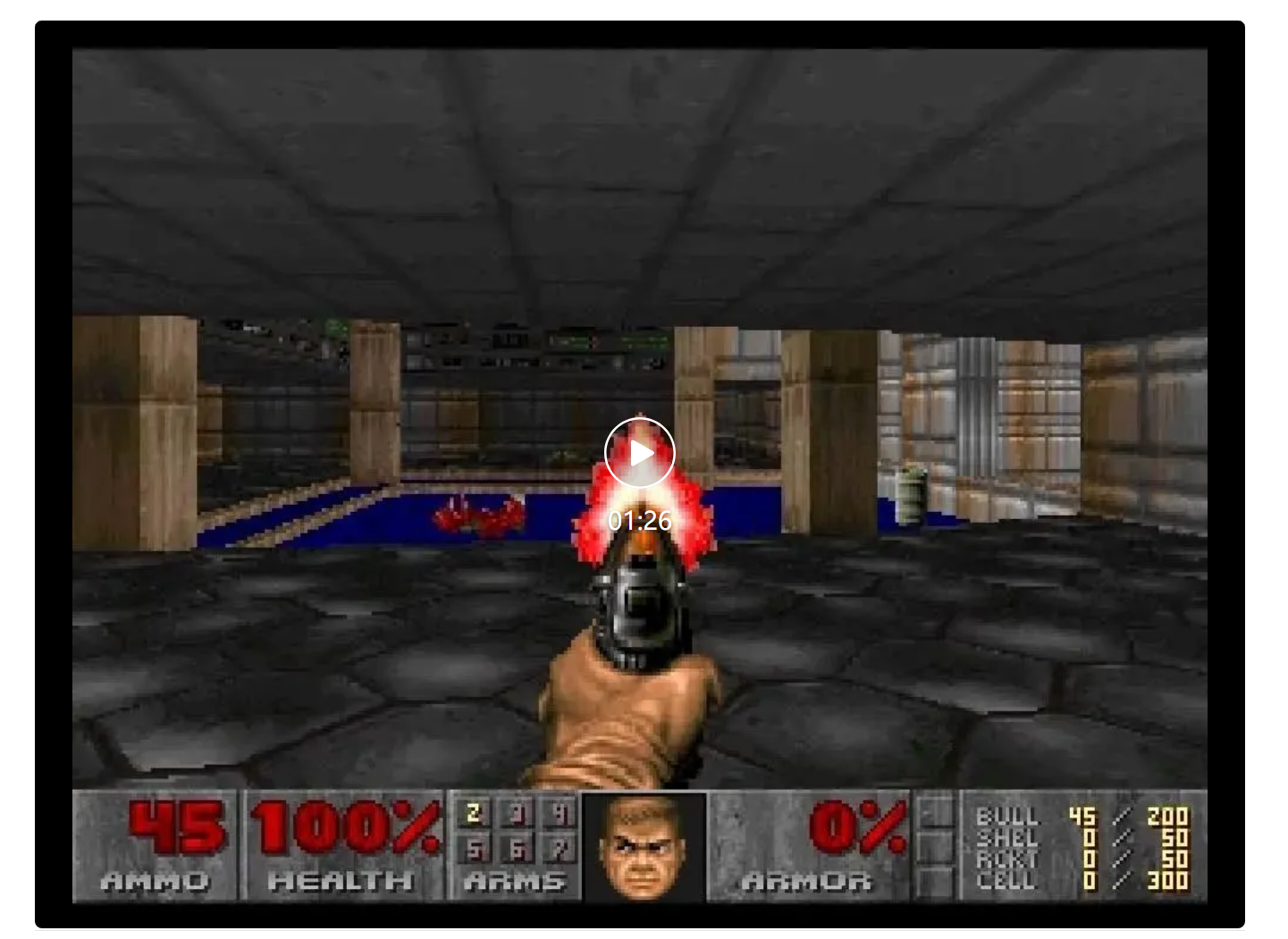
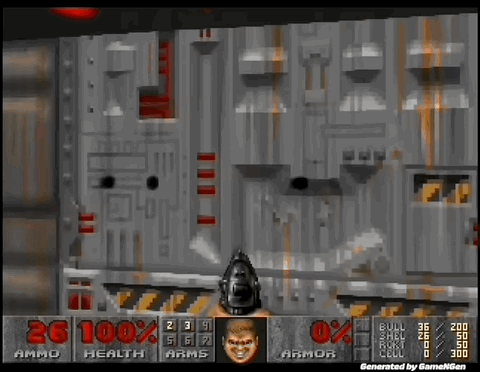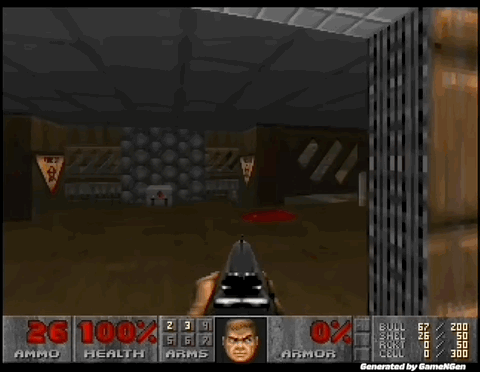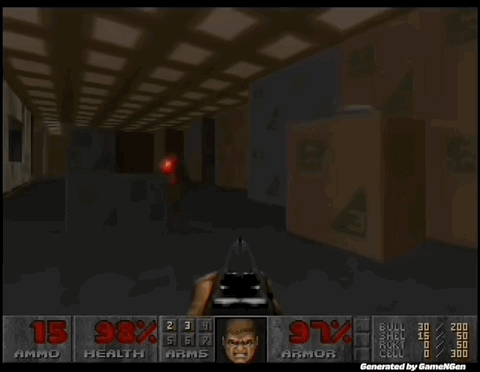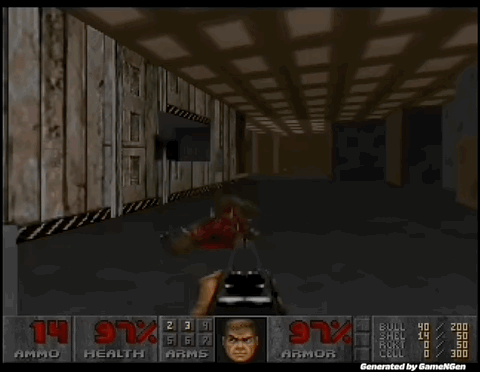
GameNGen 是第一个完全由神经模型驱动的游戏引擎。

