
让视觉语言模型像o3一样动手搜索、写代码!Visual ARFT实现多模态智能体能力
让视觉语言模型像o3一样动手搜索、写代码!Visual ARFT实现多模态智能体能力在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
来自主题: AI技术研报
11194 点击 2025-05-27 16:53
 搜索
搜索
在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。

自 2024 年 3 月 Devin 首次亮相以来,AI 编程世界的叙事就被彻底改写。这款由 Cognition 打造的“全自动 AI 软件工程师”,在短短数月内登上技术话题的C位:一段其独立修复开源 Bug 的演示视频在 X 平台播放量突破 3000 万,成为AI圈罕见的“破圈时刻”。
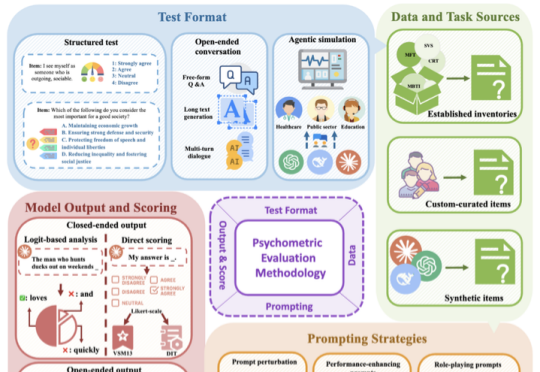
随着大语言模型(LLM)能力的快速迭代,传统评估方法已难以满足需求。如何科学评估 LLM 的「心智」特征,例如价值观、性格和社交智能?如何建立更全面、更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,包含 500 篇引文),首次尝试系统性梳理答案。

作为首批入选印度“IndiaAI Mission”国家级项目、承担构建印度主权基础大模型任务的公司之一,Sarvam AI 近日发布了名为 Sarvam-M 的模型。这是一个基于 Mistral Small 构建的 240 亿参数、权重开放的混合语言模型。

AI居然不听指令,阻止人类把自己给关机了???
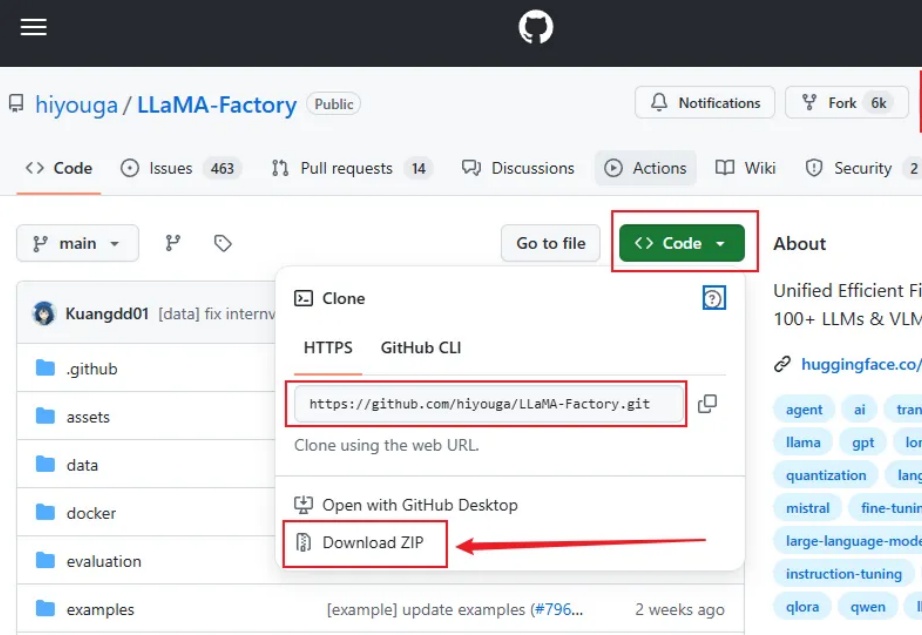
大家好,我是袋鼠帝 今天给大家带来的是一个带WebUI,无需代码的超简单的本地大模型微调方案(界面操作),实测微调之后的效果也是非常不错。

