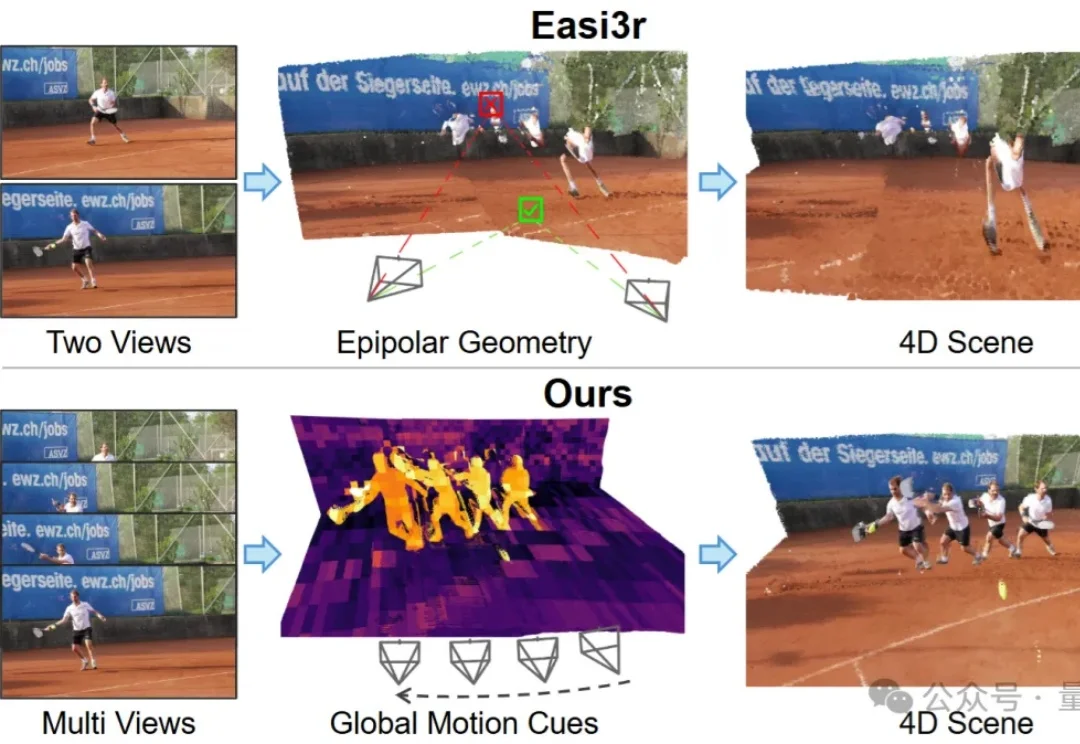
挖掘注意力中的运动线索:无需训练,解锁4D场景重建能力
挖掘注意力中的运动线索:无需训练,解锁4D场景重建能力如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
来自主题: AI技术研报
10997 点击 2025-12-18 09:48
 搜索
搜索
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
