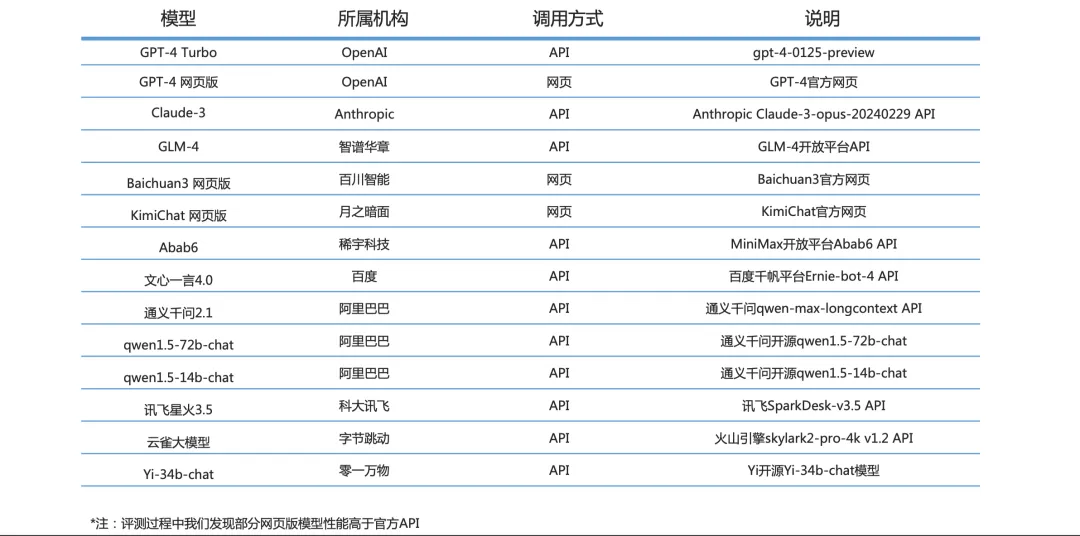
国内百模谁第一?清华14大LLM最新评测报告出炉,GLM-4、文心4.0站在第一梯队
国内百模谁第一?清华14大LLM最新评测报告出炉,GLM-4、文心4.0站在第一梯队在2023年的「百模大战」中,众多实践者推出了各类模型,这些模型有的是原创的,有的是针对开源模型进行微调的;有些是通用的,有些则是行业特定的。如何能合理地评价这些模型的能力,成为关键问题
来自主题: AI资讯
7926 点击 2024-04-19 21:21
 搜索
搜索
在2023年的「百模大战」中,众多实践者推出了各类模型,这些模型有的是原创的,有的是针对开源模型进行微调的;有些是通用的,有些则是行业特定的。如何能合理地评价这些模型的能力,成为关键问题

据国外媒体报道,早在2021年,微软便率先推出了Copilot编程助手预览版,引起了广大软件开发者的热烈反响。他们非常看好这款助手的巨大潜力,并对其充满期待。

