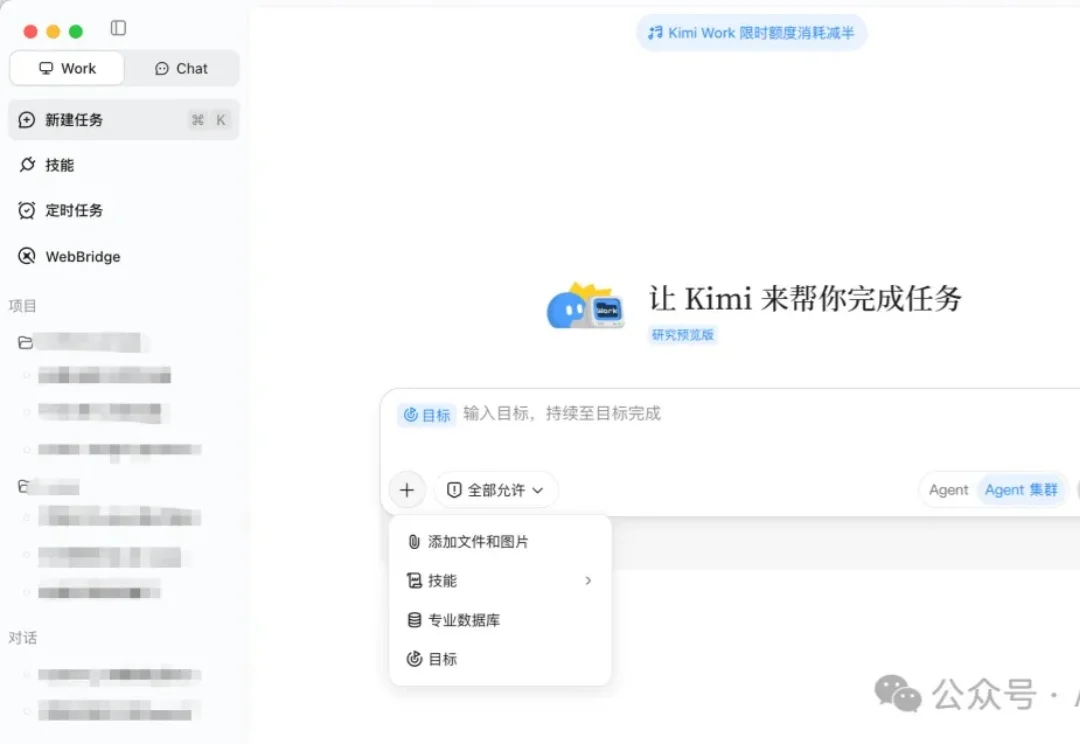
Kimi Work 推出目标模式:连肝 24 小时做了本漫画书,已开源
Kimi Work 推出目标模式:连肝 24 小时做了本漫画书,已开源自从上次介绍过 Kimi Work 外加 Fable 无情下线之后,我发现我还真越来越频繁地在使用这个桌面端 APP 了。当然模型能力只是一方面,关键桌面 APP 比起网页来说,在使用上还是要方便得太多了……而且也不用关心网络切来切去啥的。
来自主题: AI技术研报
9639 点击 2026-06-19 10:18
 搜索
搜索
自从上次介绍过 Kimi Work 外加 Fable 无情下线之后,我发现我还真越来越频繁地在使用这个桌面端 APP 了。