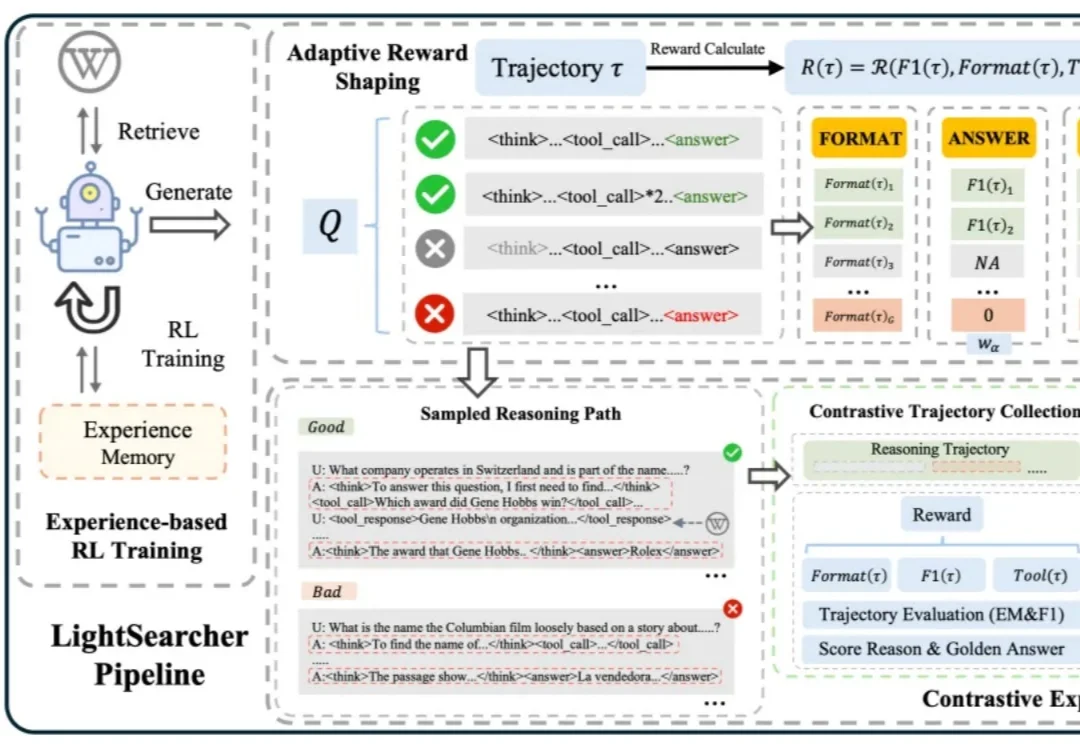
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。
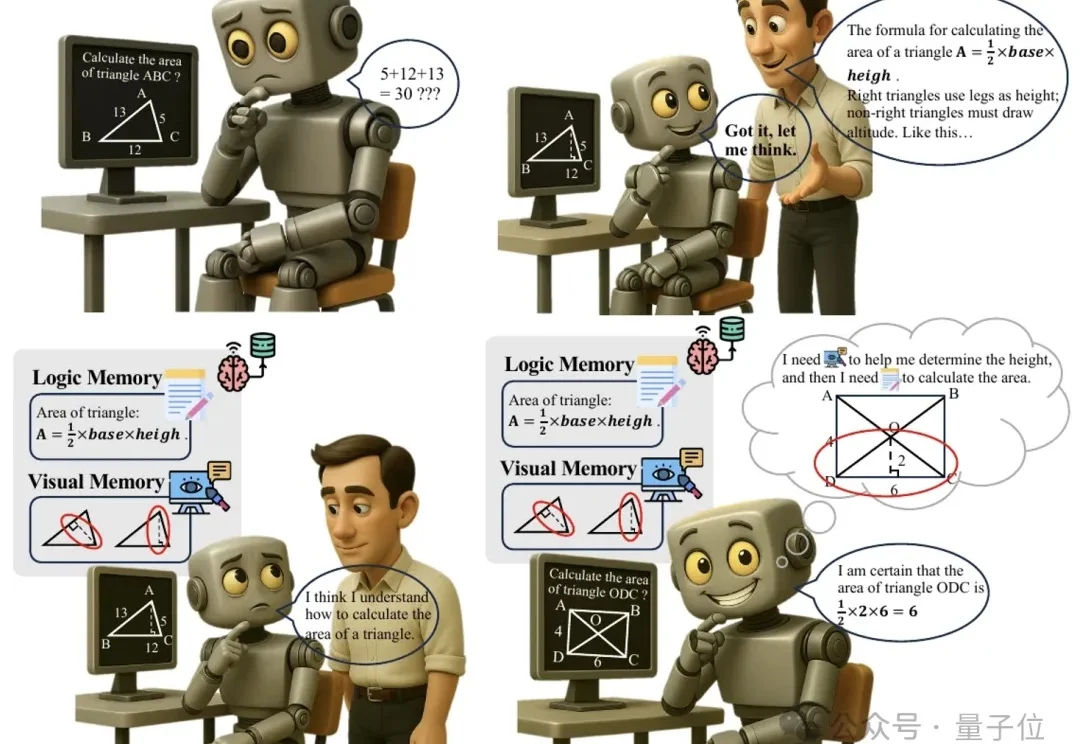
多模态推理又有新招,大模型“记不住教训”的毛病有治了。
今天聊一聊我们如何做高质量rerank。
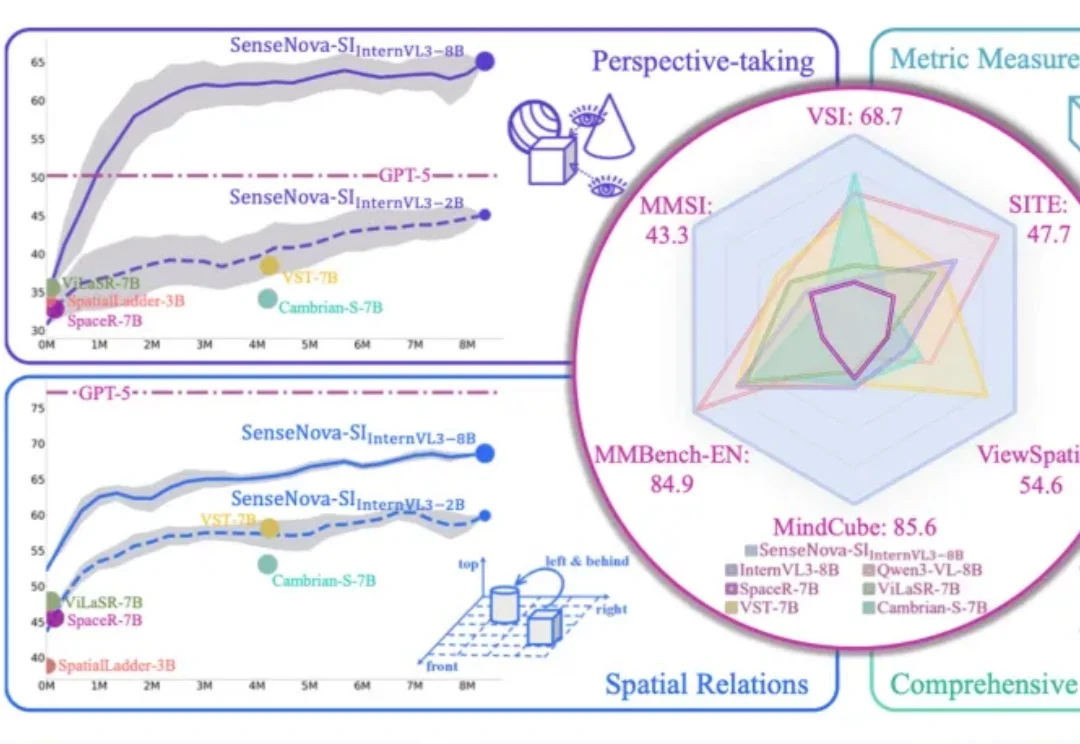