日前,360周鸿祎在第二十七届哈佛中国论坛炮轰百度李彦宏“开源不如闭源”的言论,称其胡说八道。有网友评论:当年的那个老周仿佛回来了

自 ChatGPT 问世以来,OpenAI 一直被认为是全球生成式大模型的领导者。2023 年 3 月,OpenAI 官方宣布,开发者可以通过 API 将 ChatGPT 和 Whisper 模型集成到他们的应用程序和产品中。在 GPT-4 发布的同时 OpenAI 也开放了其 API。
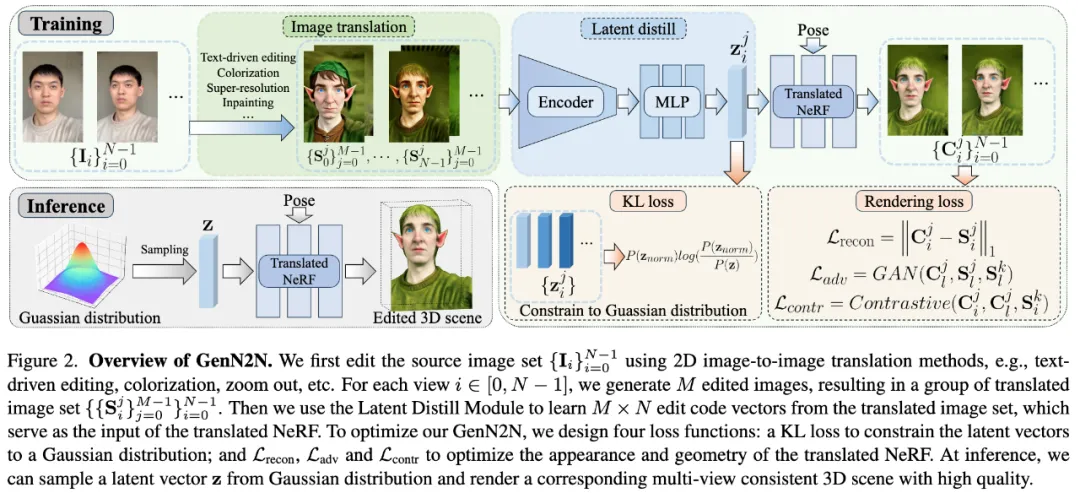
来自香港科技大学,清华大学的研究者提出了「GenN2N」,一个统一的生成式 NeRF-to-NeRF 转换框架,适用于各种 NeRF 转换任务,例如文字驱动的 NeRF 编辑、着色、超分辨率、修复等,性能均表现极其出色!

大模型发展至今,还能带给开发者哪些惊喜呢? 在 4 月 16 日举办的 2024 百度 Create AI 开发者大会上,百度智能云扔下一颗「重磅炸弹」,重新定义了计算机的核心系统软件 —— 操作系统。
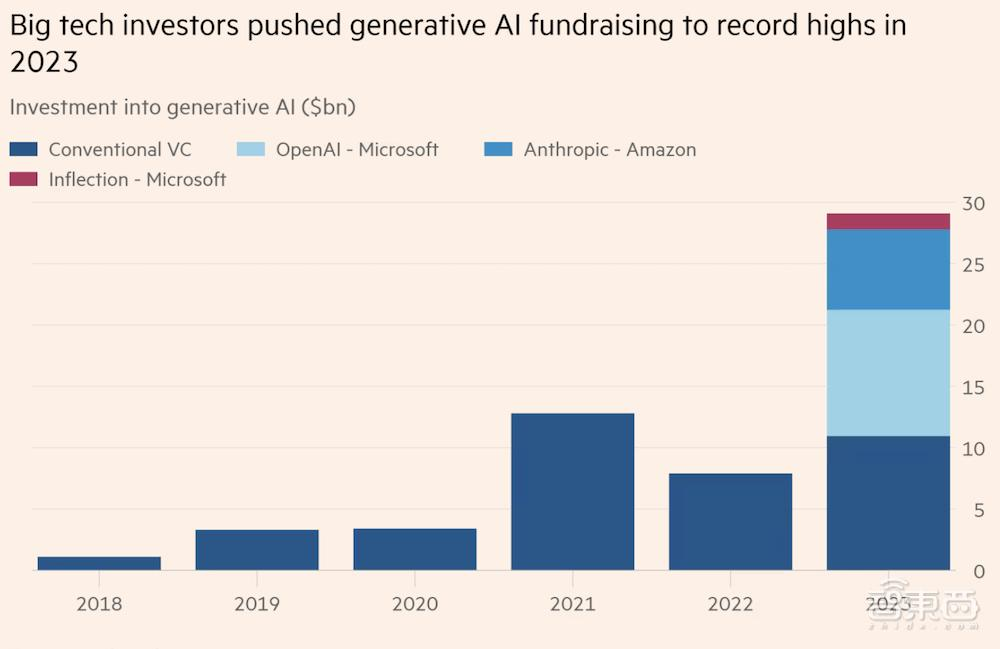