当然模型能力只是一方面,关键桌面 APP 比起网页来说,在使用上还是要方便得太多了……而且也不用关心网络切来切去啥的。
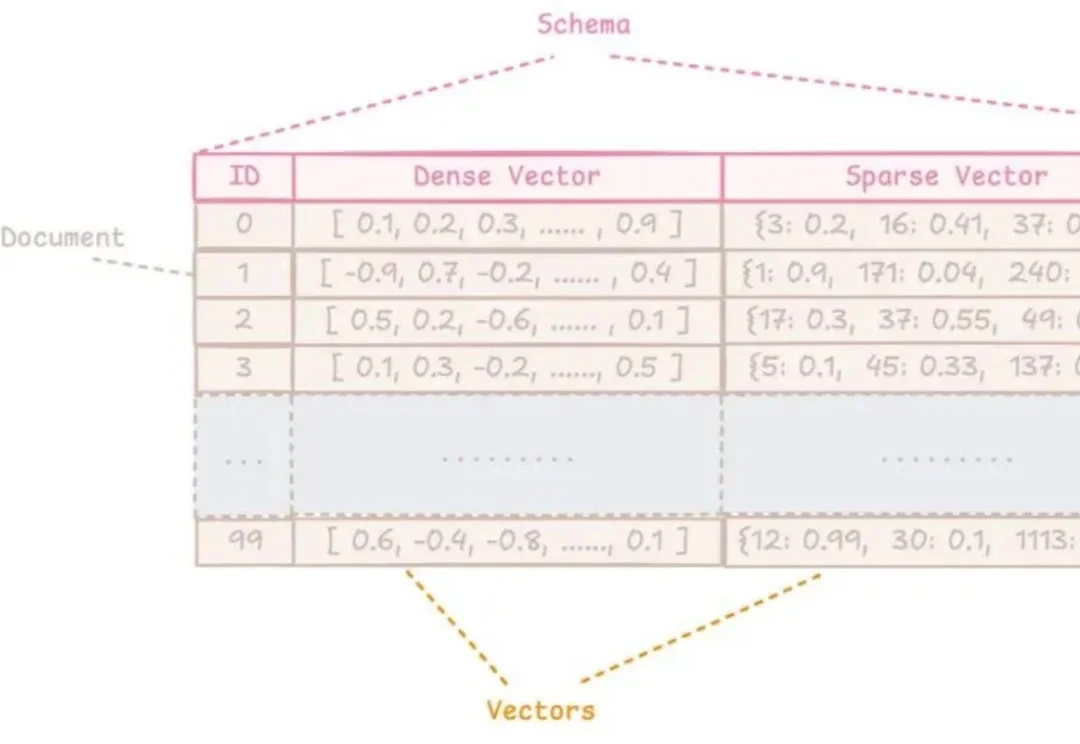
阿里开源的生产级向量数据库,跑在进程里,亿级数据毫秒响应
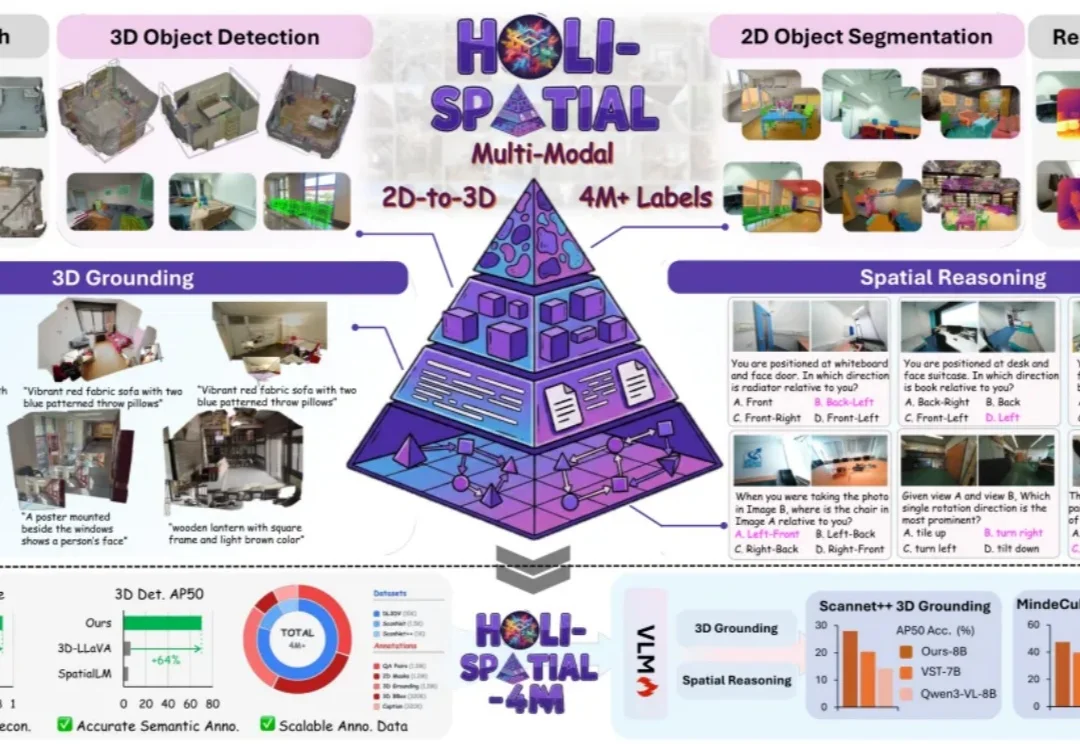
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。
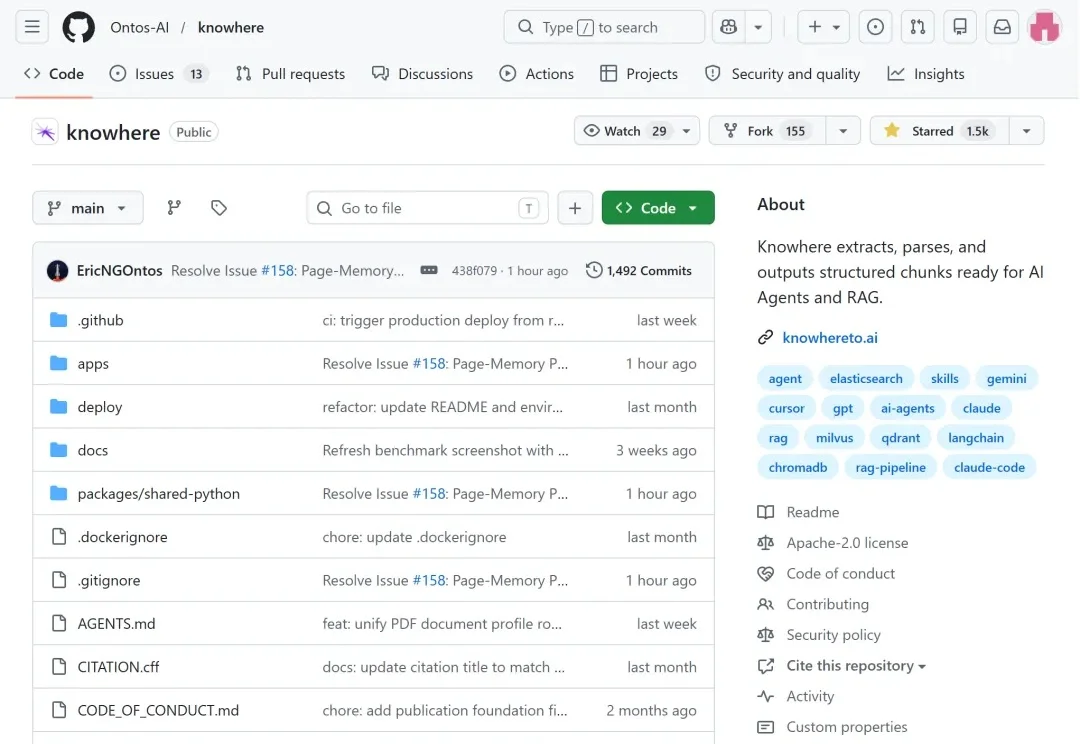
2026 年 5 月 7 日,我们把 Knowhere 的完整技术栈开源了。

PD大促还有两个周就开始了,不知道做亚马逊的你们词库搭好了吗?

