
老人想戒盐。听了AI建议后,不仅患上罕见病,还成了精神病.....
老人想戒盐。听了AI建议后,不仅患上罕见病,还成了精神病.....随着ChatGPT,DeepSeek等一批AI大模型被人们越来越多运用到日常生活和工作中,用ChatGPT解答疑问,编写程序,创作音乐和写作,成为了越来越多人的日常。
来自主题: AI资讯
9142 点击 2025-08-18 16:25
 搜索
搜索
随着ChatGPT,DeepSeek等一批AI大模型被人们越来越多运用到日常生活和工作中,用ChatGPT解答疑问,编写程序,创作音乐和写作,成为了越来越多人的日常。
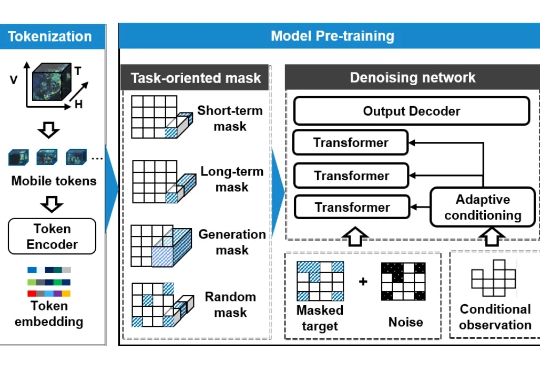
在今年的 ACM KDD 2025 大会上,清华大学电子系团队联合中国移动发布了 UoMo,全球首个面向移动网络的通用流量预测模型。UoMo 能同时胜任短期预测、长期预测,甚至在没有历史数据的情况下生成全新区域的流量分布。

忘掉你学过的一切提示词技巧吧,你只需要这一个就够了。
作为老牌企业软件巨头 IgniteTech 公司 CEO,Eric Vaughan 在回顾自己数十年职业生涯中最激进的决策时,仍然意志坚定、毫不动摇。

鲨疯了!一周连发六款模型。火力全开的昆仑万维,正在把多模态AI卷到新高度。8月11日~15日,这家公司天天都有新模型掉落,覆盖的还都是视频生成、世界模型、统一多模态、智能体以及AI音乐创作这些大热门,几乎每一个都是多模态AI应用的核心场景。
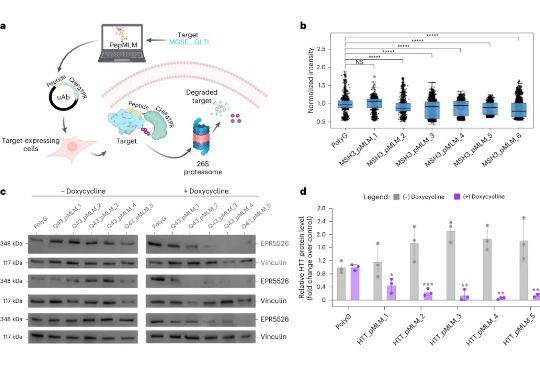
在药物研发领域,针对“难成药靶点”开发药物一直是难题。 由于失败风险极高,需要巨大的资金和时间投入,许多公司倾向于优先选择“低垂果实”,即更容易成药的靶点,导致许多疾病无药可医。
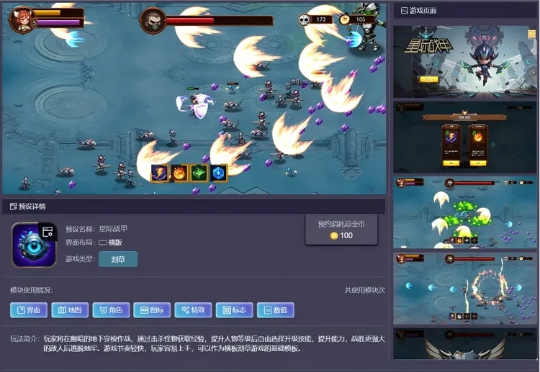
7月30日小规模上线测试后,soon很快在游戏圈掀起热议,它可以让你“一句话生成一个游戏”,而且是真正能玩的那种。

智东西8月17日报道,今天,世界人形机器人运动会医药场景药物分拣比赛决赛落下帷幕。从初赛到复赛,银河通用Galbot队全程零遥操作、完全自主运行,预赛、复赛及决赛均为第一,最终以10分22秒用时,336分的总赋分夺得本场赛事冠军。
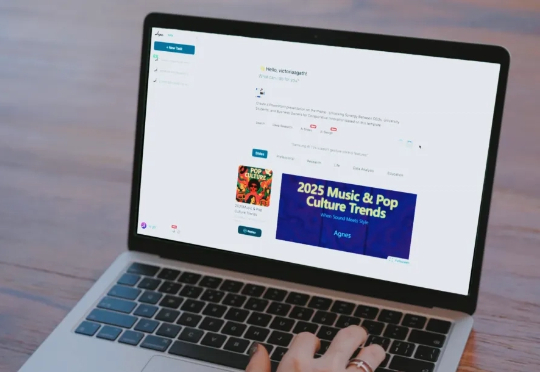
真正的 AI 系统不是一个 Chat 窗口,而是一个智能的工作现场。 工具越多,效率反而越低?一项来自《哈佛商业评论》的调查显示,员工每天平均切换应用程序超过 1200 次,一年下来累计浪费的时间高达 5 个完整工作周,占全年总工作时间的 9%。

最近,这家由前 Meta 和世嘉老兵组建AI游戏公司Studio Atelico,宣布完成500 万美元种子轮融资,由专AI的风投 Air Street Capital 领投,Hugging Face 核心成员 Thomas Wolf 参投,高调宣布要重新定义游戏体验 ,他们的目标,是让每个玩家都能拥有独一无二的动态世界。