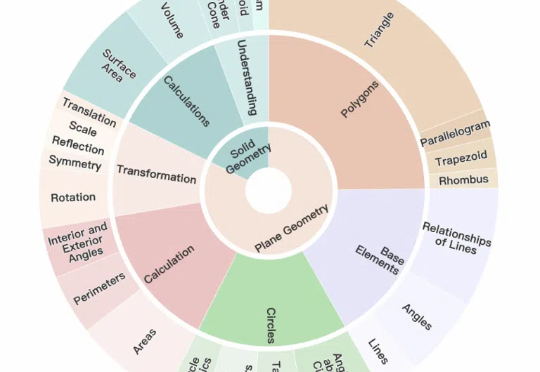
Gemini-2.0夺冠!全球首个几何推理专项评测出炉,淘天集团出品
Gemini-2.0夺冠!全球首个几何推理专项评测出炉,淘天集团出品多模态大模型几何解题哪家强?
来自主题: AI技术研报
10171 点击 2025-04-28 17:35
 搜索
搜索
多模态大模型几何解题哪家强?
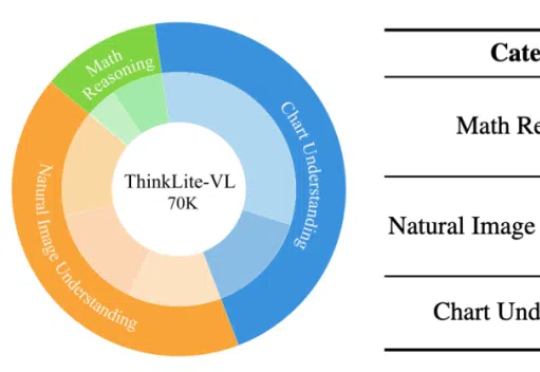
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。

最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
自主通才科学家(AGS)正成为现实!

4月25日,昆仑万维发布最新财报,2024年营收56.62亿元,同比增长15.2%,净利润亏损15.95亿元,同比下跌226.8%。这也是上市十年,昆仑万维首度亏损的一年。
科研成果「复现」新革命!还在为堆积如山的论文和难以复现的代码发愁吗?Paper2Code能直接「阅读」机器学习论文,自动生成高质量、可运行的代码库。它通过智能规划、分析、生成三步,效率远超人类,有望极大加速科研迭代,告别「重复造轮子」的烦恼!

赵充是像素绽放PixelBloom(AiPPT.com) CEO,旗下产品AiPPT.com自2023年8月上线以来,已经积累2000多万用户,是大模型趋势中表现最亮眼的AI产品之一。
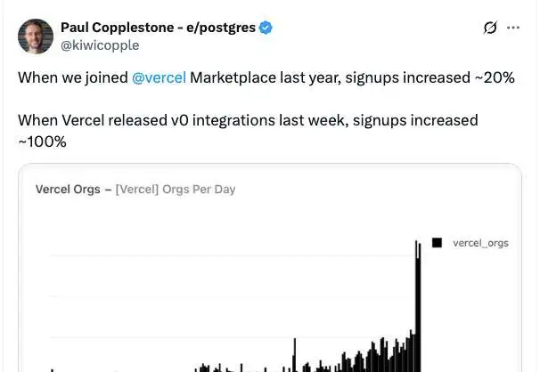
本周,Supabase 的发展已经迎来高光时刻:据《财富》杂志报道, Supabase 宣布完成 2 亿美元 D 轮融资,投后估值 20 亿美元。本轮由 Accel 领投,Coatue、Y Combinator、Craft Ventures 及老股东 Felicis 参投。距离其上一轮 8000 万美元融资仅过去 7 个月,累计融资已达近 4 亿美元。
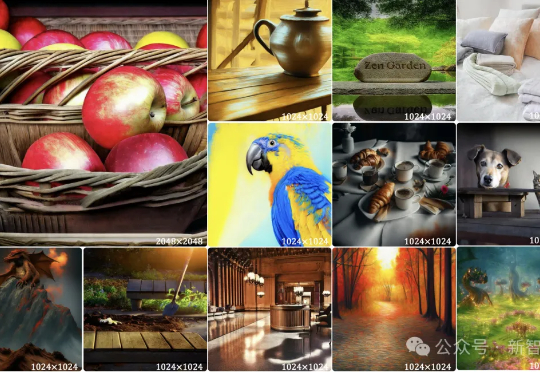
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。

近日,微软发布了2025年度《工作趋势指数》报告,该研究调查了来自31个国家和地区的3.1万名受访者,并整合了LinkedIn就业市场数据,分析了AI和数字化转型对全球工作环境和组织结构的深刻影响,并预测了一个新的概念——“前沿企业”(Frontier Firms)。这些公司利用AI助手和人类智能的融合,推动了快速发展、灵活运营和价值创造。