ICRA 2026 | NUS邵林团队提出Goal-VLA:生成式大模型化身「世界模型」,实现零样本机器人操作
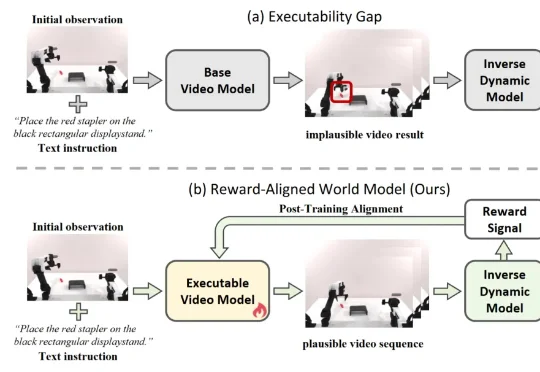
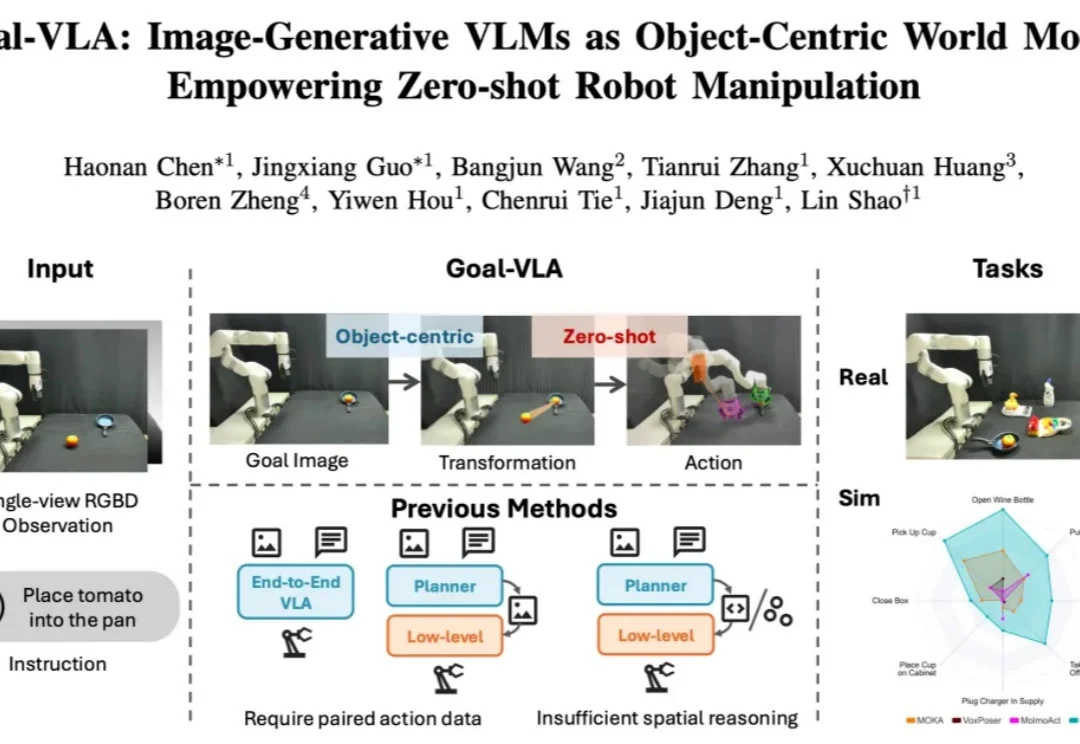
ICRA 2026 | NUS邵林团队提出Goal-VLA:生成式大模型化身「世界模型」,实现零样本机器人操作在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。
来自主题: AI技术研报
6478 点击 2026-03-30 15:00