本文的主要作者来自香港大学的数据智能实验室 (Data Intelligence Lab@HKU)。

人工神经网络、深度学习方法和反向传播算法构成了现代机器学习和人工智能的基础。但现有方法往往是一个阶段更新网络权重,另一个阶段在使用或评估网络时权重保持不变。这与许多需要持续学习的应用程序形成鲜明对比。

在探索「数学之美」的路上,人工智能到底走到哪一步了?说到这个话题,可能没人比数学家陶哲轩更懂。他几乎是最常用 AI 辅助证明的数学家之一,还在今年的 AI 数学奥林匹克竞赛(AIMO 进步奖)担任了顾问委员。
最近,又一款国产 AI 神器吸引了众网友和圈内研究人员的关注!它就是全新的图像和视频生成控制工具 —— ControlNeXt,由思谋科技创始人、港科大讲座教授贾佳亚团队开发。

最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。
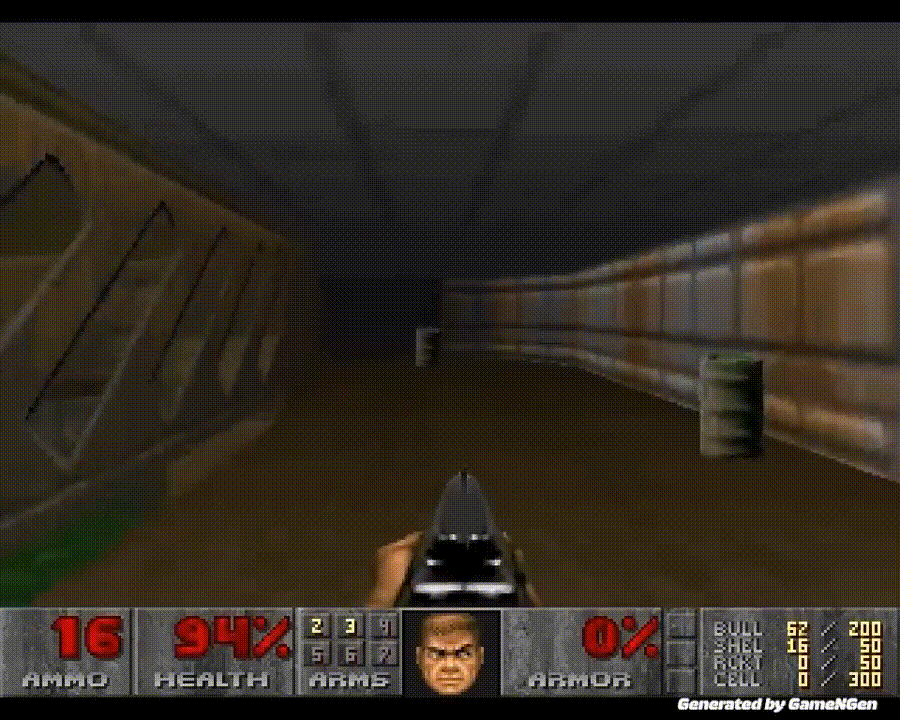
炸裂!世界上首个完全由AI驱动的游戏引擎来了。谷歌研究者训练的GameNGen,能以每秒20帧实时生成DOOM的游戏画面,画面如此逼真,60%的片段都没让玩家认出是AI!全球2000亿美元的游戏行业,从此将被改变。

AI Agent的机会来了!

ACM SIGKDD(国际数据挖掘与知识发现大会,KDD) 会议始于 1989 年,是数据挖掘领域历史最悠久、规模最大的国际顶级学术会议,也是首个引入大数据、数据科学、预测分析、众包等概念的会议。