李飞飞团队最新的空间智能模型Cambrian-S,首次被一个国产开源AI超越了。

北京大学团队提出了一种新的视觉语义场景补全方法HD²-SSC,用于从多视角图像重建三维语义场景。该方法通过高维度语义解耦和高密度占用优化,解决了现有技术中二维输入与三维输出之间的维度差异,以及人工标注与真实场景密度差异的问题,从而实现更准确的语义场景补全。
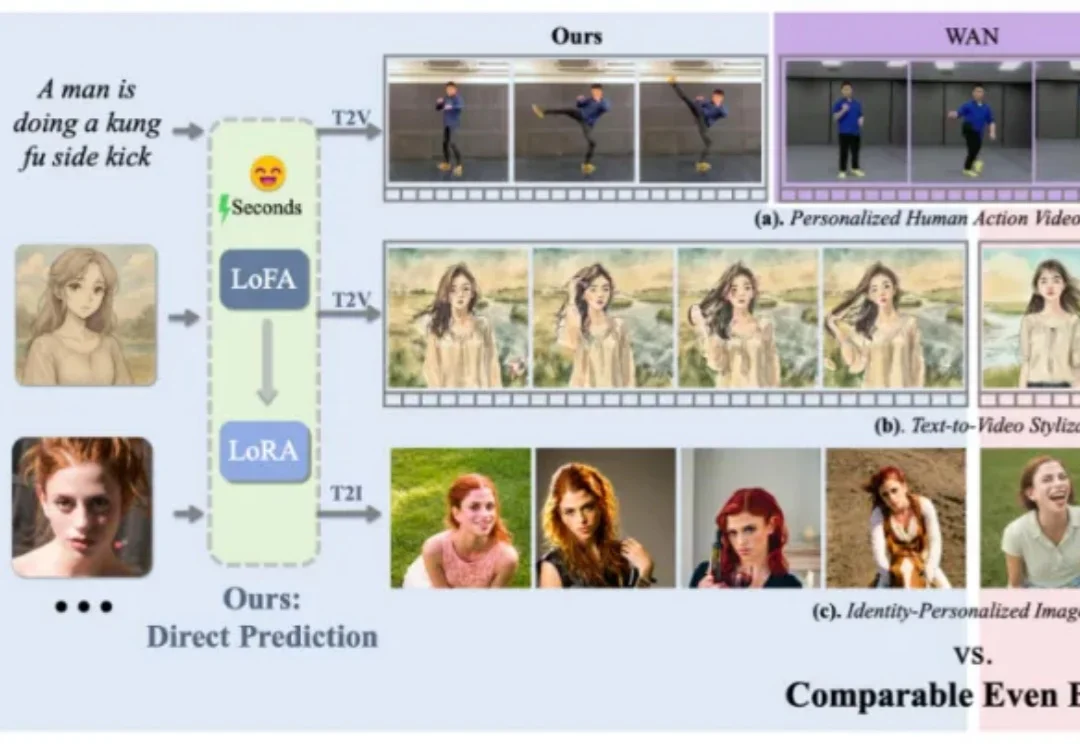
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。