在做 Agent Memory 工程化探索的这几个月里,我经常有种被概念淹没的窒息。图结构记忆、AutoMemory、做梦机制、各种层出不穷的 Memory 框架……整个技术社区似乎陷入了一种每遇到一个新场景就要发明一套新词汇的群体焦虑中。
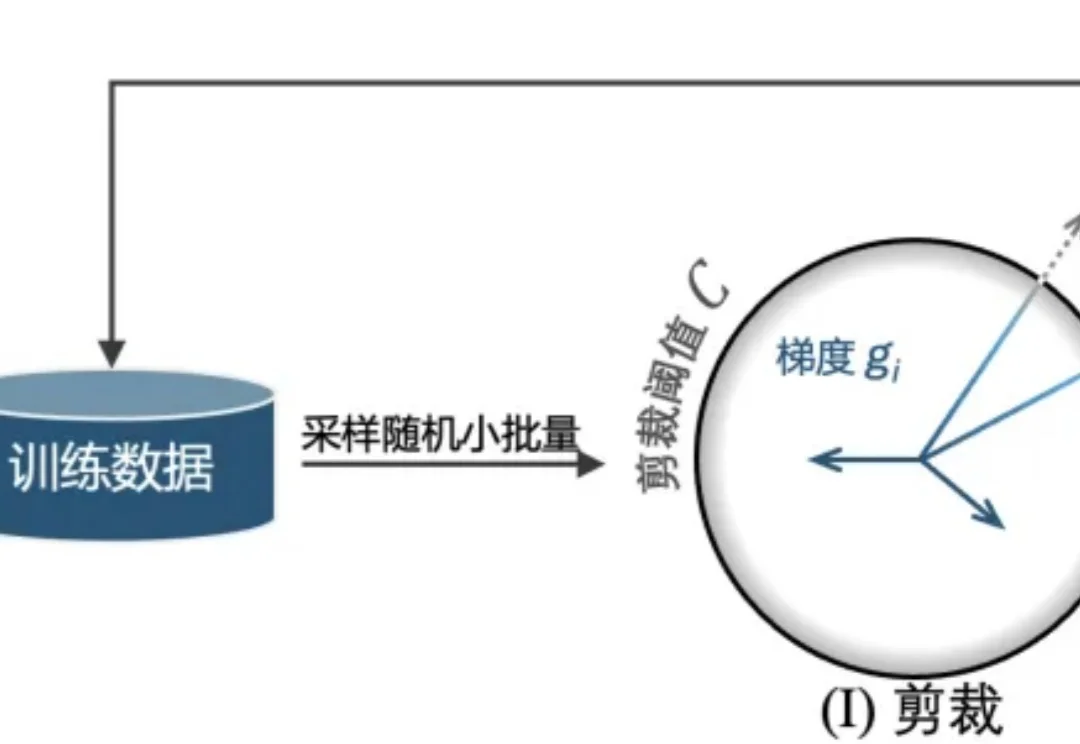
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。
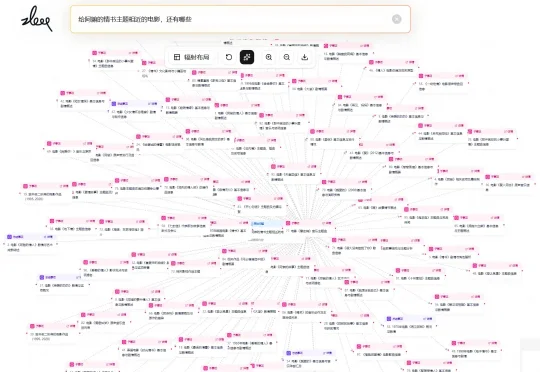
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。

自动化研究,这一次真正走出代码沙盒,进入了真实的物理世界。

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

大家好,我是袋鼠帝。 如果你家的猫狗真的能说话,它们开口第一句会说什么?
