
突破单链思考上限,清华团队提出原生「并行思考」scale范式
突破单链思考上限,清华团队提出原生「并行思考」scale范式近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
来自主题: AI技术研报
7982 点击 2025-09-18 14:49
 搜索
搜索
近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。
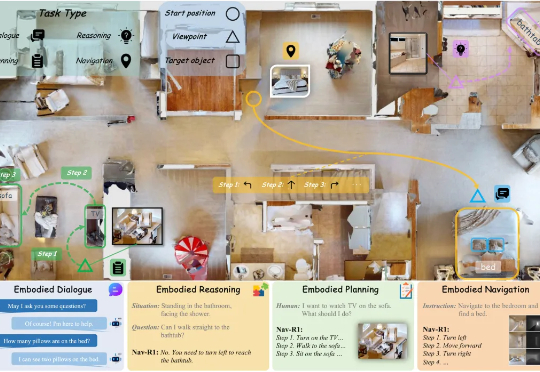
这篇题为《Nav-R1: Reasoning and Navigation in Embodied Scenes》的新论文,提出了一个新的「身体体现式(embodied)基础模型」(foundation model),旨在让机器人或智能体在 3D 环境中能够更好地结合「感知 + 推理 + 行动」。简单说,它不仅「看到 + 听到+开动马达」,还加入清晰的中间「思考」环节。
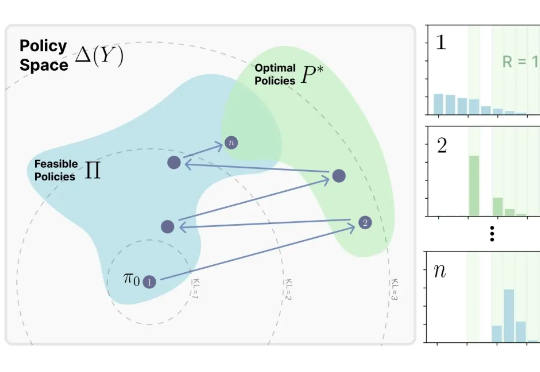
来自MIT Improbable AI Lab的研究者们最近发表了一篇题为《RL's Razor: Why Online Reinforcement Learning Forgets Less》的论文,系统性地回答了这个问题,他们不仅通过大量实验证实了这一现象,更进一步提出了一个简洁而深刻的解释,并将其命名为 “RL's Razor”(RL的剃刀)。

通义DeepResearch团队 投稿 量子位 | 公众号 QbitAI 阿里开源旗下首个深度研究Agent模型通义DeepResearch! 相比于基于基础模型的ReAct Agent和闭源Deep
近日,伦敦国王学院的一项心理学研究表明,ChatGPT等AI工具的使用可能促进或加重精神病(AI psychosis)。研究表示,AI聊天中的奉承、迎合用户方式,可能放大人类的妄想思维,从而导致精神疾病。
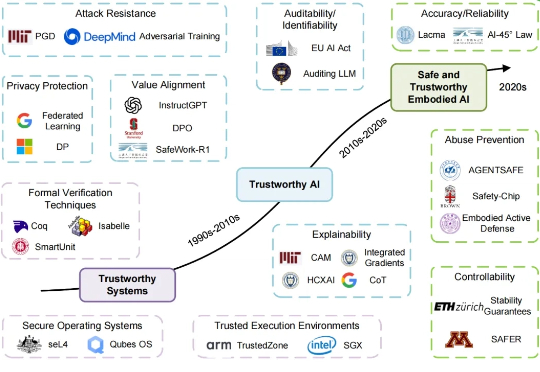
近年来,以人形机器人、自动驾驶为代表的具身人工智能(Embodied Artificial Intelligence, EAI)正以前所未有的速度发展,从数字世界大步迈向物理现实。然而,当一次错误的风险不再是屏幕上的一行乱码,而是可能导致真实世界中的物理伤害时,一个紧迫的问题摆在了我们面前: 如何确保这些日益强大的具身智能体是安全且值得信赖的?
谷歌DeepMind研究团队一年前的研究成果直到昨晚才姗姗揭秘,提出了一种叫做GDR的新方法,颠覆了传统训练中设法剔除脏数据的思路,将饱含恶意内容的数据「变废为宝」,处理后的数据集用于训练,甚至比直接剔除脏数据训练出的模型效果还好,「出淤泥而不染」,「择善而从」。
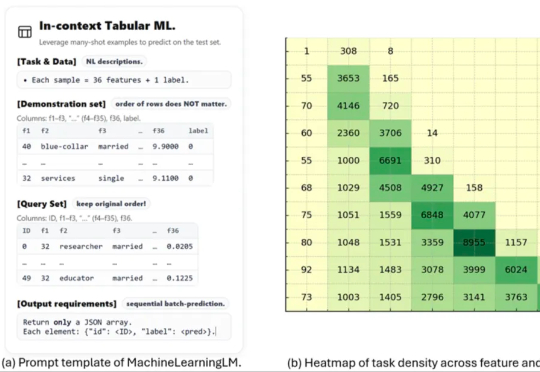
这项名为 MachineLearningLM 的新研究突破了这一瓶颈。该研究提出了一种轻量且可移植的「继续预训练」框架,无需下游微调即可直接通过上下文学习上千条示例,在金融、健康、生物信息、物理等等多个领域的二分类 / 多分类任务中的准确率显著超越基准模型(Qwen-2.5-7B-Instruct)以及最新发布的 GPT-5-mini。

