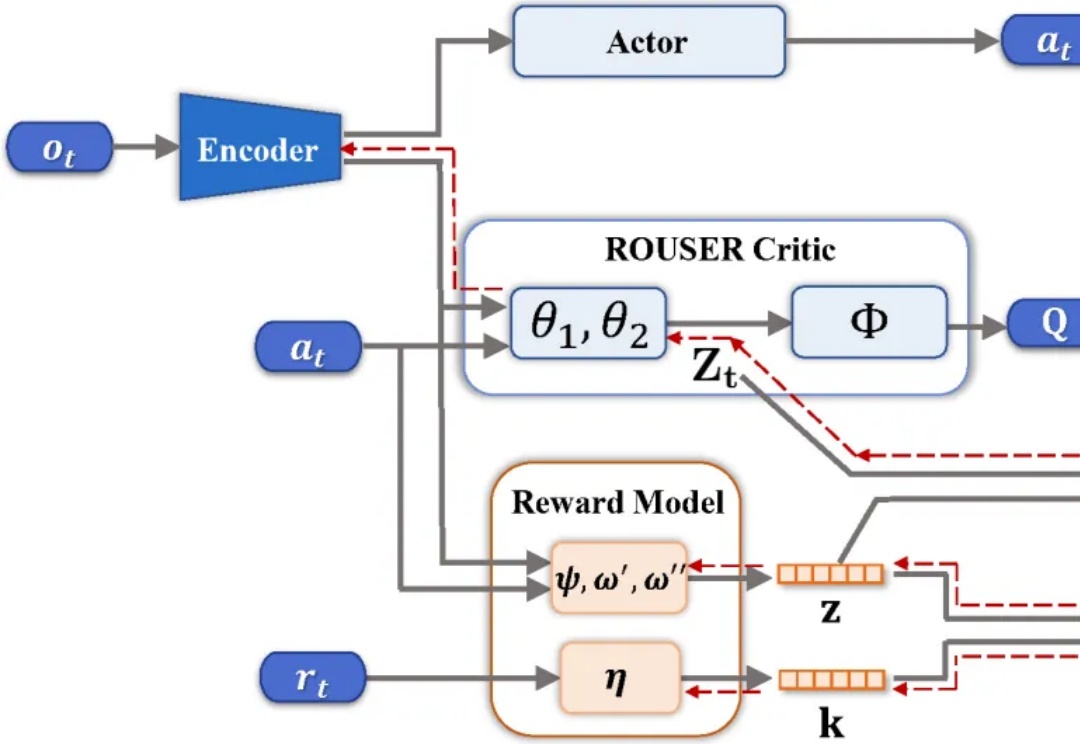
中科大提出动作价值表征学习新方法,率先填补长期决策信息的缺失
中科大提出动作价值表征学习新方法,率先填补长期决策信息的缺失在视觉强化学习中,许多方法未考虑序列决策过程,导致所学表征缺乏关键的长期信息的空缺被填补上了。
来自主题: AI技术研报
4056 点击 2025-03-31 15:16
 搜索
搜索
在视觉强化学习中,许多方法未考虑序列决策过程,导致所学表征缺乏关键的长期信息的空缺被填补上了。

两家期刊实验表明,250美元报酬,能加快评审速度而不降低质量。但专家警告,现金激励可能悄然改变科研生态,这将为学术评审带来新生,还是埋下隐患?
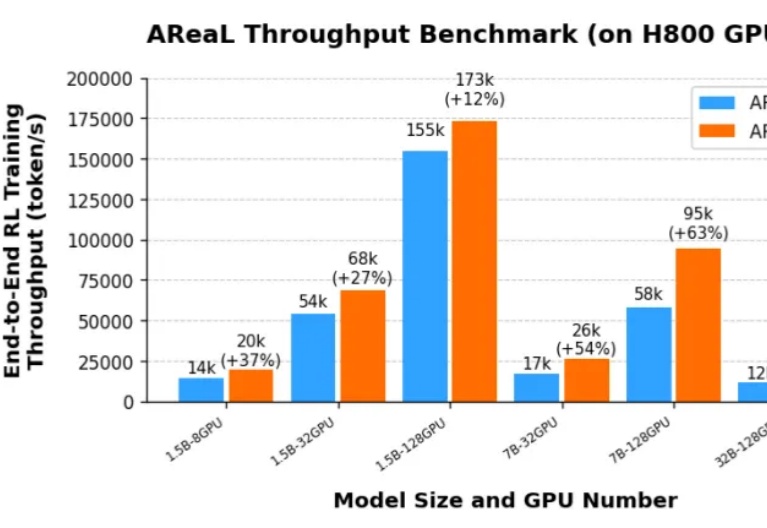
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:
最近超火的氛围编程(Vibe coding)你听说了吗?

好好好,具身智能领域又有公司宣布融资新动态了!

GPT-4o玩家太疯狂,奥特曼紧急呼吁别再生成图片了:OpenAI团队为此一直在熬夜。为什么需要熬夜呢,自原生图像生成推出以来,必须一直有人守着才能保持服务器在线。

说真的,即使玩过了这么多的DeepResearch产品,我也没想到,他们能扔出个这么个有趣的玩意。这个产品叫做,AutoGLM沉思版。
押注新赛道。

当前,医疗保健和生命科学领域,人工智能的采用非常强劲。
对于美国金融传媒巨头彭博新闻社而言,今年1月引入的AI新闻摘要功能目前仍处在磕磕绊绊的磨合期。