
首个像人类一样思考的网络!Nature子刊:AI模拟人类感知决策
首个像人类一样思考的网络!Nature子刊:AI模拟人类感知决策近日,来自佐治亚理工学院的研究人员开发了RTNet,首次表明其「思考方式」与人类非常相似。
来自主题: AI技术研报
11559 点击 2024-08-14 16:45
 搜索
搜索
近日,来自佐治亚理工学院的研究人员开发了RTNet,首次表明其「思考方式」与人类非常相似。

天网离我们还有多远?现在,科学家们希望通过一个强大的超算网络,来加速发展人类级别的人工智能,预计在2025年前全面投入运行。

只用提示词,多模态大模型就能更懂场景中的人物关系了。

Mini-Monkey 是一个轻量级的多模态大型语言模型,通过采用多尺度自适应切分策略(MSAC)和尺度压缩机制(SCM),有效缓解了传统图像切分策略带来的锯齿效应,提升了模型在高分辨率图像处理和文档理解任务的性能。它在多项基准测试中取得了领先的成绩,证明了其在多模态理解和文档智能领域的潜力。

芯片物理布局,有了直指性能指标的新测评标准!
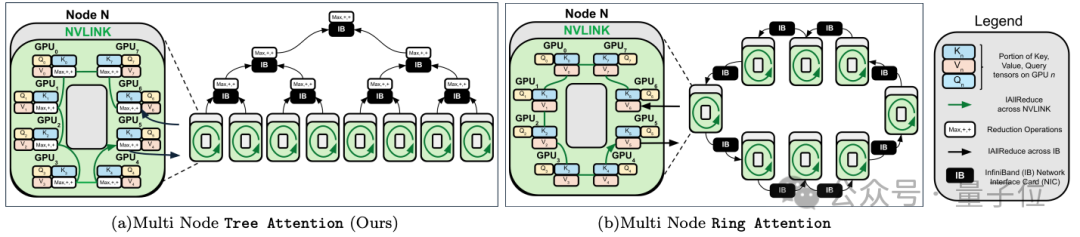
跨GPU的注意力并行,最高提速8倍,支持512万序列长度推理。
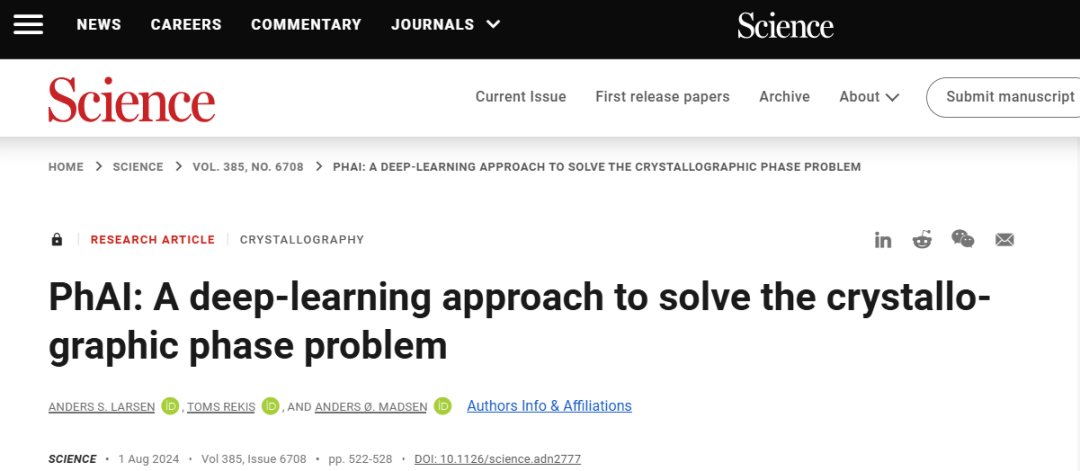
时至今日,晶体学所测定的结构细节和精度,从简单的金属到大型膜蛋白,是任何其他方法都无法比拟的。然而,最大的挑战——所谓的相位问题,仍然是从实验确定的振幅中检索相位信息。

在过去的几年中,大型语言模型(Large Language Models, LLMs)在自然语言处理(NLP)领域取得了突破性的进展。这些模型不仅能够理解复杂的语境,还能够生成连贯且逻辑严谨的文本。

自从 Sora 发布以来,AI 视频生成领域变得更加「热闹」了起来。过去几个月,我们见证了即梦、Runway Gen-3、Luma AI、快手可灵轮番炸场。

仅需15秒即可搞定随机规划问题,速度比传统方法快了1440倍!

OpenAI推出了结构化输出功能,确保API输出与JSON模式精确匹配,提高数据生成的可靠性。

LLM数学水平不及小学生怎么办?CMU清华团队提出了Lean-STaR训练框架,在语言模型进行推理的每一步中都植入CoT,提升了模型的定理证明能力,成为miniF2F上的新SOTA。
前段时间冲上热搜的问题「9.11比9.9大吗?」,让几乎所有LLM集体翻车。看似热度已过,但AI界大佬Andrej Karpathy却从中看出了当前大模型技术的本质缺陷,以及未来的潜在改进方向。

有CPU就能跑大模型,性能甚至超过NPU/GPU!