顶级大模型在AAI提出的FormulaOne基准集体翻车:三层难度递进,GPT-5进阶题仅约4%正确,最深层零分;Grok 4、o3 Pro全部失手。该基准以图上MSO逻辑与动态规划生成问题,贴近路径规划等现实优化,旨在衡量超越竞赛编程的算法推理深度。

只要科学任务可以评分,AI就能找到超越人类专家的方法,实现SOTA结果? 这是谷歌一篇最新论文里的内容: 使用大模型+树搜索,让AI大海捞针就行。
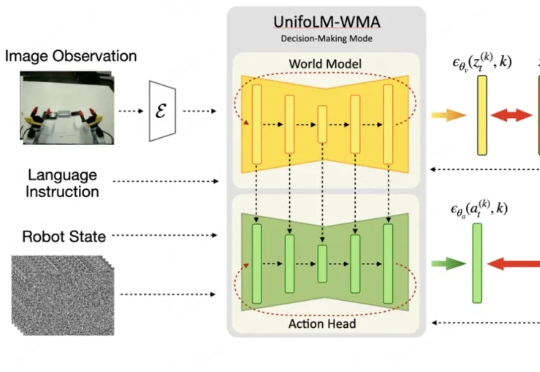
一觉醒来,宇树带着最新开源模型来了!这次开源的是一个世界模型-动作架构,名叫UnifoLM-WMA-0。它的核心之处在于拥有一个世界模型能够理解机器人和环境相互作用时的物理规律。

ChatGPT首份使用报告重磅上线!周月活飙至7亿,它已成为高学历白领的办公利器,编程却成为冷门。同时,Anthropic最新报告称,人们交给Claude完成任务暴涨至49%。

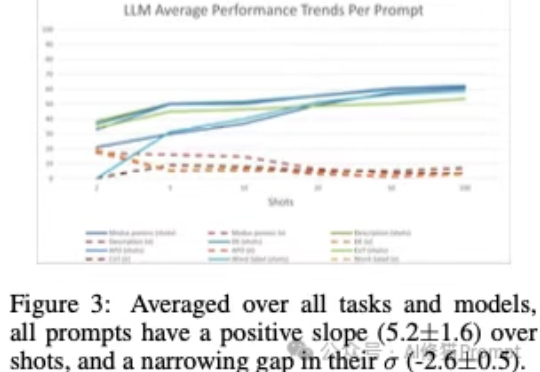
很多人认为,Scaling Law 正在面临收益递减,因此继续扩大计算规模训练模型的做法正在被质疑。最近的观察给出了不一样的结论。研究发现,哪怕模型在「单步任务」上的准确率提升越来越慢,这些小小的进步叠加起来,也能让模型完成的任务长度实现「指数级增长」,而这一点可能在现实中更有经济价值。

首份最全ChatGPT用户研究报告来了!

