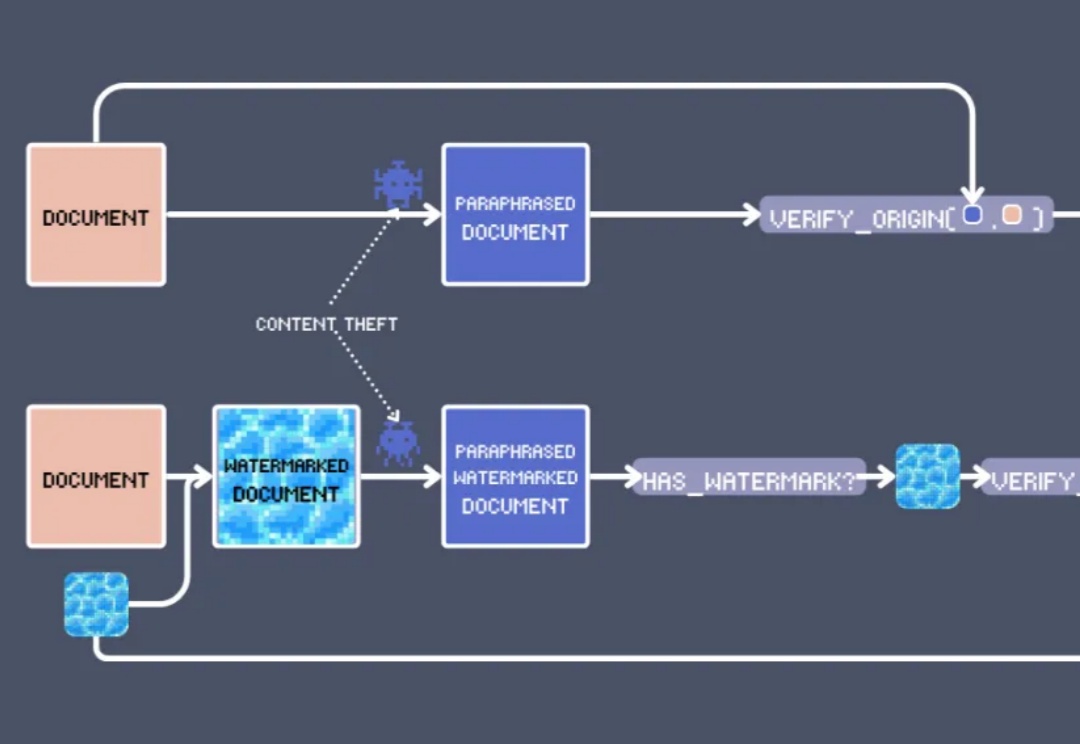
基于向量模型的文本水印技术
基于向量模型的文本水印技术在 EMNLP 2024 上,我们看到了向量模型的各种创新用法,其中最出人意料的莫过于:文本水印。
来自主题: AI技术研报
9702 点击 2024-11-28 09:17
 搜索
搜索
在 EMNLP 2024 上,我们看到了向量模型的各种创新用法,其中最出人意料的莫过于:文本水印。

就在刚刚,CNBC 和路透社等多家媒体报道称,OpenAI 获得了软银 15 亿美元新投资,并且还允许员工通过要约收购(tender offer)出售股权。其中一位知情人士表示,OpenAI 员工需要在 12 月 24 日之前决定是否参与这次的新要约收购。

Meta最近开源了多个AI项目,包括图像分割模型SAM 2.1、多模态语言模型Spirit LM、自学评估器和改进的跨语言句子编码器Mexma等,提升了AI在图像处理和语音识别领域的能力,进一步推动了AI研究的进展。

