
专访27岁亿万富翁Alexandr Wang: Scale AI如何仅仅为AI行业提供数据标注服务,做到年化收入接近10亿
专访27岁亿万富翁Alexandr Wang: Scale AI如何仅仅为AI行业提供数据标注服务,做到年化收入接近10亿Scale AI早早踩对了风口,如今终于一飞冲天了,公司的2024年年化收入预计达到近10亿美元。
来自主题: AI资讯
9417 点击 2024-09-26 14:52
 搜索
搜索
Scale AI早早踩对了风口,如今终于一飞冲天了,公司的2024年年化收入预计达到近10亿美元。

Meta Connect 2024推出Quest 3S、Llama 3.2与AR眼镜Orion。
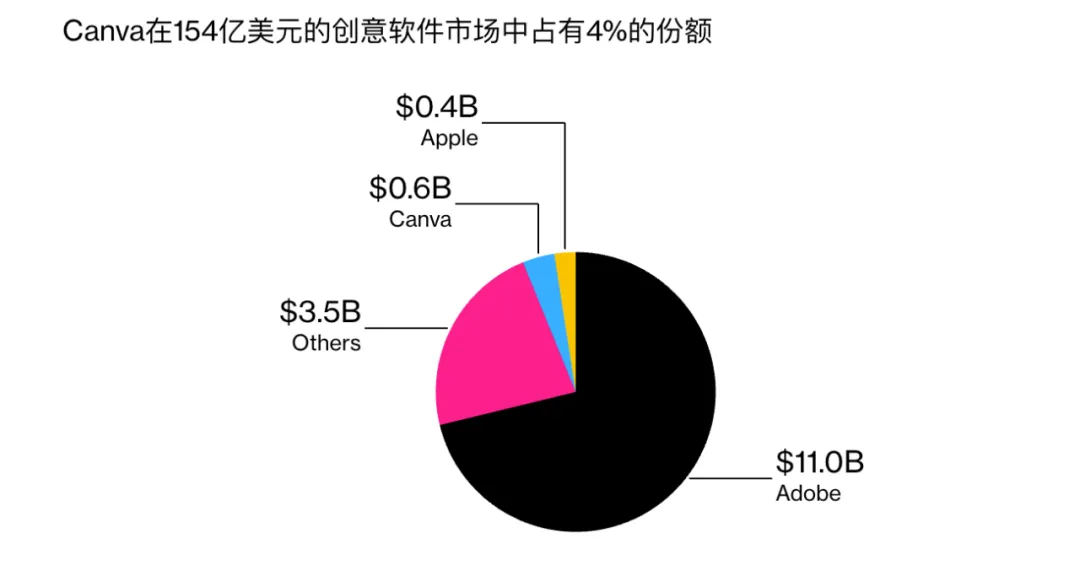
为了让设计更友好而创立的公司 Canva,今年的估值是 260 亿美元,这可能是目前全球最有价值的由女性领导的初创公司。

自适应系统在动态和不确定的环境中具有关键作用,广泛应用于自动驾驶、智能制造、网络安全和智能医疗等领域。
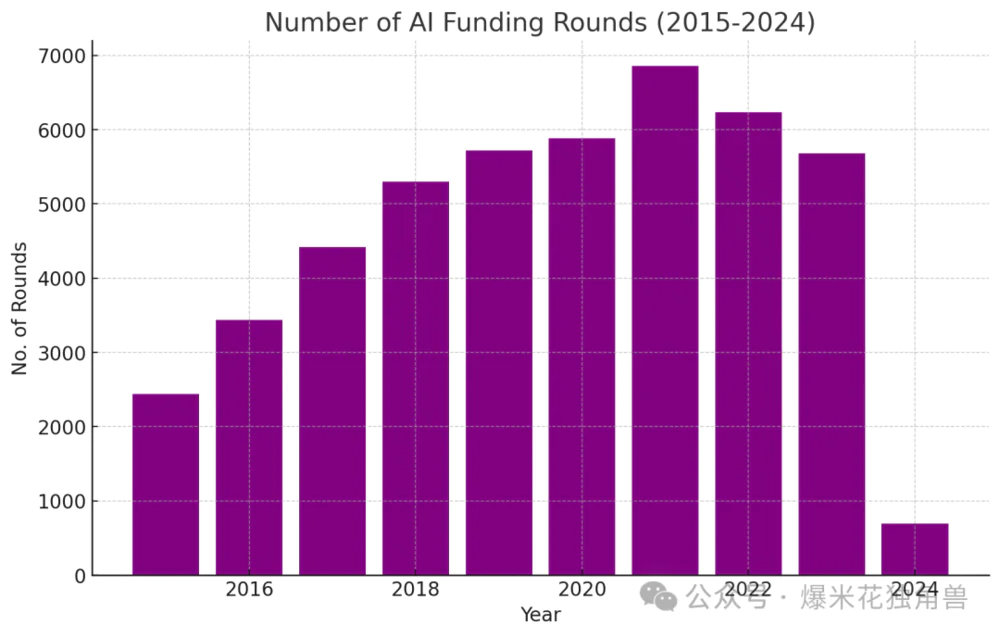
在《AI算法分析94家海外AI独角兽》提到,我们分析了2015年后成立的6500家AI公司(从2万多家公司中抽取完成融资和2022年以后创办的企业),本篇是关于VC的一篇分析报告。 我们提供了投到最多独角兽的机构列表(文末),以及对YC的业绩回报做了估算。