智东西4月17日消息,据《金融时报》4月16日报道,微软于4月16日宣布同意向阿布扎比AI集团G42进行15亿美元的投资。
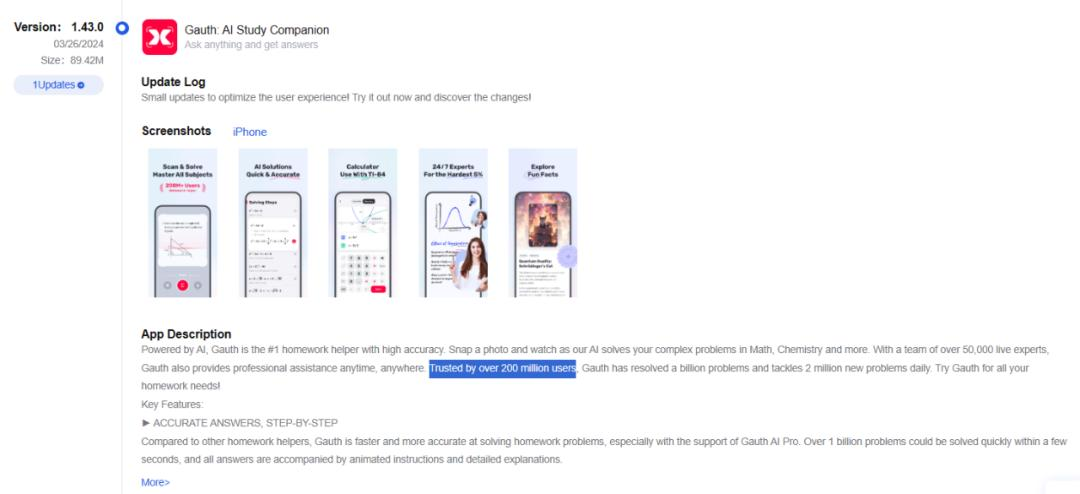
最近一段时间,“字节的 Gauth 增长很猛”的消息,四处流传。在上周写完《作业帮出海,拿下200万MAU》的选题之后,我们怀着好奇心,看看字节的 Gauth 是不是真的如一些自媒体吹得那么神,毕竟作业帮的 Question.AI 体验下来,还是有一些 bug 的。
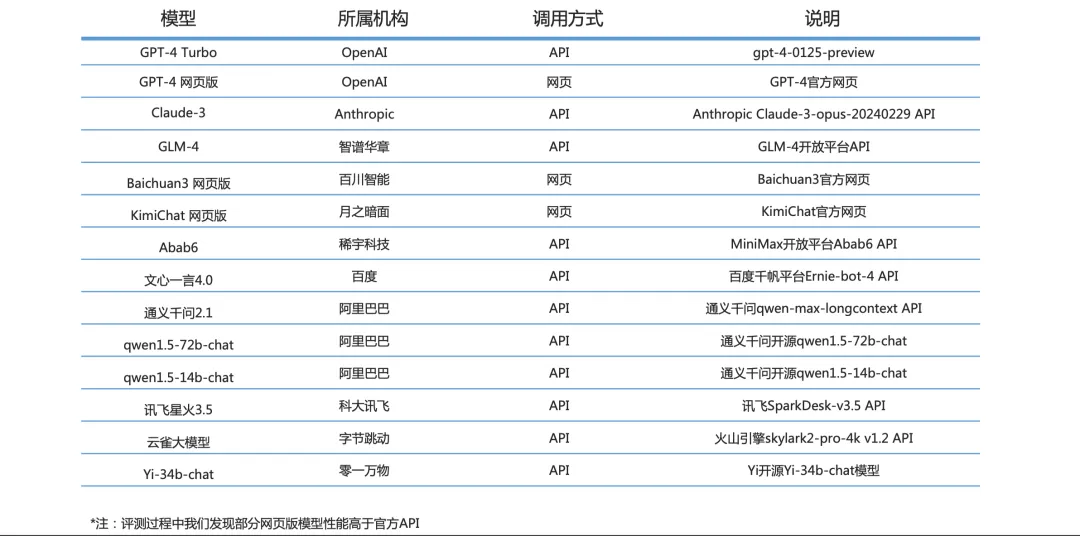
在 2023 年的 “百模大战” 中,众多实践者推出了各类模型,这些模型有的是原创的,有的是针对开源模型进行微调的;有些是通用的,有些则是行业特定的。如何能合理地评价这些模型的能力,成为关键问题。
2024 年谷歌研究学者计划(Research Scholar Program)获奖名单公布了。获奖者最高将获得 6 万美元奖金,用于支持研究工作。