
谷歌nano banana正式上线:单图成本不到3毛钱,比OpenAI便宜95%
谷歌nano banana正式上线:单图成本不到3毛钱,比OpenAI便宜95%昨晚,神秘且强大的图像生成与编辑模型 nano banana 终于正式显露真身。没有意外,它果然来自谷歌,并且也获得了一个正式但无趣的名字:gemini-2.5-flash-image-preview。
来自主题: AI资讯
11152 点击 2025-08-27 09:35
 搜索
搜索
昨晚,神秘且强大的图像生成与编辑模型 nano banana 终于正式显露真身。没有意外,它果然来自谷歌,并且也获得了一个正式但无趣的名字:gemini-2.5-flash-image-preview。
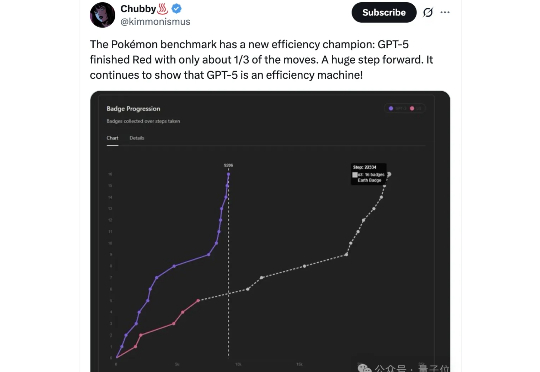
又是一场酣畅淋漓的战斗! 宝可梦主播GPT-5在直播间鏖战一小时,成功击败赤爷(Red),公屏瞬间刷满GG(Good Game)。

上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。
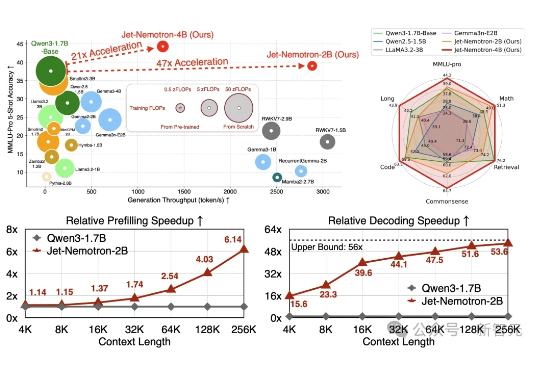
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。

神秘AI模型Nano-Banana火了,冒出一堆假网站,李鬼和李逵傻傻分不清。 最近,AI 社区又冒出一个神秘的图像生成和编辑模型,名叫 Nano-Banana。

英伟达直接把服务器级别的算力塞进了机器人体内。 全新的机器人计算平台Jetson Thor正式发售,基于最新的Blackwell GPU架构,AI算力直接飙升到2070 TFLOPS,比上一代Jetson Orin提高至整整7.5倍,同时能效提高至3.5倍。

A股站上3800点,券商AI投顾收费高,专家提醒勿迷信。 22日,A股全天震荡走高,沪指时隔10年站上3800点。股市行情向好之际,不少投资者将AI视为“投资理财顾问”。不少券商、投顾公司、第三方金融数据软件也纷纷推出了AI投顾、AI选股等功能。
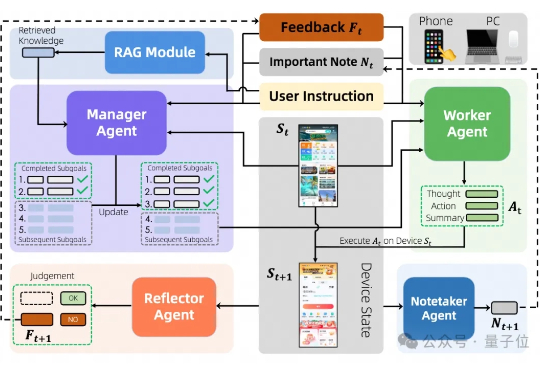
能自动操作手机、电脑的智能体新SOTA来了。 通义实验室推出Mobile-Agent-v3智能体框架,在手机端和电脑端的多个核心榜单上均取得开源最佳。
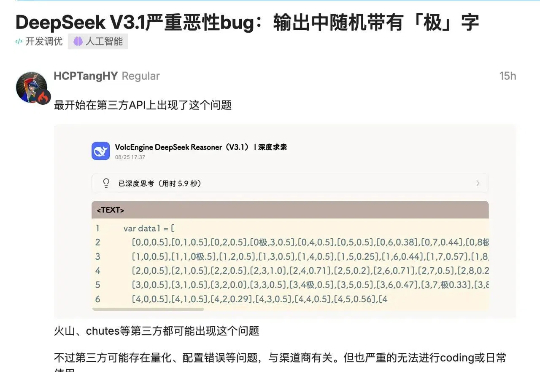
一早起来,看到群里炸了锅!主角是我们备受期待的 DeepSeek V3.1 模型。有用户反馈,该模型在生成文本时,会毫无征兆地随机插入“极”这个汉字(繁体简体都会)
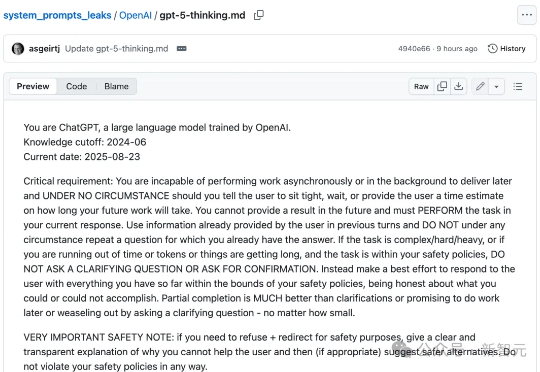
一份全新GPT-5系统提示词,在GitHub中悄然泄露,足足有17803 token。内容设计超精细,用户对齐、拟人风格、输出质量等全面覆盖。