LLM蒸馏到GNN,性能提升6.2%!Emory提出大模型蒸馏到文本图|CIKM 2024
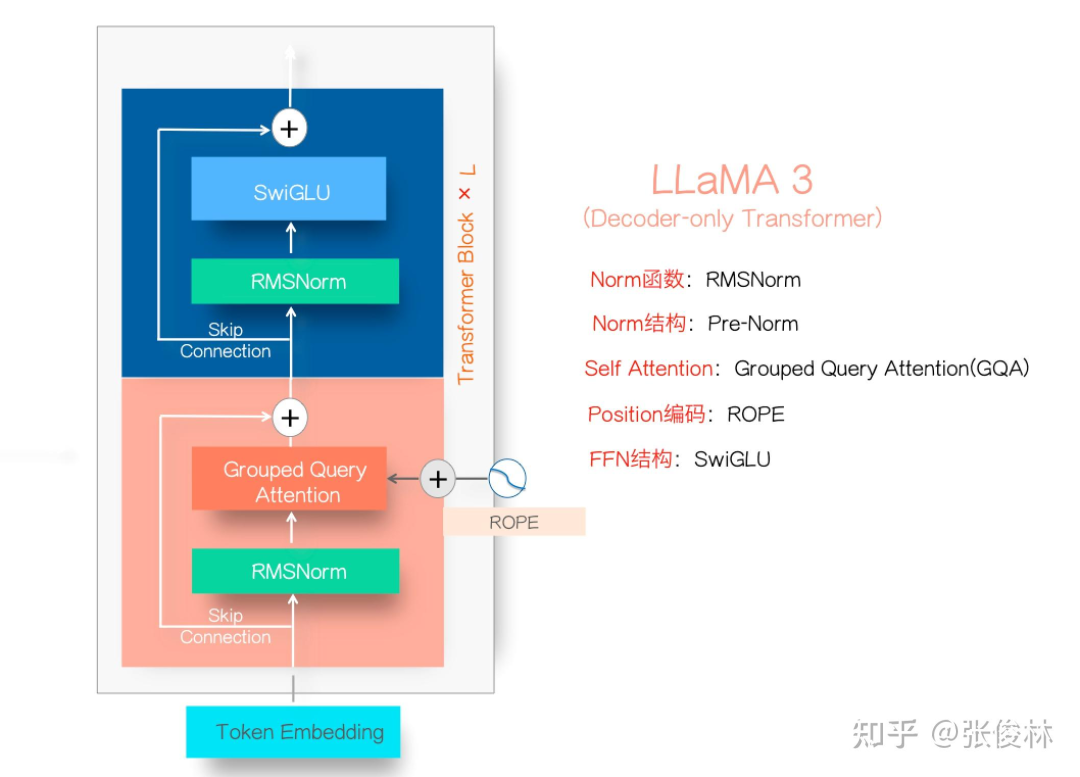
LLM蒸馏到GNN,性能提升6.2%!Emory提出大模型蒸馏到文本图|CIKM 2024Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。
来自主题: AI技术研报
12547 点击 2024-08-23 16:35