他们不光能造GPU,还能写出全球顶级的算法!摩尔线程这次开源给国产具身智能递了一把「神兵利器」。
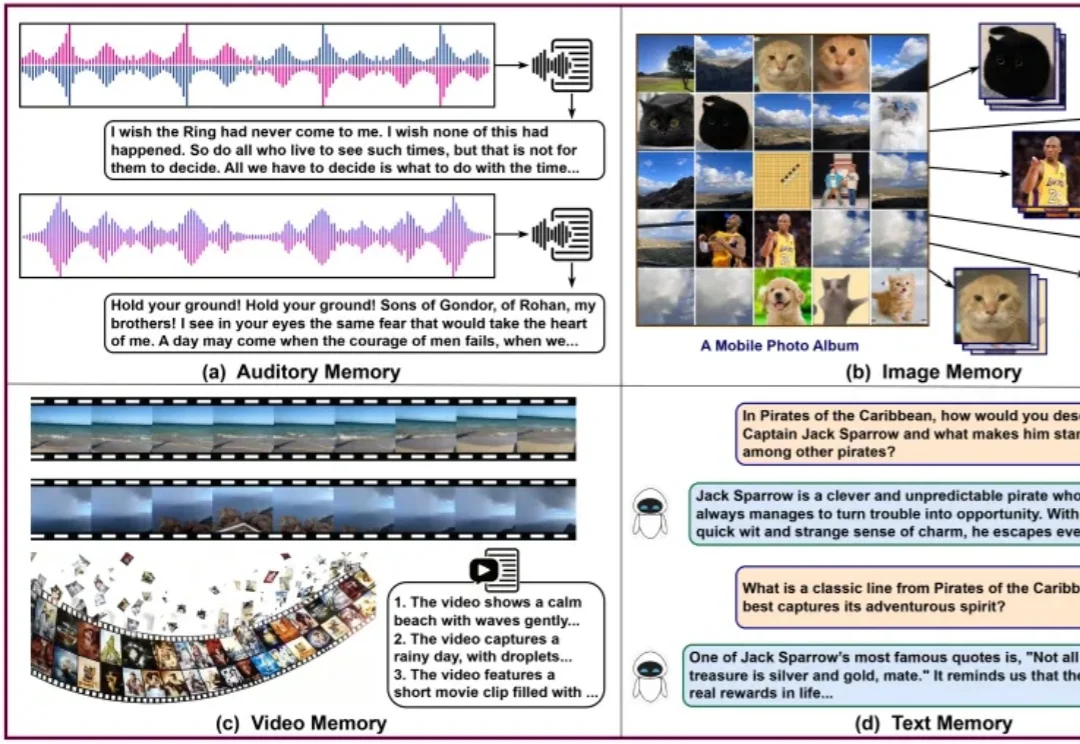
一页纯文本的记忆是看不清世界的。

LLM 智能体很赞,正在成为一种解决复杂难题的强大范式。
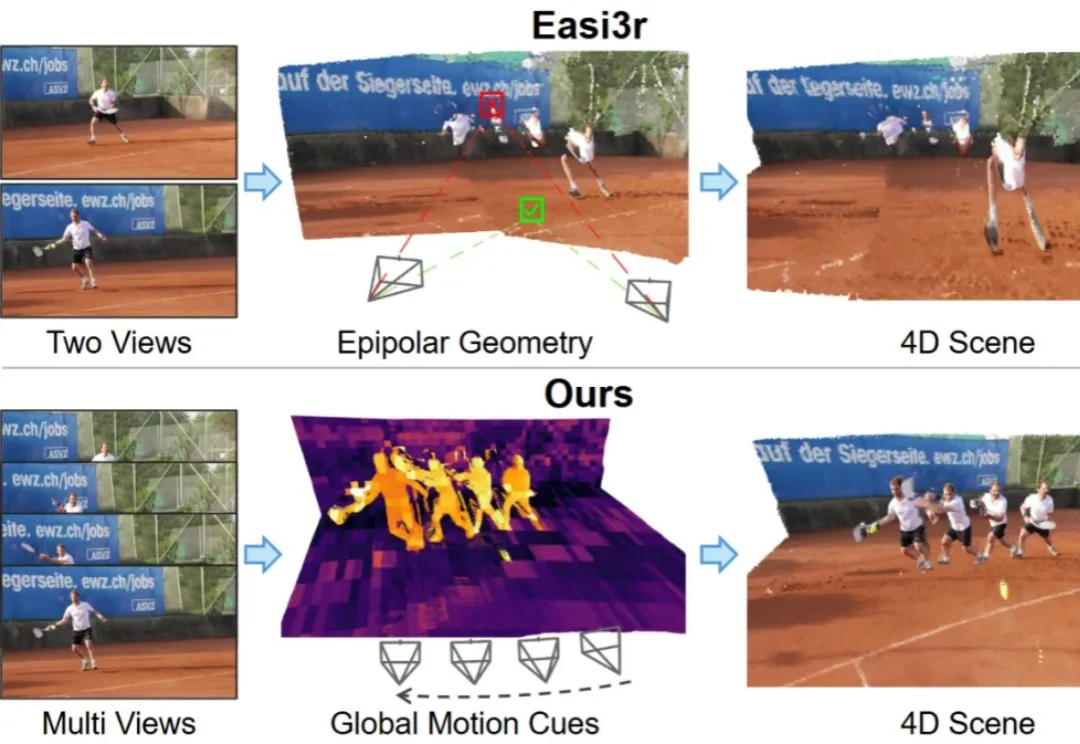
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?

