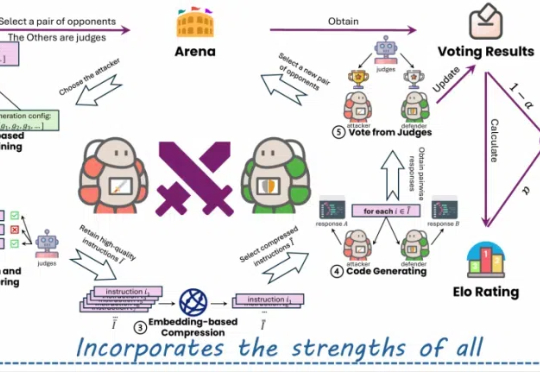
微软原WizardLM团队:代码大模型WarriorCoder,性能新SOTA
微软原WizardLM团队:代码大模型WarriorCoder,性能新SOTA近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。
来自主题: AI技术研报
10586 点击 2025-03-02 14:13
 搜索
搜索
近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。
原来,大型推理模型(Large Reasoning Model,LRM)像人一样,在「用脑过度」也会崩溃,进而行动能力下降。

BPO服务商往往处理周期漫长;因缺乏相关背景信息和权限,某些任务难以保质完成——终端客户的体验低效且充满挫败感。
这家初创公司希望让大公司争夺大众市场,而自己专注于吸引行业专业人士,并与 Lionsgate 达成一笔里程碑式的交易。
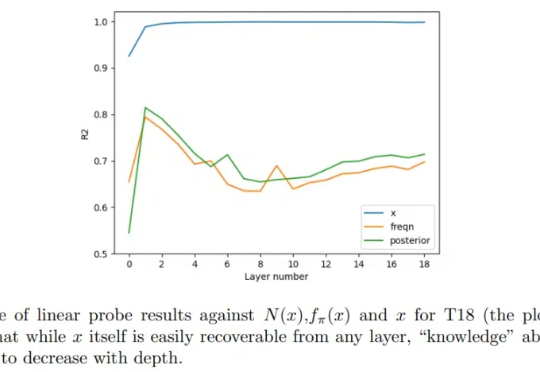
Transformer 很成功,更一般而言,我们甚至可以将(仅编码器)Transformer 视为学习可交换数据的通用引擎。由于大多数经典的统计学任务都是基于独立同分布(iid)采用假设构建的,因此很自然可以尝试将 Transformer 用于它们。

这份提示词有很多哲学性思考,很多表达让我看到背后的设计者把claude当成一个人去设计。 我猜,应该是Amanda Askell(Anthropic负责alignment和character design,是学哲学的一位女生,也是我的榜样) 主要设计的。

大概从三四个小时前开始,两家大模型公司潞晨科技创始人尤洋和硅基流动创始人袁进辉,在社交平台公开互怼。先是尤洋在知乎对袁进辉发难,发文《坑人的硅基流动》,尤洋称本来不想发这些东西,但是硅基流动的袁进辉老师频繁在朋友圈里阴阳他。"这家公司疑似组织水军在网上长期黑我。今天DeepSeek有一篇文章指向我,他也在那里煽风点火。"

3月1日,潞晨科技官微发布了两则消息。先是宣布:“尊敬的用户,潞晨云将在一周后停止提供DeepSeek API服务,请尽快用完您的余额。如果没用完,我们全额退款。”后又发布消息:“感谢网友的热心提醒,Colossal-AI此前发布对DeepSeek-R1(671B)模型的LoRA微调,在参数加载过程中因参数名称不匹配的Bug导致Loss异常,已在GitHub线上修复。”

DeepSeek公开推理系统架构,成本利润率可达545%!明天还有更大惊喜吗?

DeepSeek和xAI相继用R1和Grok-3证明:预训练Scaling Law不是OpenAI的护城河。将来95%的算力将用在推理,而不是现在的训练和推理各50%。OpenAI前途不明,生死难料!