2024 年,他在 AI 领域果断出手,连开四枪,投资 Gyges Labs、Aha Lab、筷子科技、星海图四个项目,看似激进,实则蕴含着对 AI 行业深刻洞察与精准判断下的独特投资逻辑。今天兵哥就带着给大家将一些逻辑做一些拆解,深度解析这些项目的价值以及背后的投资逻辑,同时从朱啸虎的投资来洞察 AI 行业的项目发展机会。
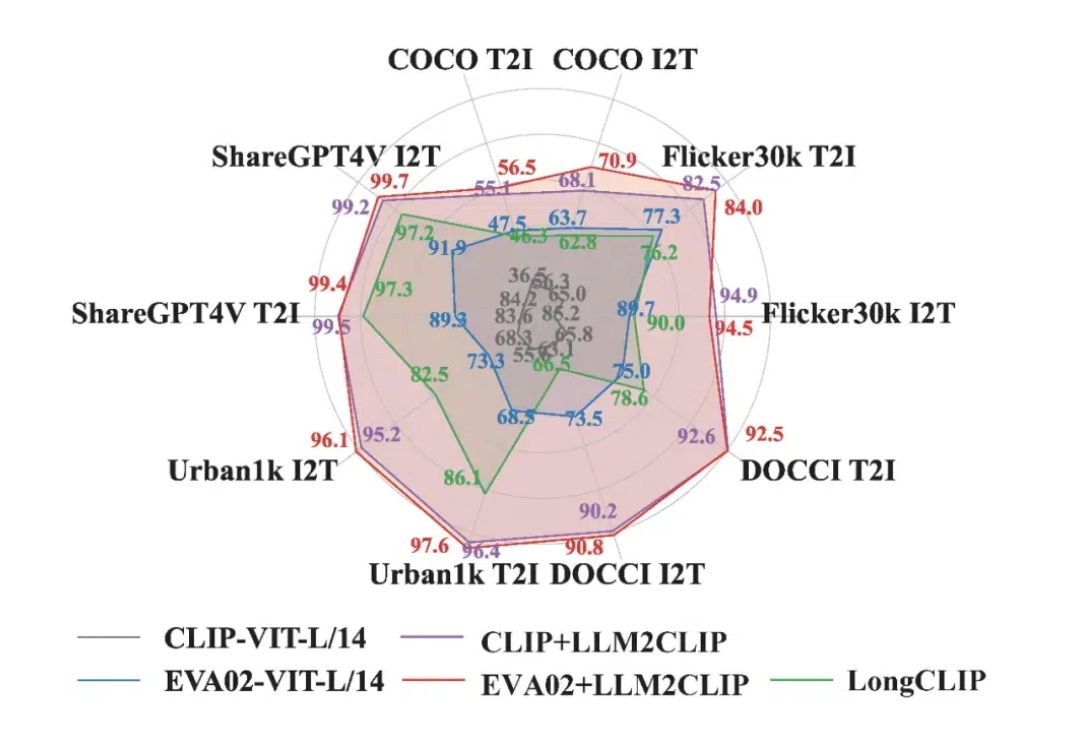
在当今多模态领域,CLIP 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。CLIP 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中,受到了广泛应用。
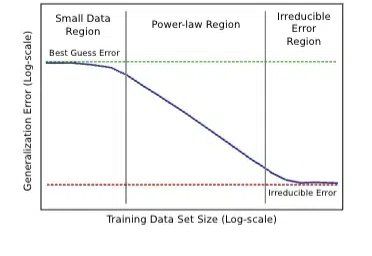
什么?Scaling Law最早是百度2017年提的?! Meta研究员翻出经典论文: 大多数人可能不知道,Scaling law原始研究来自2017年的百度,而非三年后(2020年)的OpenAI。

获评2024年度模型风险管理产品。
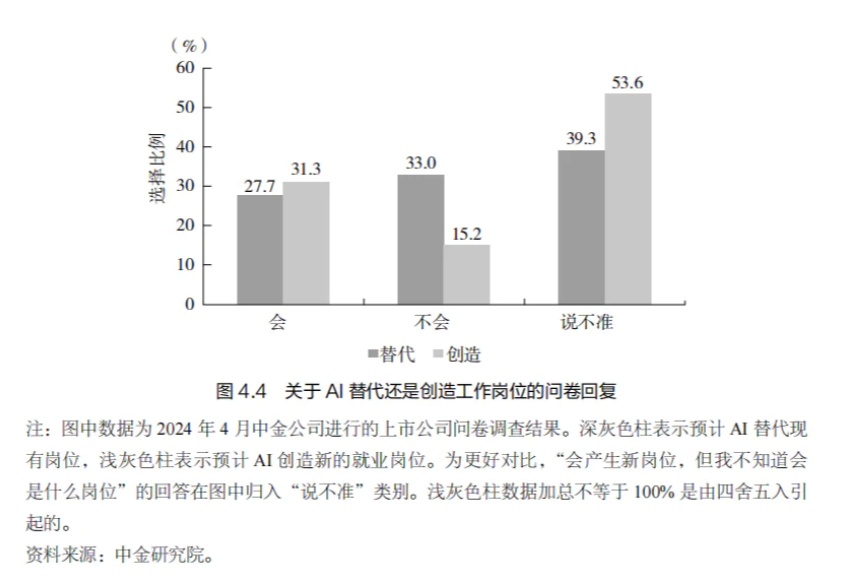
2022 年,以ChatGPT 大语言模型(LLM)的发布为标志, AI 神经网络的类人学习能力取得了里程碑式的进展,在全球范围内掀起了一股 AI 热潮。

OpenAI Sora突遭泄露,似乎比2月的演示版又进化了!

据国外网站分析工具Similarweb显示,在同期AI视频产品中,可灵流量增长十分迅速。截至9月24日,可灵的总访问量达到了3370万,高于早已发布产品的Runway(3134万)和Pika(752万)。