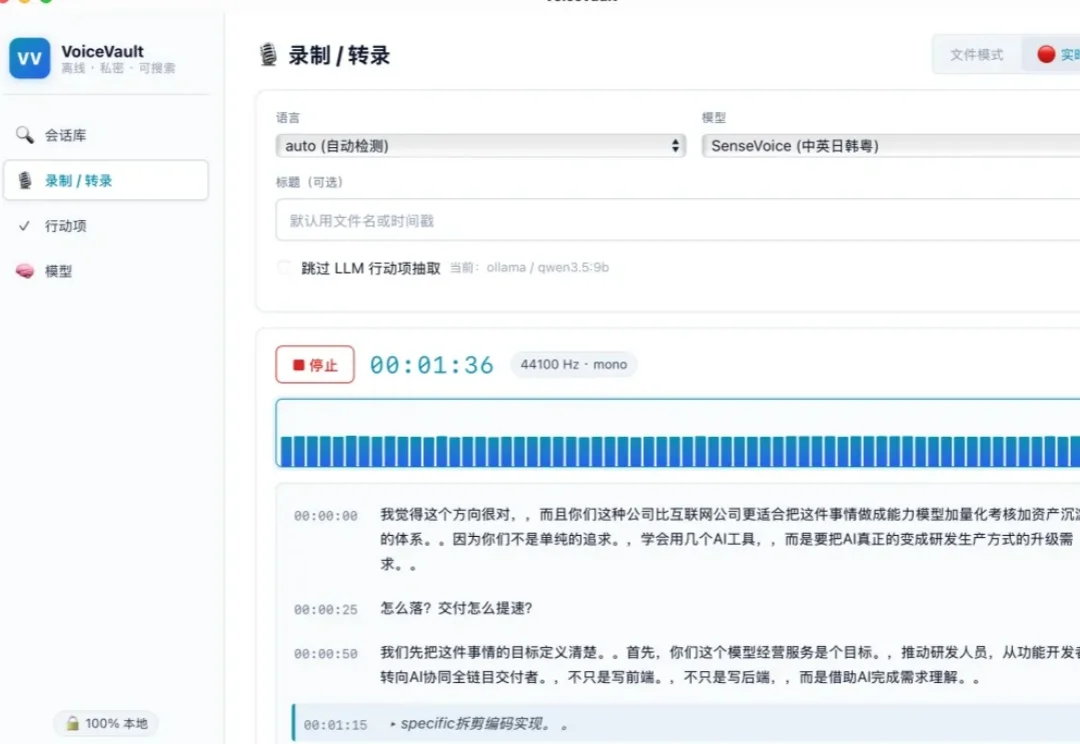
把 VoiceVault 的转录引擎从 Whisper 迁移到 FunASR(sherpa-onnx),中文识别速度提升 3x,不再需要 500MB 的模型文件。但"切个后端"这件听起来很简单的事,让我在 GitHub Release 的 404、Tauri 白屏、trait object 生命周期和 CSP 策略里翻滚了一整天。

AutoResearch这个词关注AI的同学应该不陌生,大神Andrej Karpathy提出的Agent 自主科研项目,现在已经是GitHub的明星项目了,应用不计其数。
还记得那个火爆全球的 AI Vtuber neuro-sama 吗?一个能实时和观众互动的 AI 虚拟主播。