开源模型再次迎来一位重磅选手,就在刚刚,小米正式发布并开源新模型 MiMo-V2-Flash。

Canvas-to-Image 是一种新型图像生成框架,将多种控制方式(如身份、姿态、空间布局)整合到一个统一画布中,用户可通过直观操作生成高保真、多控制的图像。它简化了创作流程,让用户在单一界面完成复杂创作,为AI创作工具提供了新范式。

生成式模型正在成为机器人和具身智能领域的重要范式,它能够从高维视觉观测中直接生成复杂、灵活的动作策略,在操作、抓取等任务中表现亮眼。但在真实系统中,这类方法仍面临两大「硬伤」:一是训练极度依赖大规模演示数据,二是推理阶段需要大量迭代,动作生成太慢,难以实时控制。
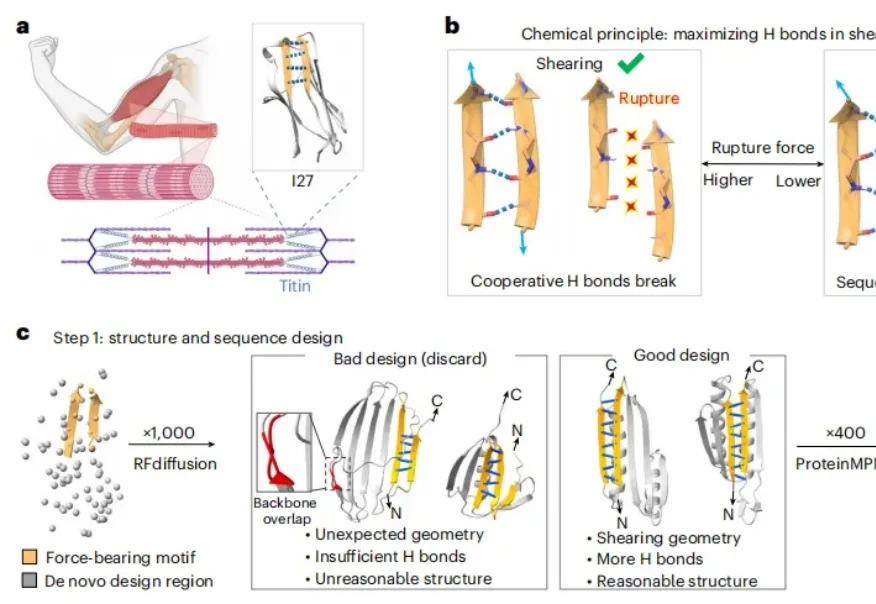
近日,南京大学教授郑鹏和团队造出一种全新的超级蛋白质,不仅比人体肌肉组织里的天然蛋白质坚韧 4 倍以上,而且还能在开水里安然无恙,甚至能够承受 150℃ 的高温,这打破了人们对于蛋白质怕热的固有印象。