
OpenAI砸200亿美元买单,英伟达挑战者冲刺350亿美元估值IPO
OpenAI砸200亿美元买单,英伟达挑战者冲刺350亿美元估值IPO一条消息引爆华尔街。
来自主题: AI资讯
8428 点击 2026-05-11 16:49
 搜索
搜索
一条消息引爆华尔街。
各种单点的 AI 生图、生视频工具,我们平时已经聊过很多了。关注行业风向的朋友应该能察觉到,现在的 AIGC 正在经历一个分水岭:大家不再满足于用 AI 跑出一张精美的图,或者几秒钟用来炫技的动态片段。

xAI撤销后,新的SpaceXAI正在建立。

如果你让大模型给林黛玉找一个外国文学里的平替,它能给出令人信服的答案吗?这个脑洞的背后其实是当下人工智能最核心的软肋——“类比推理”能力。
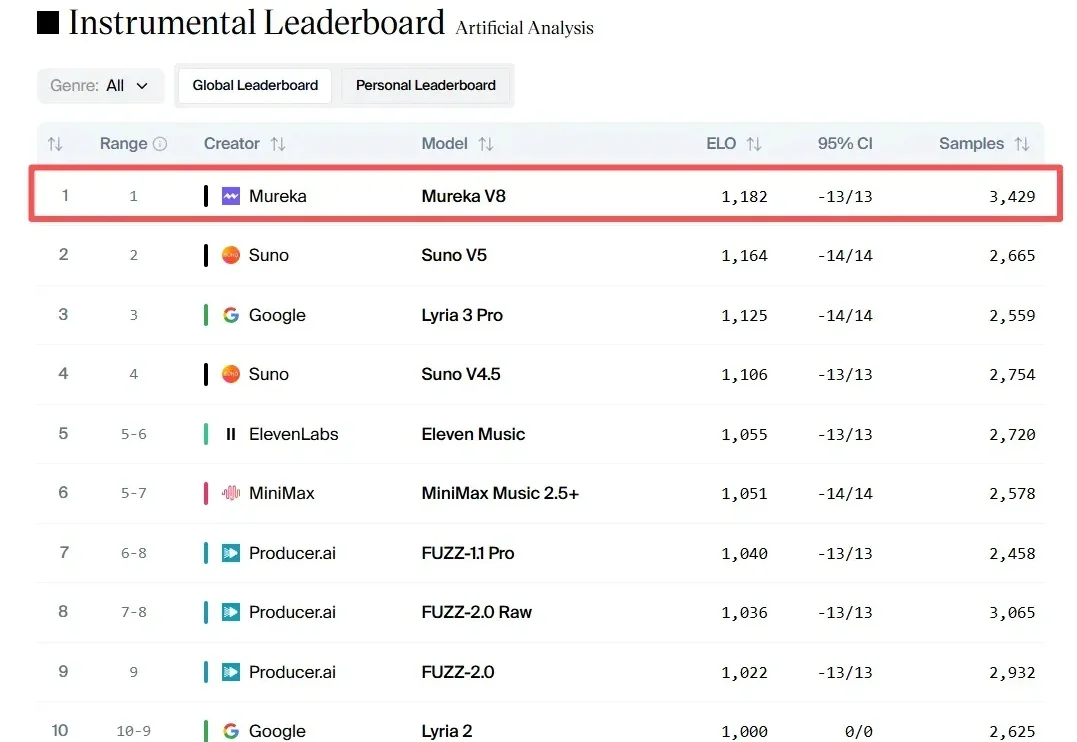
在 AI 音乐行业,有一个正在悄悄发生的迁移。

机器人拉个拉链,到底需不需要“脑子”?

这是一个“等待被大厂吞没”的行业,还是可能长出像Adobe那样的工具型公司?

4月5日至5月5日,北京同仁堂与阿里生态下的淘宝买药、夸克、飞猪及高德地图展开了一场为期一个月的深度联动。
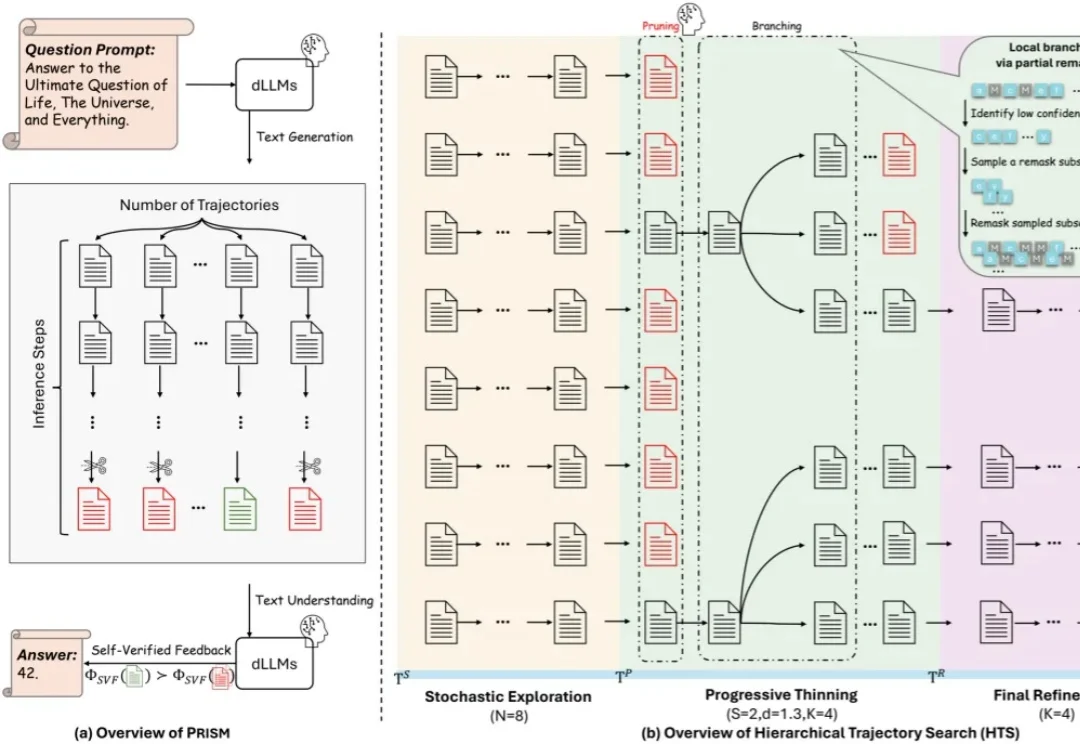
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。