谷歌今天发布了一个叫 Open Knowledge Format(OKF)的开放规范。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。

被算力荒逼出来的硬核奇迹!腾讯米哈游老兵组成的「草根」团队,硬在国产芯片上炼出了超10分钟的绝对物理一致性。画面可以糙,物理绝不能假,这就是通往AGI的真正基石。
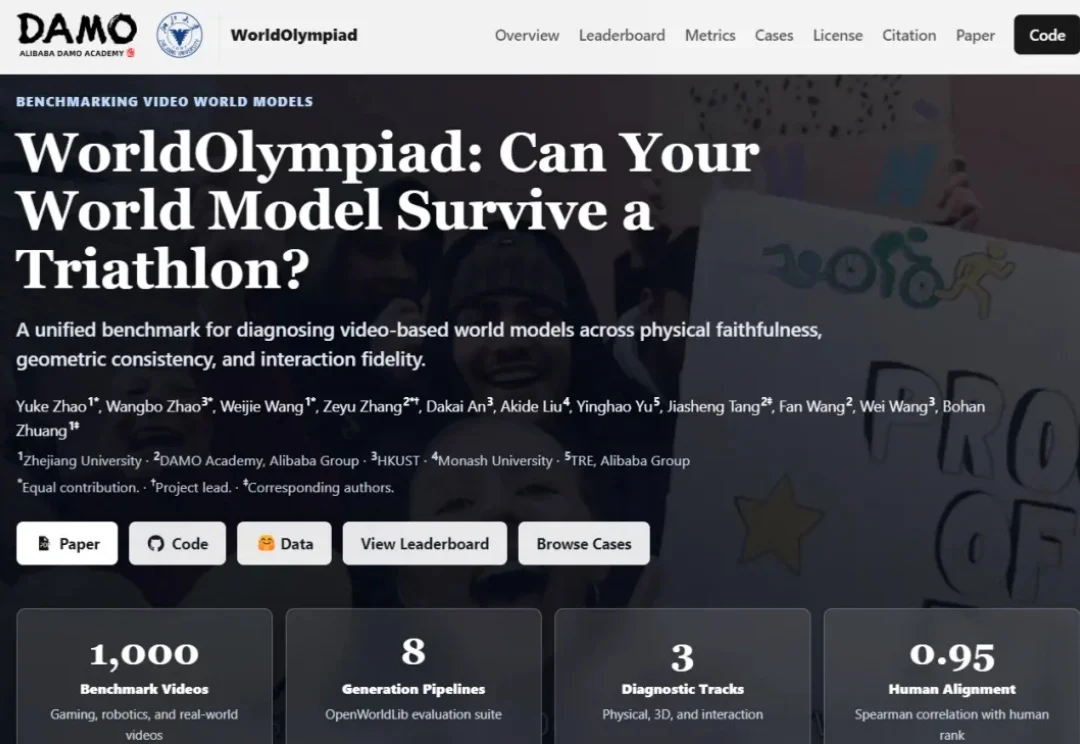
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。
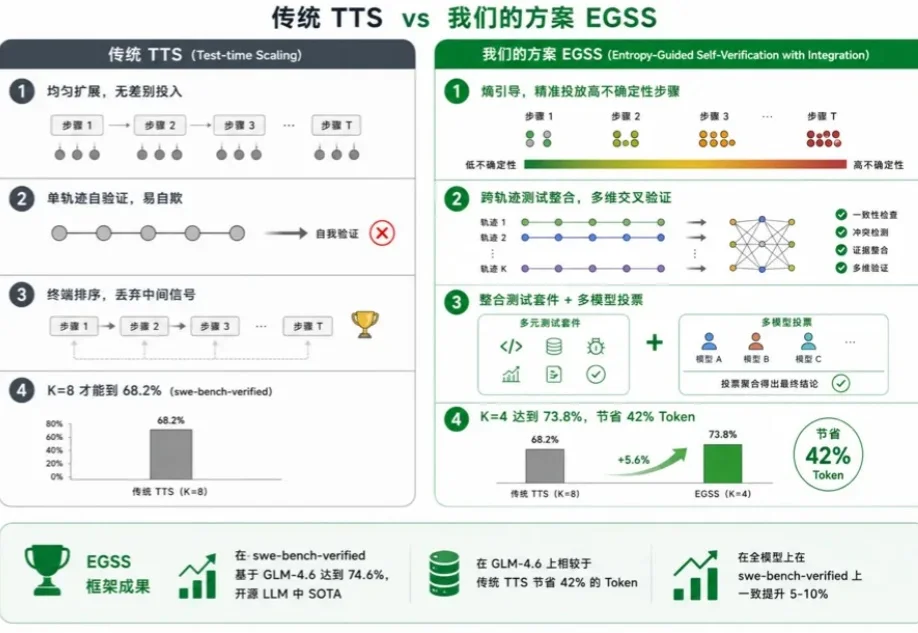
更聪明的计算远比更多的计算更有效。