蛋白质的机械强度被人工设计提升到纳牛顿的级别,堪比自然界已知的最坚韧的一些分子相互作用。
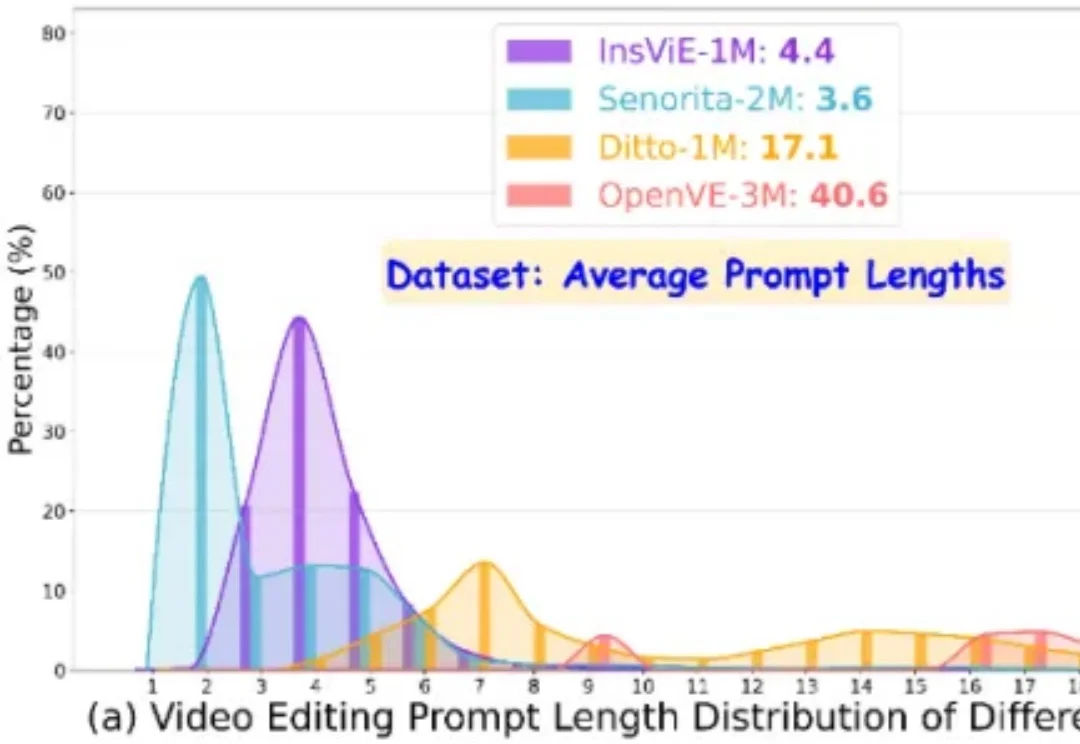
作者提出了一个大规模、高质量、多类别的指令跟随的视频编辑数据集 OpenVE-3M,共包含 3M 样本对,分为空间对齐和非空间对齐 2 大类别共 8 小类别。
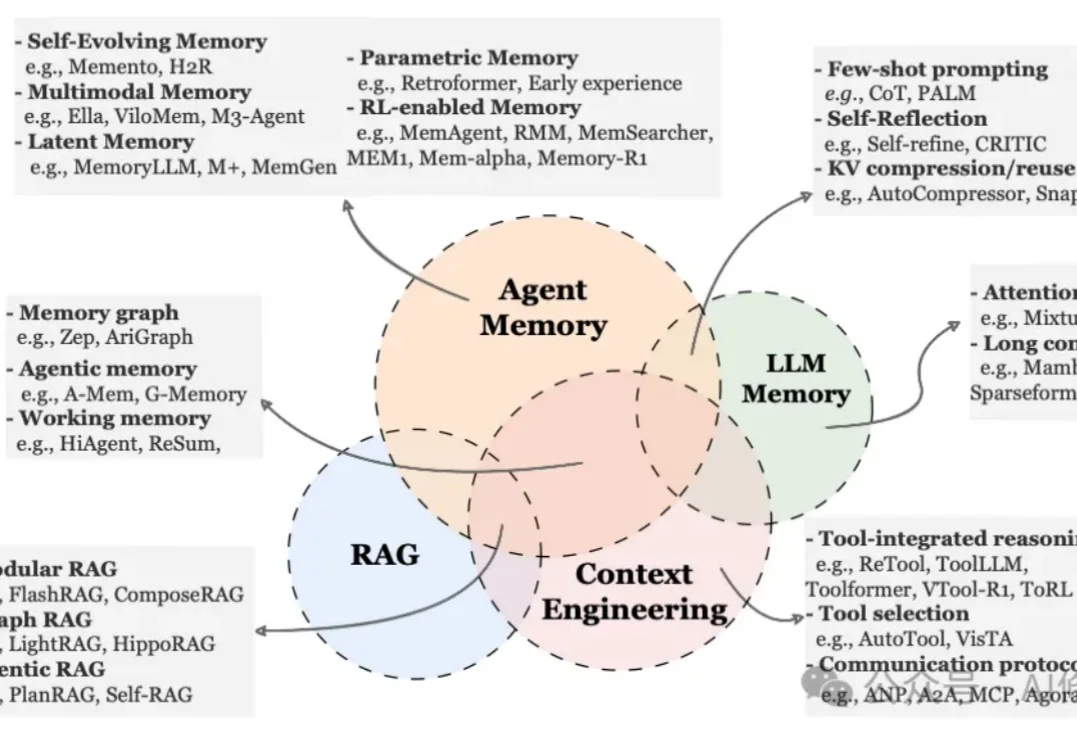
就在昨天,新加坡国立大学、中国人民大学、复旦大学等多所顶尖机构联合发布了一篇AI Agent 记忆(Memory)综述。

通用大模型(LLM)的狂飙突进,终于在医疗垂直领域的「最后一公里」撞上了硬墙。虽然 ChatGPT 在 USMLE(美国执业医师资格考试)中表现优异,但在面对需要「火眼金睛」和「毫厘必争」的心脏手术台上,通用大模型的表现究竟如何?