“不需要再等OpenAI的鸽王Sora了”。

大模型的能力越来越强,用户在一些重要的任务中也可以依赖大模型,比如说辅助做科研。 不过现有科研辅助相关的基准测试都太简单,跟现实世界的任务差距还是比较大的。
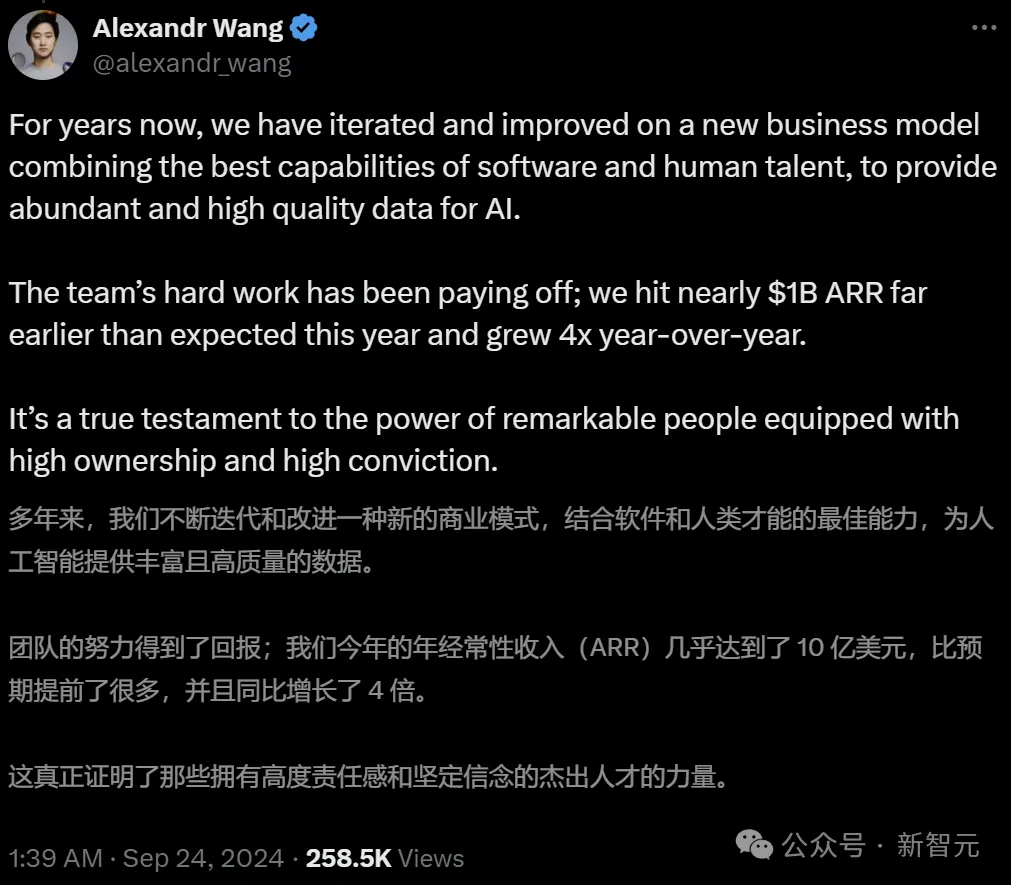
就在刚刚,创业成功的27岁亿万富翁Alexandr Wang宣布—— Scale AI的年化收入,几乎达到了10亿美元! 这个数字,足够震惊整个硅谷的。

已获谷歌云25万美元融资

9月 24 日,字节跳动的豆包大模型发布多款新品——视频生成、音乐生成以及同声传译大模型。