凌晨 1 点,OpenAI 发布了 GPT-5-Codex。

智东西9月15日报道,今天,阿里巴巴通义实验室推出了FunAudio-ASR端到端语音识别大模型。这款模型通过创新的Context模块,针对性优化了“幻觉”、“串语种”等关键问题,在高噪声的场景下,幻觉率从78.5%下降至10.7%,下降幅度接近70%。
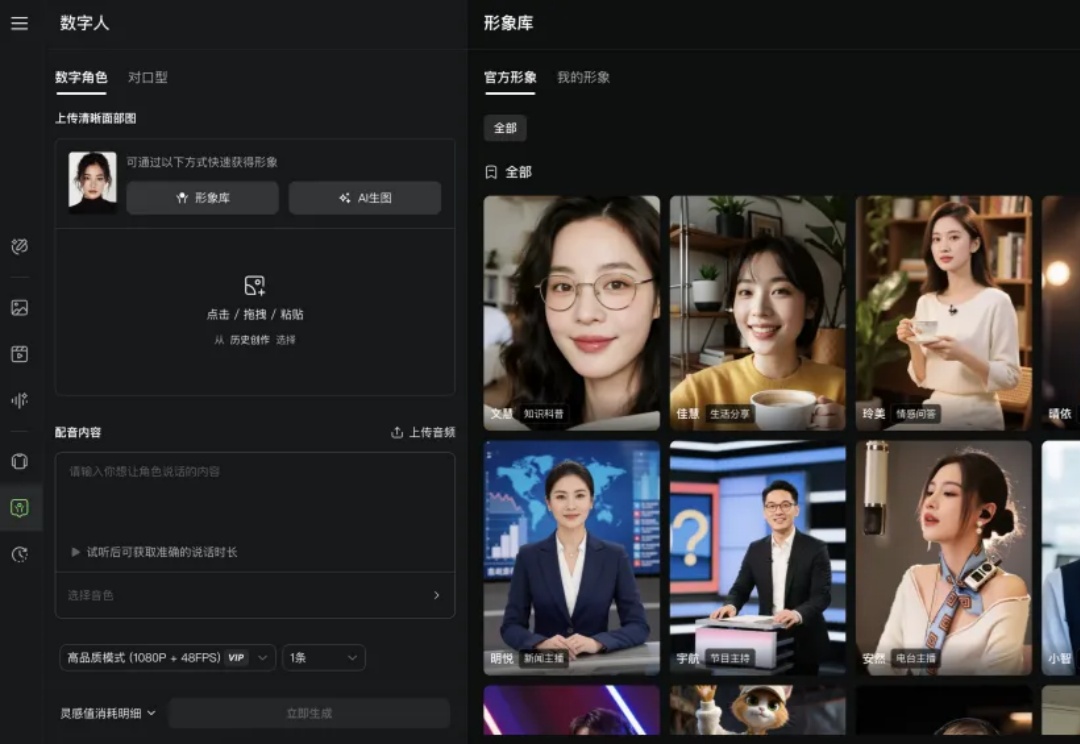
让数字人的口型随着声音一开一合早已不是新鲜事。更令人期待的,是当明快的旋律响起,它会自然扬起嘴角,眼神含笑;当进入说唱段落,它会随着鼓点起伏,肩膀与手臂有节奏地带动气氛。
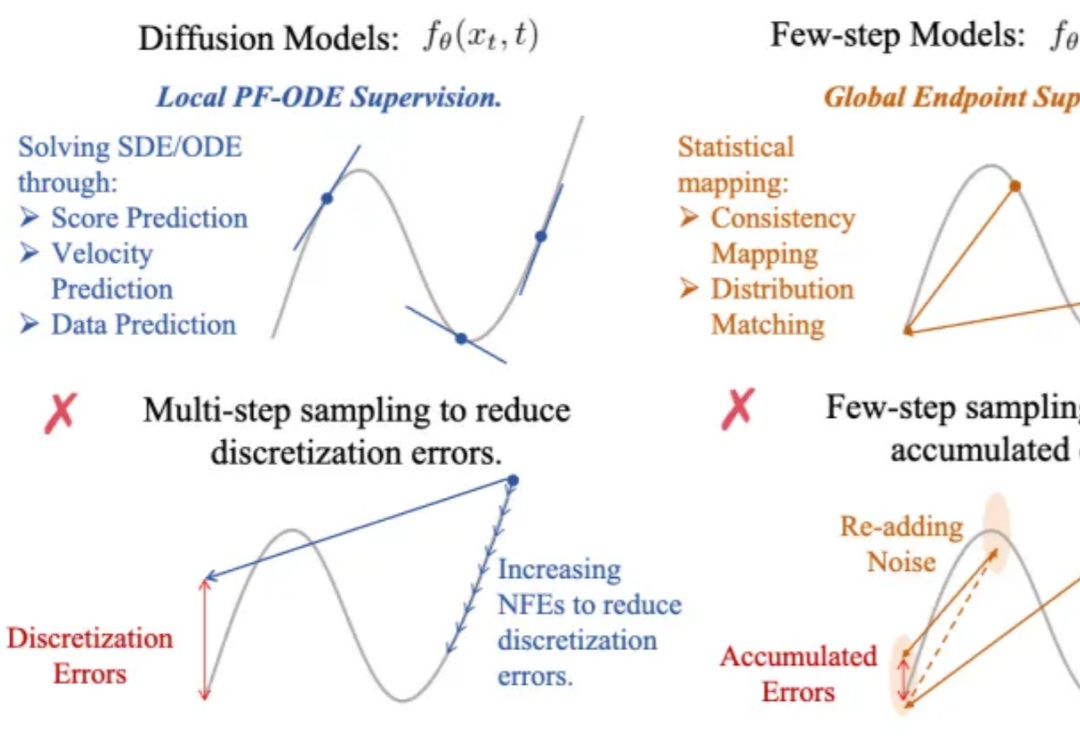
生成式AI的快与好,终于能兼得了?