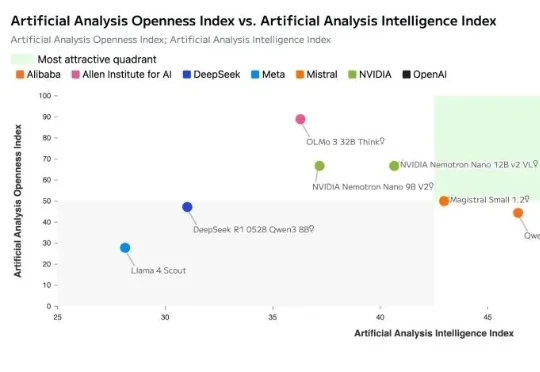
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。
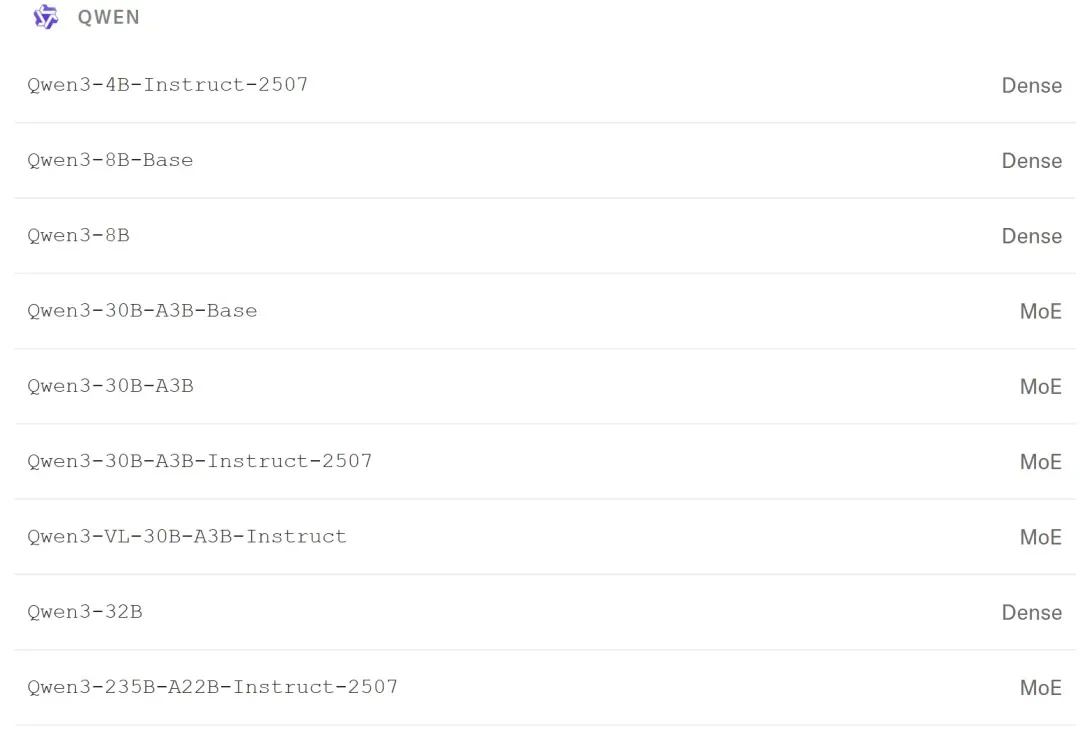
当前,AI 领域的研究者与开发者在关注 OpenAI、Google 等领先机构最新进展的同时,也将目光投向了由前 OpenAI CTO Mira Murati 创办的 Thinking Machines Lab。

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。

南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。

近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。

随着通用型(Generalist)机器人策略的发展,机器人能够通过自然语言指令在多种环境中完成各类任务,但这也带来了显著的挑战。
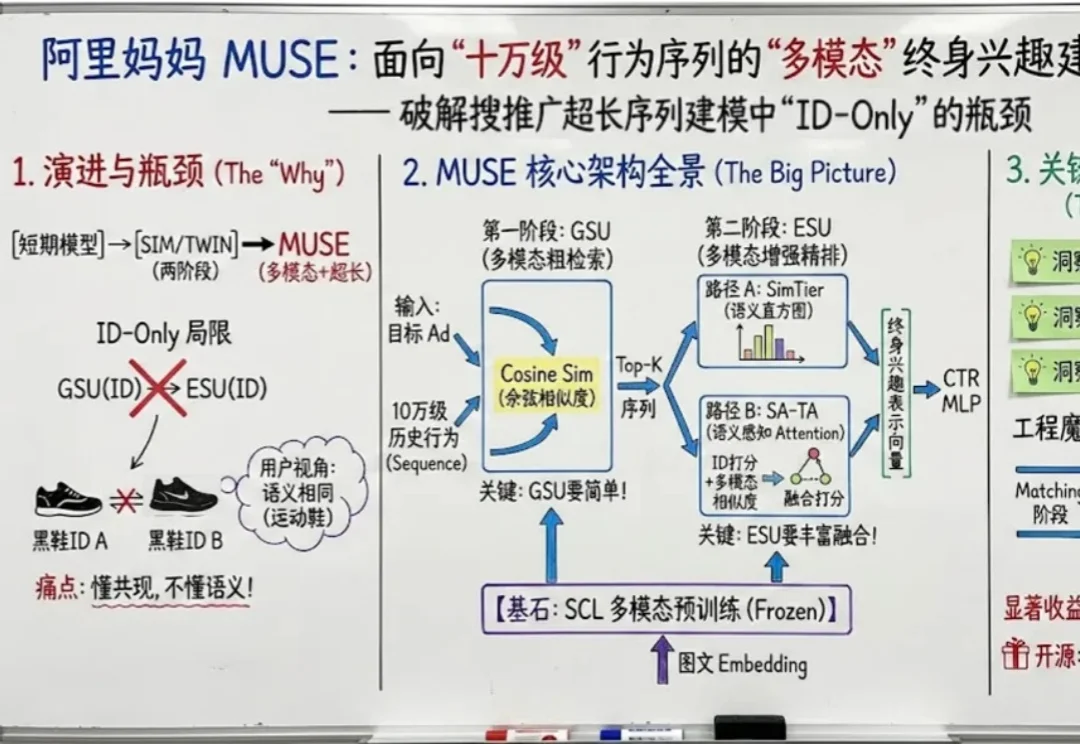
