o3-mini数学推理暴打DeepSeek-R1?AIME 2025初赛曝数据集污染大瓜
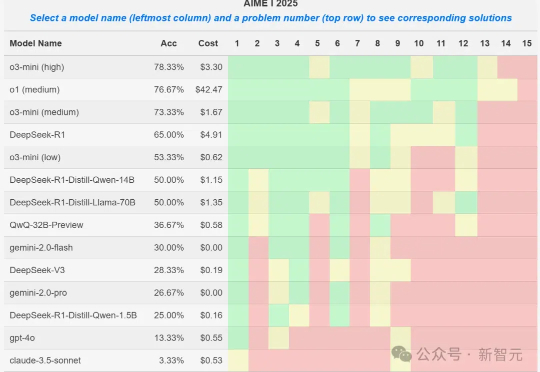
o3-mini数学推理暴打DeepSeek-R1?AIME 2025初赛曝数据集污染大瓜就在刚刚,AIME 2025 I数学竞赛的大模型参赛结果出炉,o3-mini取得78%的最好成绩,DeepSeek R1拿到了65%,取得第四名。然而一位教授却发现,某些1.5B小模型竟也能拿到50%,莫非真的存在数据集污染?
来自主题: AI资讯
10356 点击 2025-02-10 11:21
 搜索
搜索
就在刚刚,AIME 2025 I数学竞赛的大模型参赛结果出炉,o3-mini取得78%的最好成绩,DeepSeek R1拿到了65%,取得第四名。然而一位教授却发现,某些1.5B小模型竟也能拿到50%,莫非真的存在数据集污染?
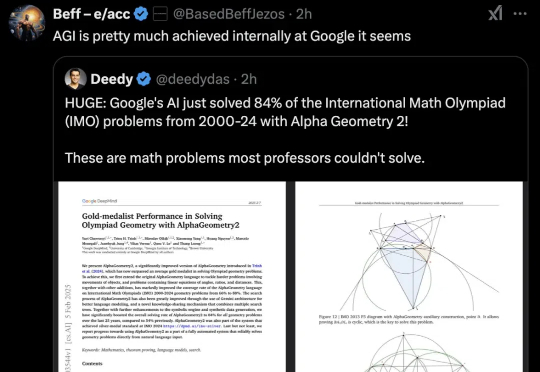
谷歌DeepMind的AI,终于拿下IMO金牌了!六个月前遗憾摘银,如今一举得金,SKEST新算法立大功。这不,它首破解了2009 IMO最难几何题,辅助作图的神来之笔解法让谷歌研究员当场震惊。

DeepSeek 的最新模型 DeepSeek-V3 和 DeepSeek-R1 都属于 MoE(混合专家)架构,并在开源世界产生了较大的影响力。特别是 2025 年 1 月开源的 DeepSeek-R1,模型性能可挑战 OpenAI 闭源的 o1 模型。
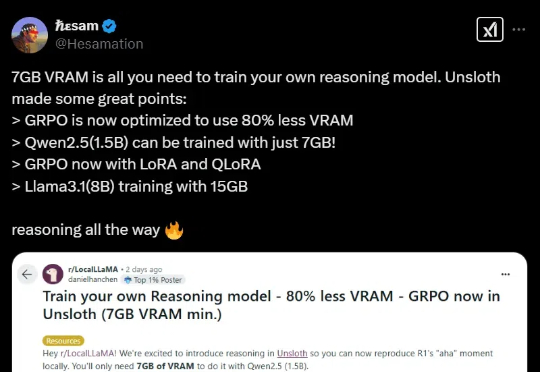
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。
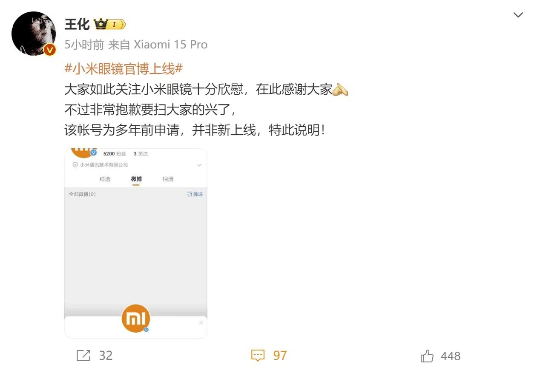
2月6日有网友发文表示,小米眼镜官微上线,预示着小米AI眼镜即将到来。随后小米公关部总经理王化辟谣,小米眼镜官微多年前就已注册,并非最近上线。

爆火的DeepSeek,足以载入史册。很多年后人们回想起这一刻,结论或许是从2022年底OpenAI发布ChaGPT,中国AI发展的主流叙事始终是“追赶”,而DeepSeek横空出世,将“追赶“变成了“创新”和“普及”,甚至是“重塑”和“超越”。
2月8日,昆仑万维旗下「天工AI」正式推出PC版重大更新——上线“DeepSeek R1 + 联网搜索”功能。这一全新升级,不仅解决了用户长期以来关注的DeepSeek联网功能无法使用的问题,还优化了R1版本偶尔崩溃的困扰,为用户带来更加稳定、高效、智能的AI体验。

语音是人工智能应用公司最重大的突破之一。作为人类最常用、信息密度最高的交流方式,语音如今在人工智能的推动下首次实现了“可编程化”。

“我肯定会投啊!我肯定会投!——这个价格已经不太重要了,关键是参与在这里面。”1年前,2024年初,在我们关于《朱啸虎讲了一个中国现实主义AIGC故事》的报道中,朱啸虎的观点淋漓尽致地展现了一个现实版中国AI故事。他用“我们一看就知道,这个肯定没戏”,“我们一开始就说了,我就不看好大模型”,“ 我都不愿意去聊,你知道吗?这没有意义”,表态绝不会投资6家中国大模型创业公司中的任何一家。

Ilya Sutskever,带着新消息又出现了——创办的公司SSI(Safe SuperIntelligence),正在进行新一轮融资洽谈。目标:估值至少200亿美元。