用光训练神经网络,清华成果最新登上了Nature!
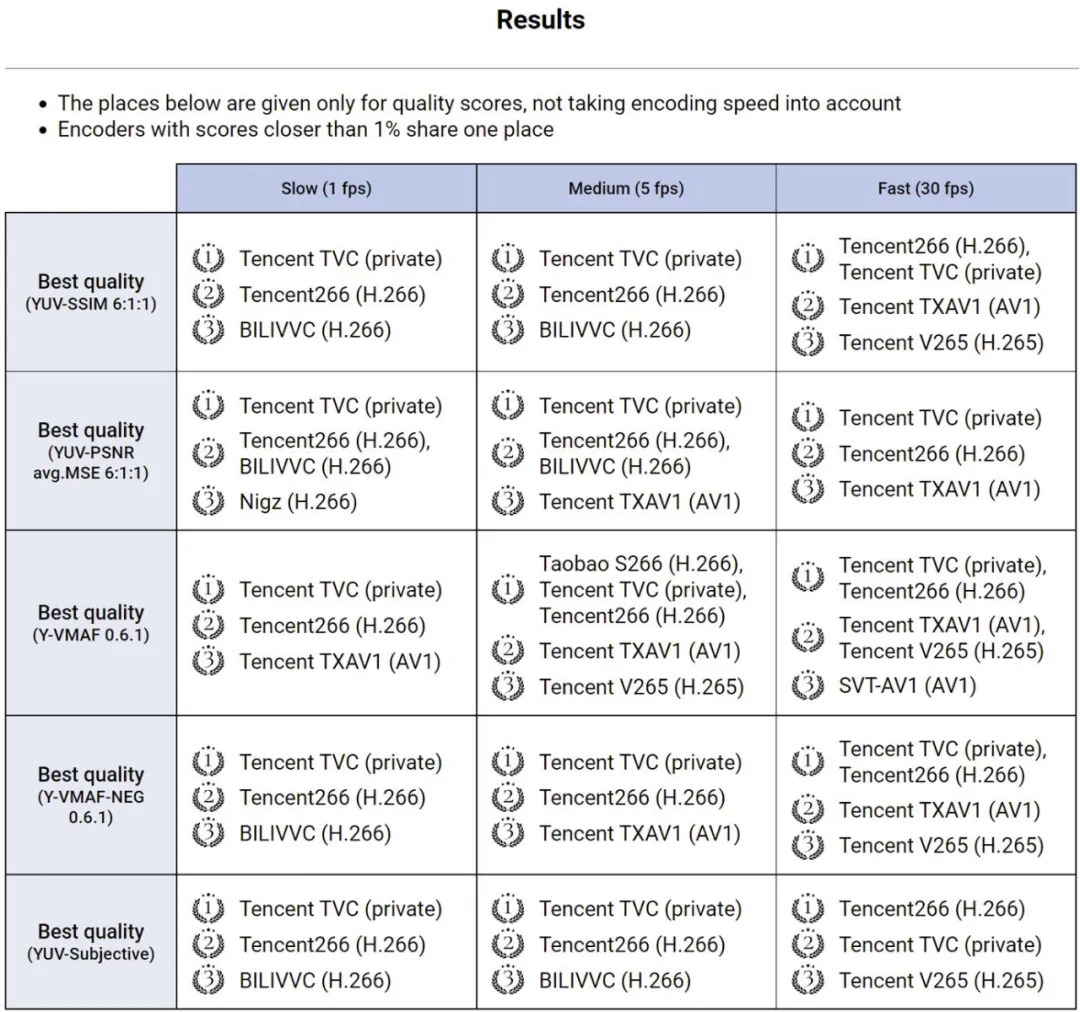
今日获悉,由莫斯科国立大学举办的 MSU 世界视频编码器大赛结果揭晓。在全部参赛编码器中,腾讯编码器包揽所有 15 项指标的全部第一,再次斩获全场最佳。

专注于计算机图形学的全球学术顶会 SIGGRAPH,正在出现新的趋势。

该论文的第一作者和通讯作者均来自北京大学王选计算机研究所的 MIPL实验室,第一作者为博士生徐铸,通讯作者为博士生导师刘洋。MIPL 实验室近年来在 IJCV、CVPR、AAAI、ICCV、ICML、ECCV 等顶会上有多项代表性成果发表,多次荣获国内外 CV 领域重量级竞赛的冠军奖项,和国内外知名高校、科研机构广泛开展合作。

AI辅助制药,找到传统方法难以发现的关键盐桥,激动剂活性直接提升2-3倍!

LLM的数学推理能力缺陷得到了很多研究的关注,但最近浙大、中科院等机构的学者们提出,先进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。

Transformer架构层层堆叠,包含十几亿甚至几十亿个参数,这些层到底是如何工作的?当一个新奇的比喻——「画家流水线」,被用于类比并理解Transformer架构的中间层,情况突然变得明朗起来,并引出了一些有趣的发现。

为什么说AI搜索不只是搜索?

科学家正在通过AI的力量,改变乳腺癌的现状。

在长文本理解能力这块,竟然没有一个大模型及格!

七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。

李飞飞老师提出了空间智能 (Spatial Intelligence) 这一概念,作为回应,来自上交、斯坦福、智源、北大、牛津、东大的研究者提出了空间大模型 SpatialBot,并提出了训练数据 SpatialQA 和测试榜单 SpatialBench, 尝试让多模态大模型在通用场景和具身场景下理解深度、理解空间。

逆合成是药物发现和有机合成中的一项关键任务,AI 越来越多地用于加快这一过程。

最近的英伟达似乎步入了多事之秋。

谷歌TPU核心团队创立,要做世界最快推理。

新加坡举办了首届GPT-4提示工程竞赛,Sheila Teo取得了冠军,我们来学习借鉴她采用的三项提示技巧: 使用CO-STAR框架构建提示词 2.使用分隔符将提示词分段 3.使用LLM系统提示