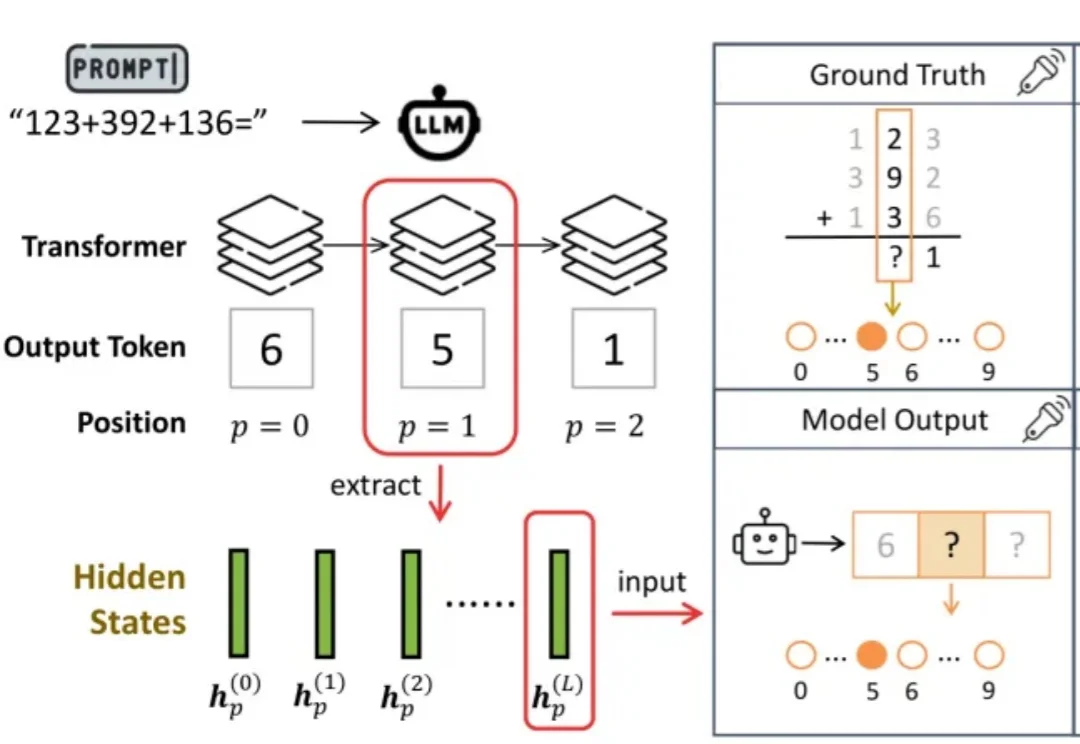
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。
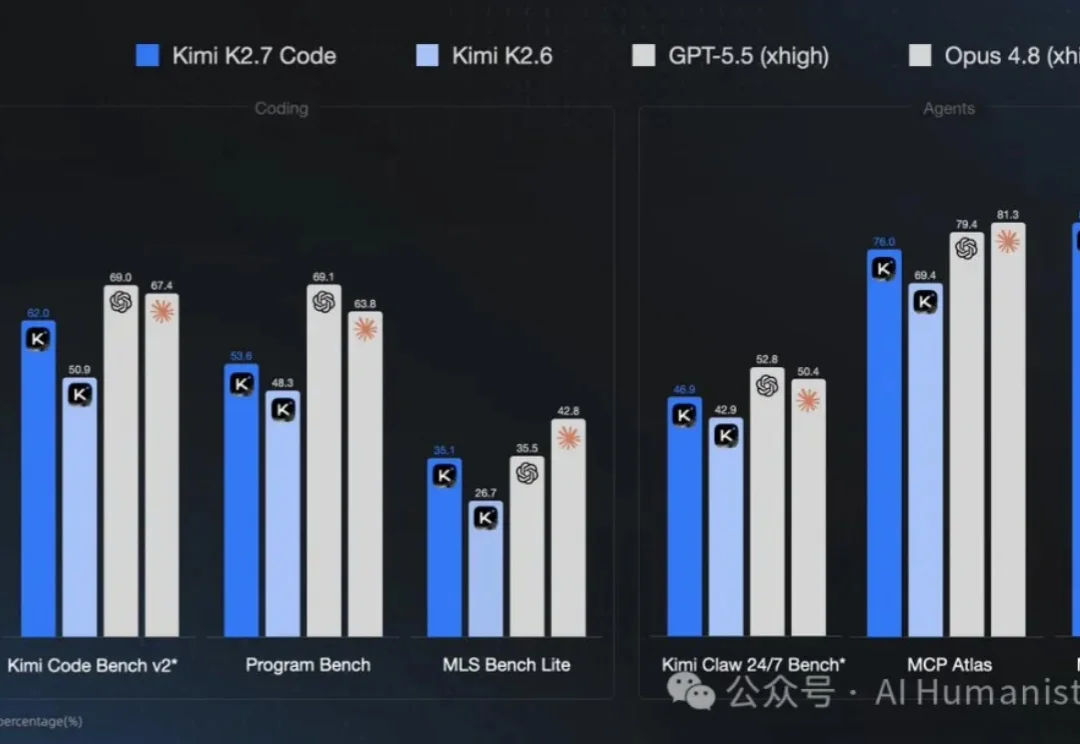
昨天 Kimi K2.7 Code 高速版 上线了,我上手试了下,最大的感受就一个字:快。
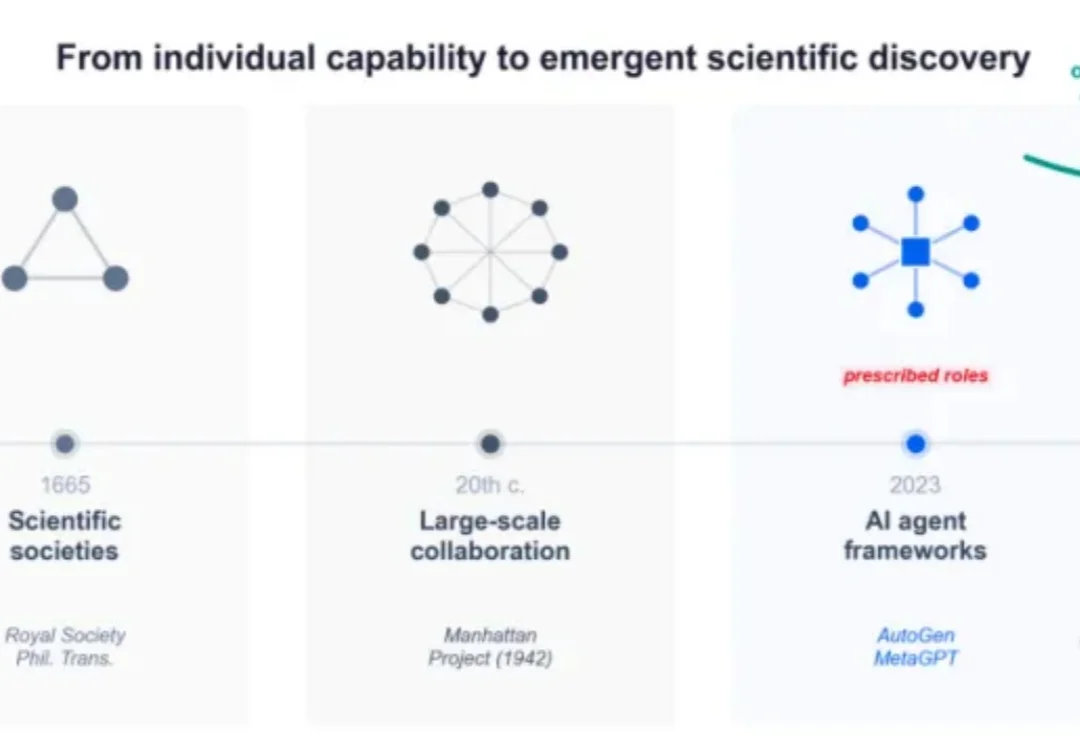
过去一年,由斯坦福大学丛乐(Le Cong)与普林斯顿大学王梦迪(Mengdi Wang)领衔的AI科研团队,一直在做同一件事: 把越来越多的异质能力,纳入同一个协同视野。

大模型再强,也读不懂你公司那一柜子的合同、发票和扫描件。在"纸张世界"和"LLM世界"之间,缺一座桥——而百度开源的 PaddleOCR,可能就是当下最稳的那座。
