
互联网大厂,不再需要AI Lab
互联网大厂,不再需要AI Lab4月29日,腾讯TEG进行架构调整,新成立大语言和多模态模型部,并对数据平台和机器学习平台职责进行调整。
来自主题: AI资讯
9025 点击 2025-05-09 14:28
 搜索
搜索
4月29日,腾讯TEG进行架构调整,新成立大语言和多模态模型部,并对数据平台和机器学习平台职责进行调整。

近日,来自SGLang、英伟达等机构的联合团队发了一篇万字技术报告:短短4个月,他们就让DeepSeek-R1在H100上的性能提升了26倍,吞吐量已非常接近DeepSeek官博数据!

红杉资本预计AI市场规模将远超当前约4000亿美元的云计算市场,在未来10-20年内达到难以估量的体量。初创企业需聚焦应用层,深耕垂直领域,提供端到端解决方案。AWS研究显示,全球企业正加速拥抱生成式AI,首席AI官(CAIO)职位将成为企业标配。

5 月 7 日,由 GOSIM、CSDN 和 1ms.ai 联合主办的全球开源技术盛会——GOSIM AI Paris 2025 在法国巴黎迎来了大会第二日的精彩议程。延续首日的热烈氛围,来自全球的 AI 专家、开发者和产业代表齐聚一堂,围绕 AI 技术的最新趋势与实践展开深入探讨。
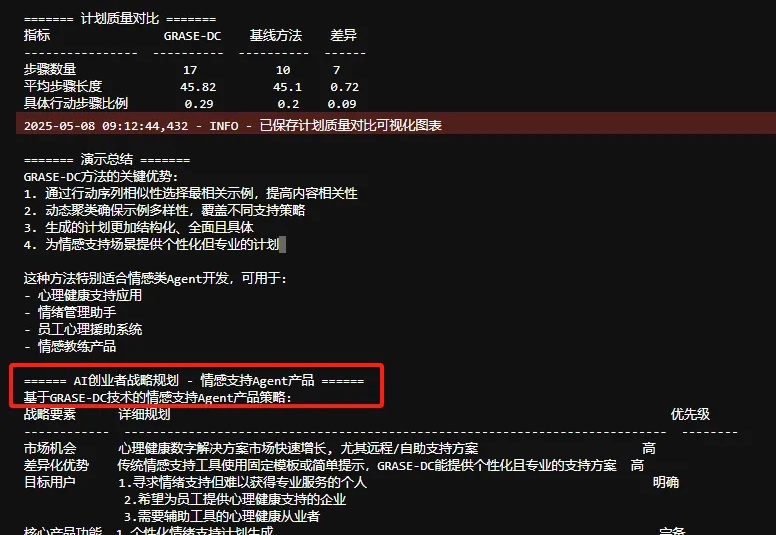
当您的Agent需要规划多步骤操作以达成目标时,比如游戏策略制定或旅行安排优化等等,传统规划方法往往需要复杂的搜索算法和多轮提示,计算成本高昂且效率不佳。来自Google DeepMind和CMU的研究者提出了一个简单却非常烧脑的问题:我们是否一直在用错误的方式选择示例来引导LLM学习规划?

智能体趋势真的爆了。
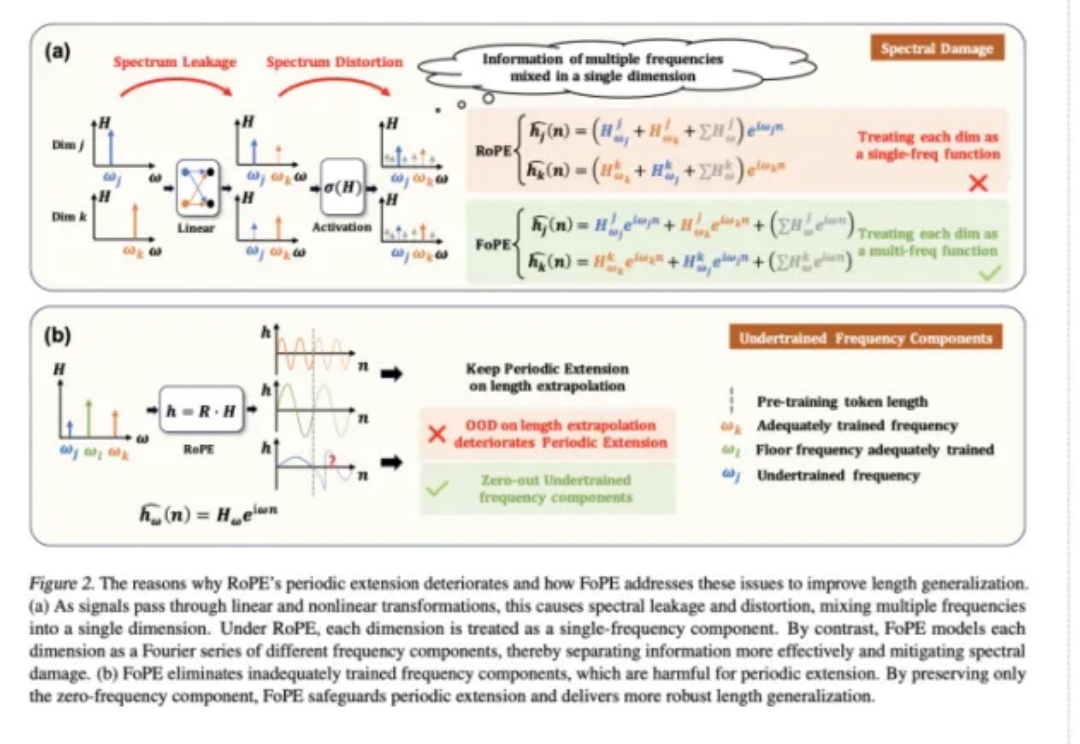
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。
游戏在20 世纪 90 年代推动了 GPU 处理器的诞生,因此,如今由 GPU 驱动的人工智能技术渗透进视频游戏设计的几乎每个环节,可谓恰逢其时。顺应这一趋势,一家名为 Sett 的初创公司于周三宣布结束隐匿模式,获得 2700 万美元融资,该公司致力于开发用于构建和运营移动游戏的 AI Agent。

Rubrik 联合创始人 Soham Mazumdar 于 2023 年离职后,创立了一家名为 WisdomAI 的新数据初创公司。

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。