RAG 高效应用指南 02:Embedding 模型的选择和微调
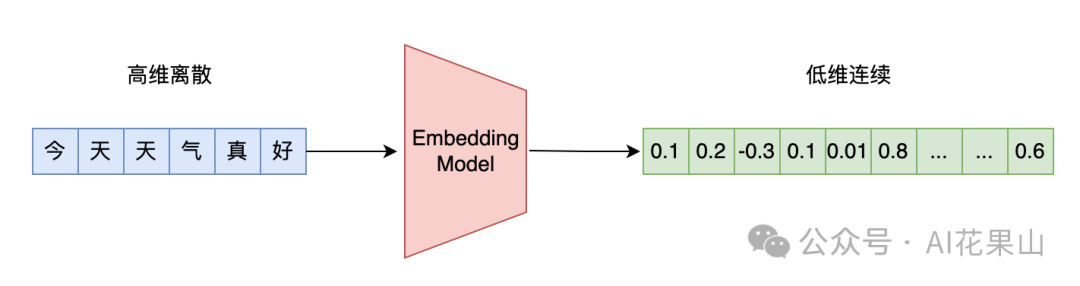
RAG 高效应用指南 02:Embedding 模型的选择和微调在本篇文章中,笔者将讨论以下几个问题: • 向量模型在 RAG 系统中的作用 有哪些性能不错的向量模型(从 RAG 角度) 不同向量模型的评测基准 MTEB 业务中选择向量模型有哪些考量 如何 Finetune 向量模型
来自主题: AI技术研报
14313 点击 2024-08-03 10:44
 搜索
搜索
在本篇文章中,笔者将讨论以下几个问题: • 向量模型在 RAG 系统中的作用 有哪些性能不错的向量模型(从 RAG 角度) 不同向量模型的评测基准 MTEB 业务中选择向量模型有哪些考量 如何 Finetune 向量模型

只是一种补充,并非要替代人类朋友。

谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。
7月26日,《北京市推动“人工智能+”行动计划(2024—2025年)》(以下简称《行动计划》)正式对外发布。

7月25日,非凡产研举办的《金融科技新动力:AI在金融创新与服务中的应用》主题活动在上海圆满落幕。 活动特别邀请到了三位AI+金融领域的资深专家深擎科技创始人&CEO 柴志伟、澜码科技创始人兼CEO 周健、甜新科技合伙人 郭尔东分别进行了专题分享,跟参会嘉宾进行了答疑互动。
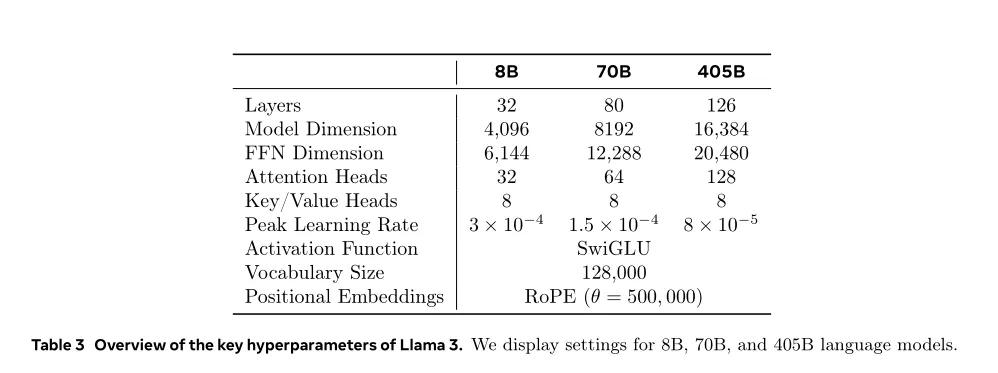
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

家处某二线城市的明明,在当地一所普通高校就读,还有一年就要大学毕业的他,害怕毕业后不好找工作,最近花了2万多元在当地培训机构报名了“AI训练师”的课程。 AI训练师指“使用智能训练软件,在人工智能产品实际使用过程中进行数据库管理、算法参数设置、人机交互设计、性能测试跟踪及其他辅助作业的人员”,可以简单理解为,所有与AI训练相关的职业,这一职业,在2020年被纳入国家职业分类目录。
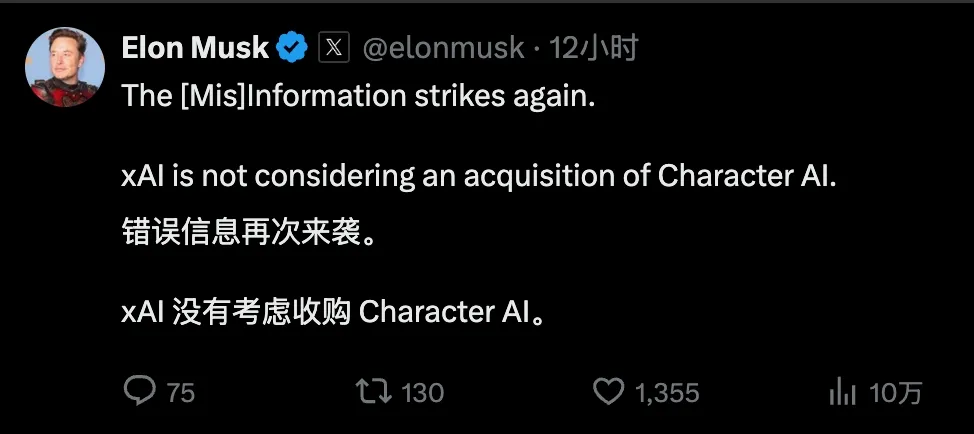
马斯克的 xAI 可能会买下 Character AI(信息来源权威爆料媒体 The Information,马斯克随后否认),前者估值 240 亿美元,刚完成 60 亿美元的 B 轮融资,全球仅次于 OpenAI 的超级 AI 独角兽。

99美元(约710人民币),就能和AI“交个朋友”?

今年 6 月底,谷歌开源了 9B、27B 版 Gemma 2 模型系列,并且自亮相以来,27B 版本迅速成为了大模型竞技场 LMSYS Chatbot Arena 中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。