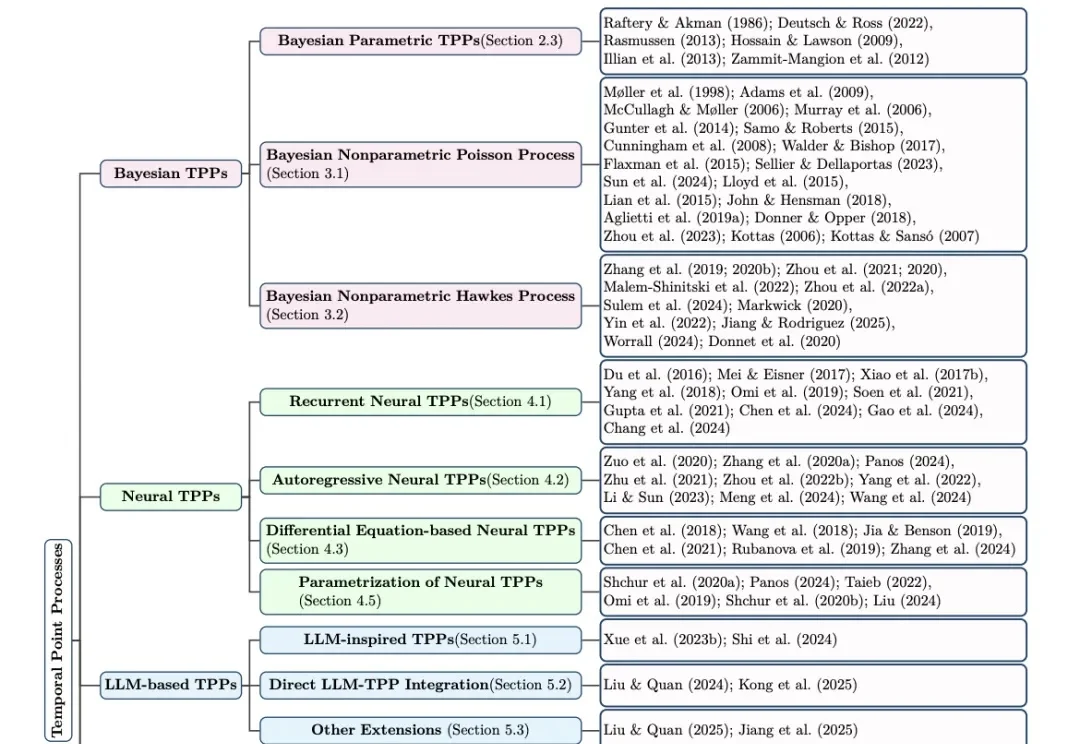
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。

当大模型开始控制机械臂、家用机器人时,“安全”这件事也变得不一样了。
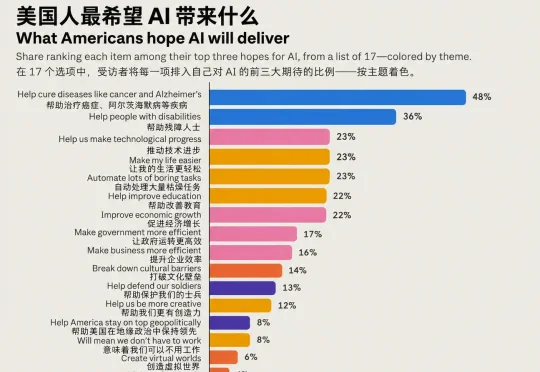
在一个什么都能吵翻天的国家,71%的美国人难得达成共识:AI必须有人管——但管它的,绝不能是造它的人。
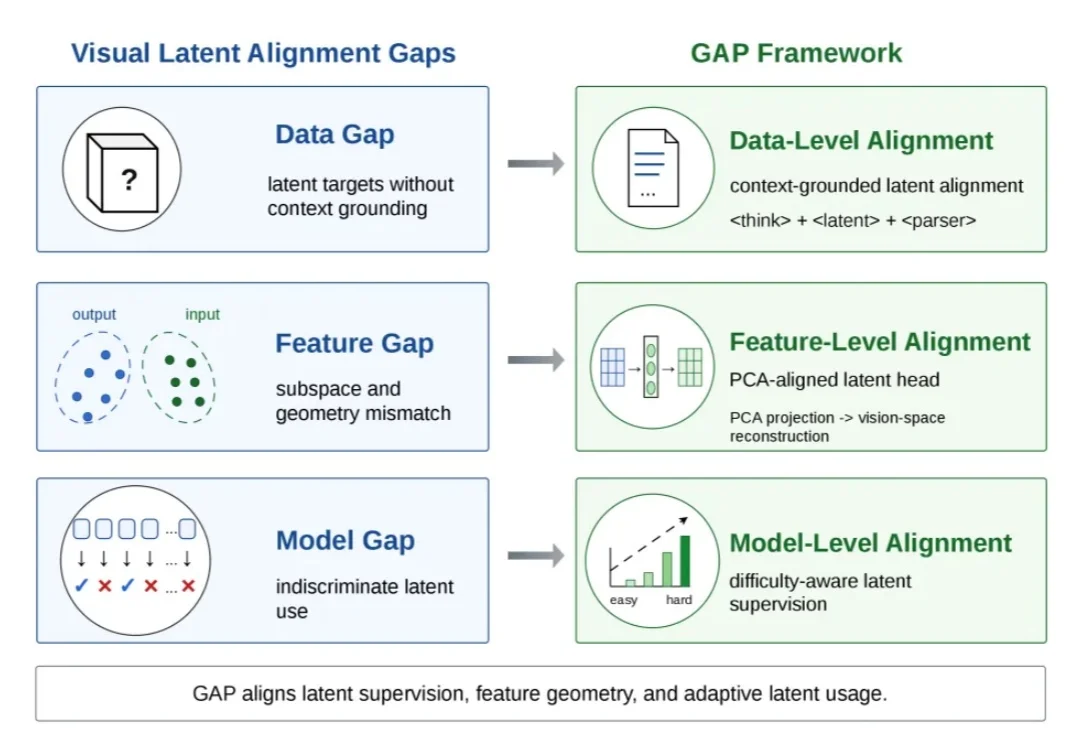
