
8个月晋升独角兽,欧洲版Cursor估值18亿美元
8个月晋升独角兽,欧洲版Cursor估值18亿美元成立仅8个月已成为最新独角兽,估值飙升至18亿美元。 目前已拥有超230万免费活跃用户、18万付费订阅者,付费用户首月留存率甚至已超ChatGPT。
来自主题: AI资讯
8597 点击 2025-07-19 11:52
 搜索
搜索
成立仅8个月已成为最新独角兽,估值飙升至18亿美元。 目前已拥有超230万免费活跃用户、18万付费订阅者,付费用户首月留存率甚至已超ChatGPT。
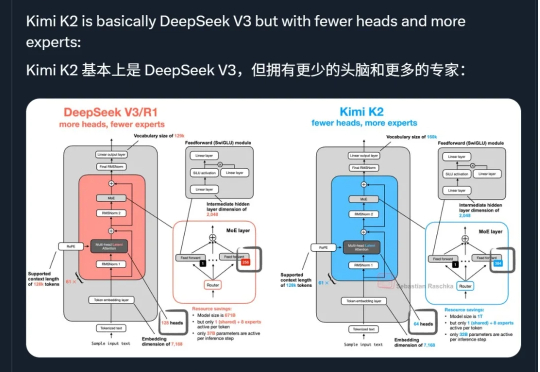
几千人盲投,Kimi K2超越DeepSeek拿下全球开源第一!
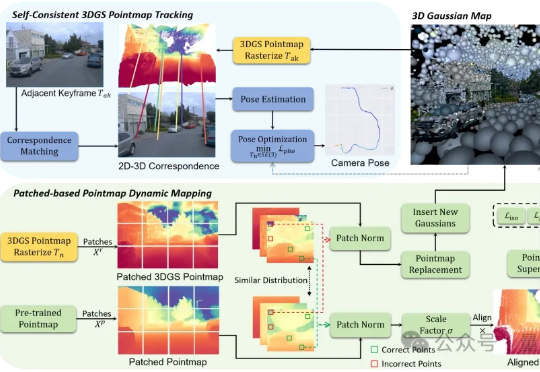
户外SLAM的尺度漂移问题,终于有了新解法! 香港科技大学(广州)的研究的最新成果:S3PO-GS,一个专门针对户外单目SLAM的3D高斯框架,已被ICCV 2025接收。
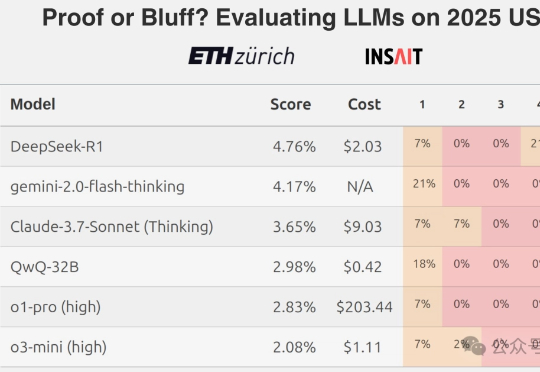
AI做奥数的神话,刚刚被戳破了!最新出炉的2025 IMO数学竞赛中,全球顶尖AI模型无一例外翻车了。即便是冠军Gemini也只拿下可怜的31分,连铜牌都摸不到。Grok-4更是摆烂到底,连DeepSeek-R1都令人失望。看来,AI想挑战人类奥数大神,还为时尚早。

前几天,Kimi 彻底开源了它的旗舰模型Kimi K2。不仅代码、权重全免费,还放出MIT许可,任企业随便商用。

近期,Anthropic 旗下的旗舰编码助手 Claude Code 的 Max 用户(每月200美元)遭遇无预警限流,平台未提供清晰说明,也无提前通知,引发广泛不满和用户信任危机。这起事件不仅暴露了大模型服务商在资源管理上的短板,也揭示出当前 AI 订阅制平台在“透明度”与“服务承诺”之间的矛盾。

红杉美国合伙人 Konstantine Buhler 预测 2025 年将成为 AI agent 的“群体协作”时代,标志着 Agent 元年的到来。
2025 年 7 月 15 日,韩国游戏创企 Planetarium Labs 宣布,公司旗下 AI 游戏创作分享平台 Verse 8 已正式在 Web 端上线。根据 Planetarium Labs 介绍,在 AI 游戏开发助手 Agent 8 的辅助下,用户可以在 Verse 8 上利用自然语言开发、发行以及分享游戏,不需要下载和安装任何软件/资源。
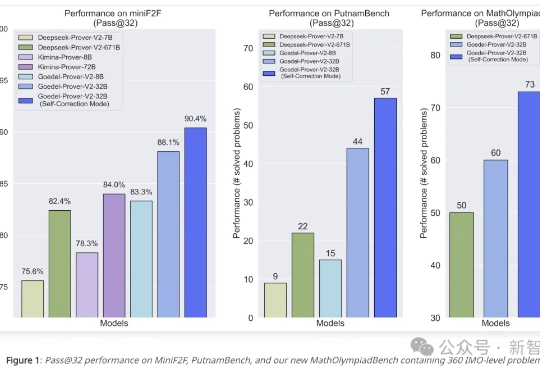
迄今为止最强大的开源定理证明器登场!Goedel-Prover-V2仅用8B参数击败671B的DeepSeek-Prover,并再次夺下数学PutnamBench冠军。十位核心贡献者,八大顶尖机构,让AI形式化证明再破纪录。

你可能听说过OpenAI的Sora,用数百万视频、千万美元训练出的AI视频模型。 但你能想象,有团队只用3860段视频、不到500美元成本,也能在关键任务上做到SOTA?