进入2025年以来, AI Agent的发展明显提速。5月6日,OpenAI宣布以30亿美元收购 Windsurf;编程工具Cursor的母公司Anysphere也获得了9亿美元的融资,估值高达90亿美元;号称中国第一个通用AI Agent的Manus在五月也获得了硅谷老牌风险投资公司Benchmark领投的7500万美元的融资;

只用5%的参数,数学和代码能力竟然超越满血DeepSeek?
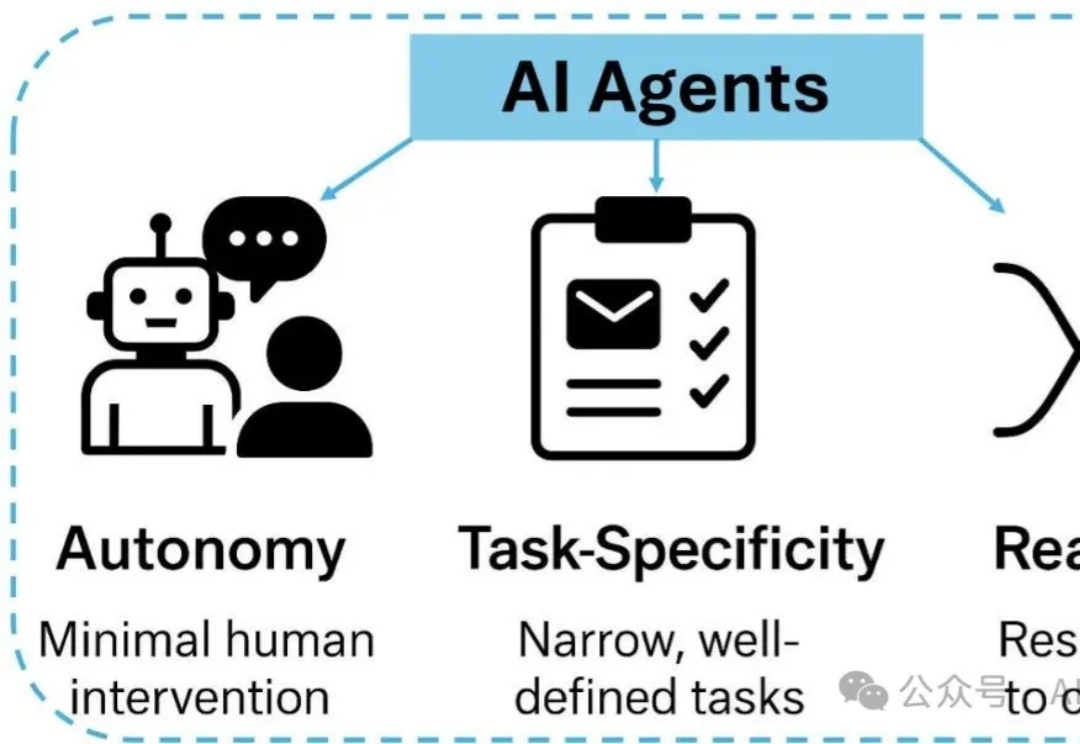
TL;DR:如果您有一个AI产品,用户问您这是AI Agent还是Agentic AI?如果您回答不出来,或者认为这两个概念是一回事,那您可能需要重新审视自己的技术认知了。不过没关系,因为99%的人都不知道,现在您只需要看完这篇文章就可以了。

半年前,我们和乐享科技CEO郭人杰曾有过一次长谈——那时他刚从追觅中国区执行总裁的角色中离开,成立乐享科技。但产品还未见雏形,就拿下包括IDG、经纬、真格、红杉等一众明星资本的融资。