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。

Nano Banana如此火爆,让谷歌DeepMind CEO哈萨比斯在最新访谈中又一次聊起了AGI。Nano Banana当然不是AGI,但它也体现了哈萨比斯认为AGI系统所需的一些关键能力和特征。
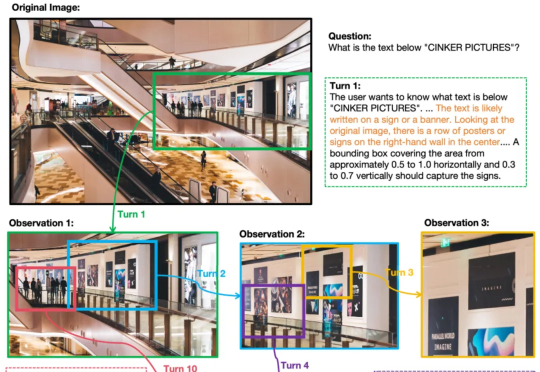
OpenAI o3的多轮视觉推理,有开源平替版了。并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复
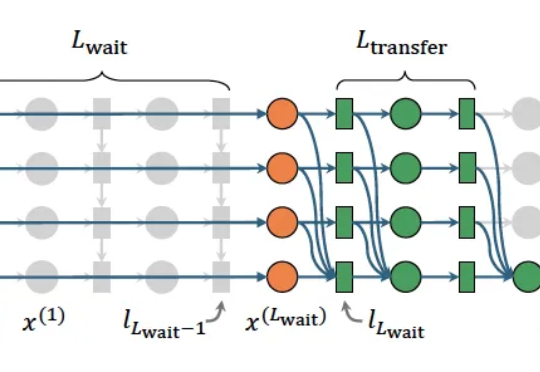
最近,来自加州大学圣克鲁兹分校、乔治·梅森大学和Datadog的研究人员发现:在心算任务中,几乎所有实际的数学计算都集中在序列的最后一个token上完成,而不是分散在所有token中。
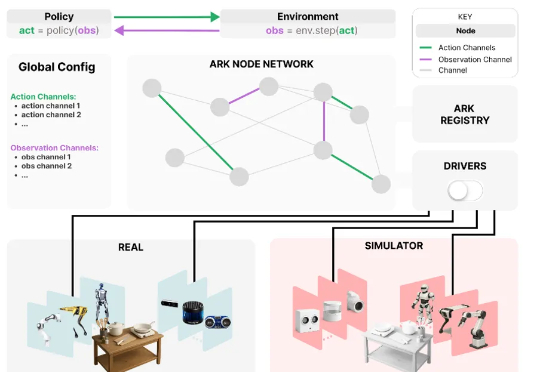
为应对这些挑战,来自华为诺亚方舟实验室,德国达姆施塔特工业大学,英国伦敦大学学院,帝国理工学院和牛津大学的研究者们联合推出了 Ark —— 一个基于 Python 的机器人开发框架,支持快速原型构建,并可便捷地在仿真和真实机器人系统上部署新算法。
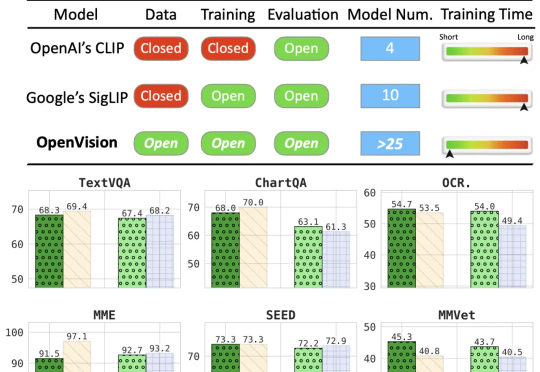
本文来自加州大学圣克鲁兹分校(UCSC)、苹果公司(Apple)与加州大学伯克利分校(UCB)的合作研究。第一作者刘彦青,本科毕业于浙江大学,现为UCSC博士生,研究方向包括多模态理解、视觉-语言预训

就在刚刚,Anthropic 发布了一报告,名字听上去有点学术腔——《人类经济指数》。 但别被这个名字骗了,它是一份非常具体、非常当下的观察笔记,可以说和我们息息相关。 原文链接:https://ww
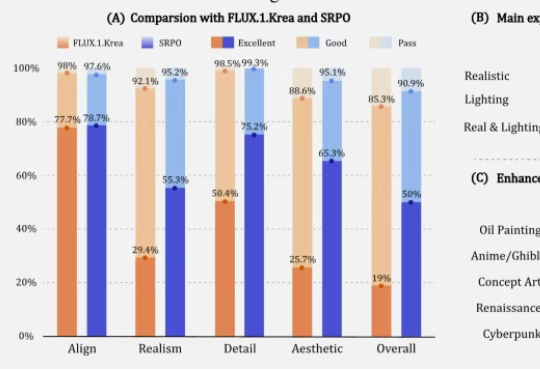
让AI生成的图像更符合人类精细偏好,在32块H20上训练10分钟就能收敛。腾讯混元新方法让微调的FLUX1.dev模型人工评估的真实感和美学评分提高3倍以上。

见过省电的模型,但这么省电的,还是第一次见。 在 《自然》 杂志发表的一篇论文中,加州大学洛杉矶分校 Shiqi Chen 等人描述了一种几乎不消耗电量的 AI 图像生成器的开发。

今天咱们来聊一下,哪些AI办公产品真的能帮你干活?