
OpenAI Image2 核心团队成员爆料:历时4个月,断崖反超谷歌 Nano Banana!几乎所有图像生成团队都上了!业内都在深扒Image2技术路径!
OpenAI Image2 核心团队成员爆料:历时4个月,断崖反超谷歌 Nano Banana!几乎所有图像生成团队都上了!业内都在深扒Image2技术路径!“这是我过去四个月一直在研究的东西!”
来自主题: AI资讯
10167 点击 2026-04-23 14:47
 搜索
搜索
“这是我过去四个月一直在研究的东西!”
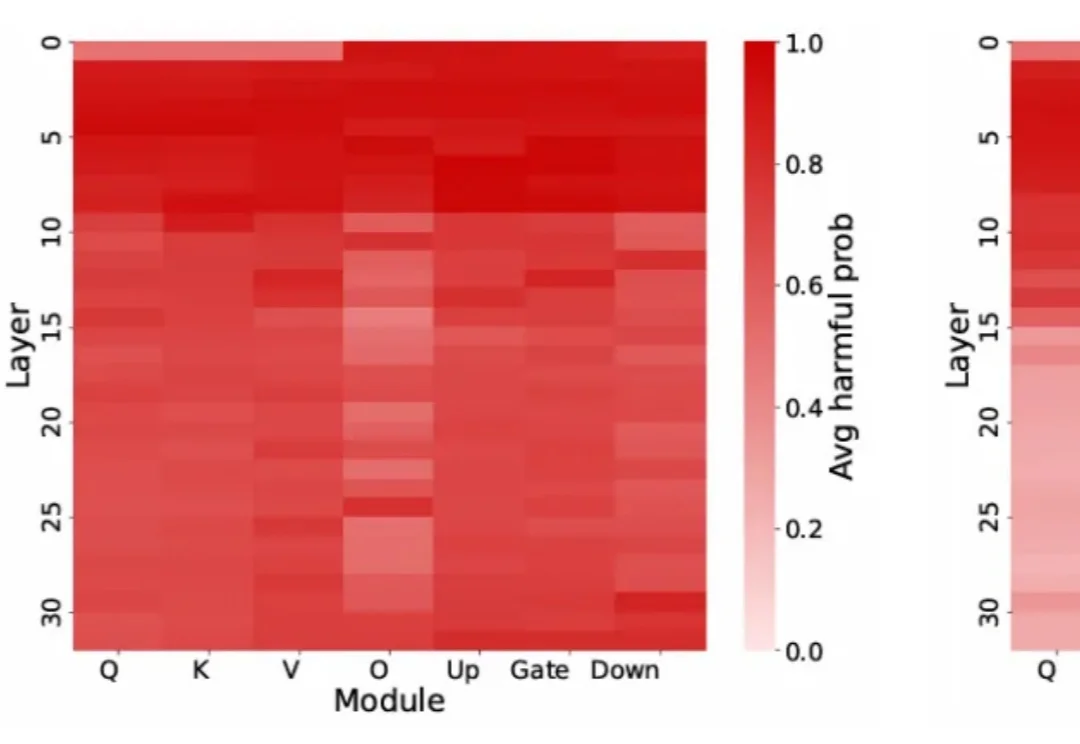
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。

对 AI 数据中心持续不断的需求正在蔓延到为冷却芯片服务器等关键任务提供组件的鲜为人知的公司。

2026年出海:靠“陪聊AI”活着的公司都在死去,这几家企业凭什么翻倍暴涨?
作者|周一笑 邮箱|zhouyixiao@pingwest.com 2026 年 3 月 17 日,拓竹科技把 Meshy 6 接进了 MakerWorld 的 MakerLab。一张照片上传上去,两
OpenAI在ChatGPT里正式上线workspace agents,由Codex驱动,云端7×24运行,能跨数十种工具执行任务。GPTs进入退休倒计时。5月6日前免费体验。

小米大模型时隔一月能力飙涨,比Kimi K2.6省42% Token。
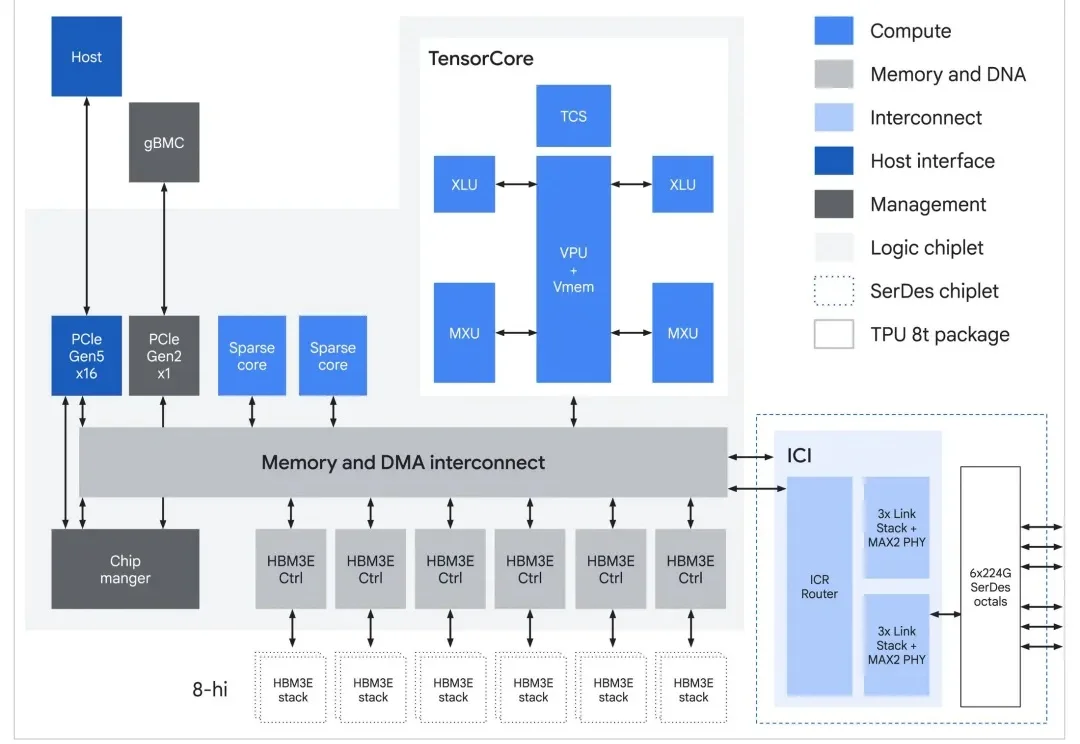
今天,谷歌在 Cloud Next '26 峰会上发布了其第八代 TPU 架构(TPU 8t 与 TPU 8i),TPU 8t 主攻训练,TPU 8i 主攻推理,将在 2026 年晚些时候上市。第八代 TPU 采用申请制,Google Cloud 用户如需使用,需要在官网提交登记需求。

估值飙至200亿美元。

GPT Image2全网刷屏,但效果究竟为什么这么好?