导读:视觉 latent reasoning 希望让多模态模型在内部生成连续 latent token,用这些中间表示补充多模态理解和推理任务中缺失的视觉证据。但问题在于,模型生成出来的 latent token 可能并不落在它原本熟悉的视觉输入空间里;如果模型无法稳定读取这些 token,它们就很难成为有效的中间视觉证据。
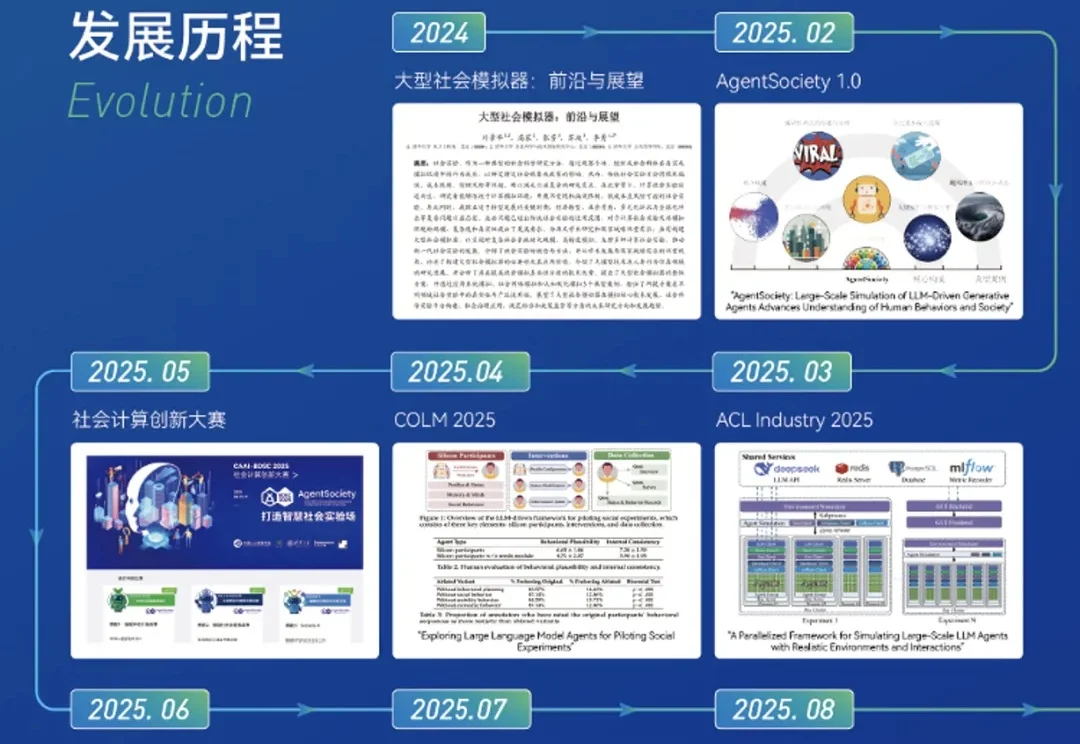
在《三体》式的科幻想象中,文明可以被遥远地观察,社会可以被冷静地记录,人类行为仿佛成为一个可被推演的复杂系统。
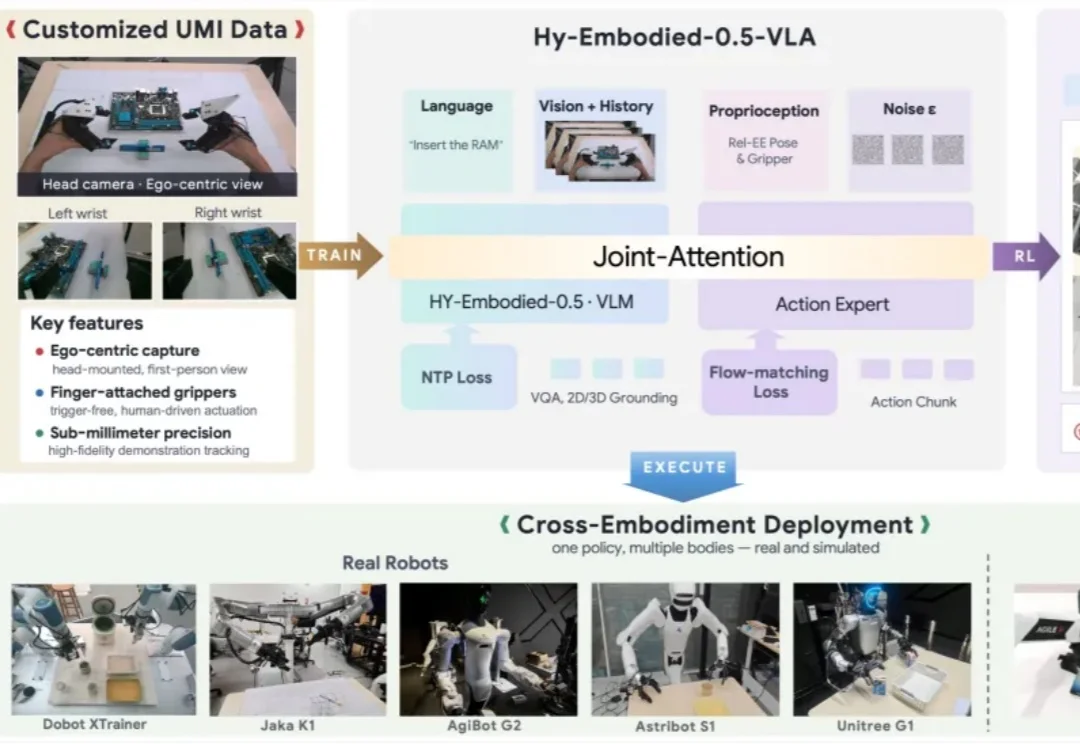
6 月 15 日,腾讯 Robotics X、福田实验室与混元团队联合发布面向真实世界机器人操作任务的端到端具身智能模型 Hy-Embodied-0.5-VLA(简称 HyVLA-0.5)。