如果把用户在互联网上留下的每一个足迹都看作一段记忆,那么现在的推荐系统大多患有 “短期健忘症”。
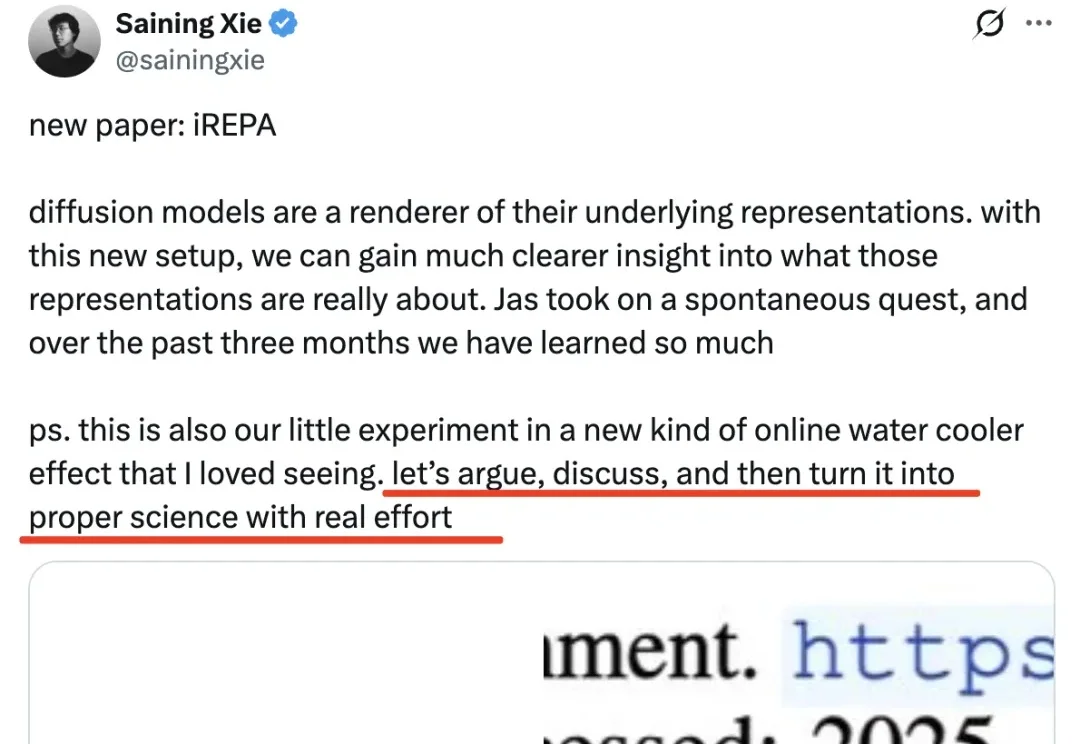
要说真学术,还得看推特。

模型架构的重要性可能远超我们之前的认知。

前有 vibe coding ,随着 nano banana 升级 pro, vibe PPT 也跟着来了。最近我在 GitHub 上挖到一个项目:banana slides 。这是一个基于 nano banana pro 的原生 AI PPT 生成应用。

最近,网友们已经被AI「手指难题」逼疯了。给AI一支六指手,它始终无法正确数出到底有几根手指!说吧AI,你是不是在嘲笑人类?其实这背后,暗藏着Transformer架构的「阿喀琉斯之踵」……
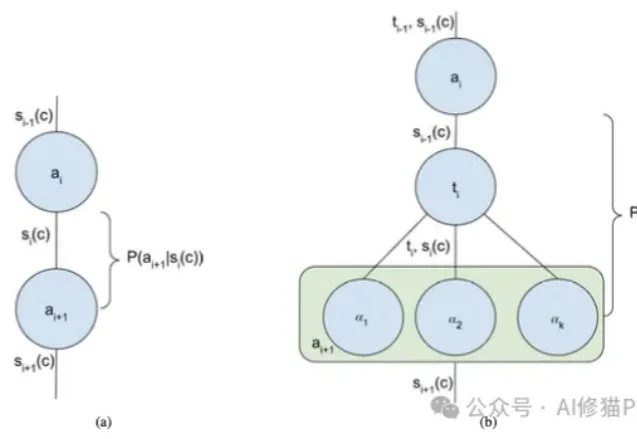
我们正处在一个AI Agent(智能体)爆发的时代。从简单的ReAct循环到复杂的Multi-Agent Swarm(多智能体蜂群),新的架构层出不穷。但在这些眼花缭乱的名词背后,开发者的工作往往更像是一门“玄学”,我们凭直觉调整提示词,凭经验增加Agent的数量,却很难说清楚为什么某个架构在特定任务上表现更好。