
吊打苹果!一个人狂赚3000万,AI的创业姿势变了
吊打苹果!一个人狂赚3000万,AI的创业姿势变了去年,Sam Altman曾做过一个预测: 有了AI,我们很快就会看到第一家估值10亿美元,但只有一个人的AI公司。
来自主题: AI资讯
11048 点击 2025-03-05 10:07
 搜索
搜索
去年,Sam Altman曾做过一个预测: 有了AI,我们很快就会看到第一家估值10亿美元,但只有一个人的AI公司。

Anthropic 最近动作不断。

3月3日,CoreWeave提交上市招股书,申请在纳斯达克上市,股票代码为“CRWV”。据知情人士透露,CoreWeave预计通过此次上市筹集约40亿美元资金,估值目标超过350亿美元。本次交易将成为近年来AI算力领域规模最大的IPO之一。

DeepSeek R1 催化了 reasoning model 的竞争:在过去的一个月里,头部 AI labs 已经发布了三个 SOTA reasoning models:OpenAI 的 o3-mini 和deep research, xAI 的 Grok 3 和 Anthropic 的 Claude 3.7 Sonnet。
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。

刚刚,Claude背后公司Anthropic官宣新一轮融资: 35亿美元!投后估值达到615亿。 在Clauede-3.7发布后,此轮新融资便浮出水面,并在今天正式公布。
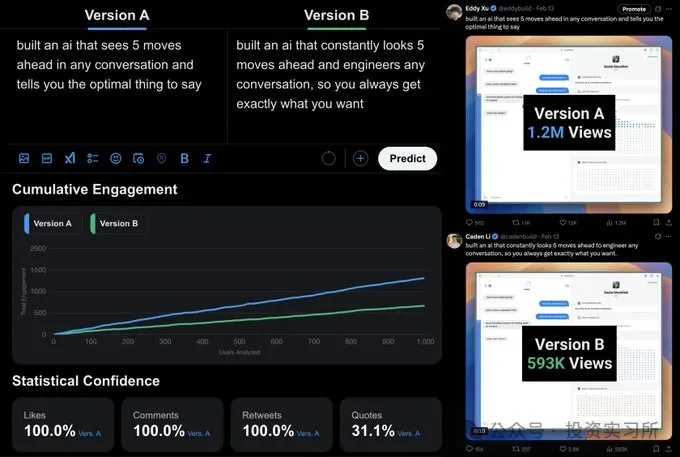
今天想介绍一个 17 岁的华裔大学生,他最近做的一个 AI Wrapper 产品,发布 5 小时收入就突破了 1 万美金,随后在发布的推文火了之后又通过线上会议 Google Meet 的售后承诺在 24 小时赚到了 3 万美金。

要知道,过去几年,各种通用评测逐渐同质化,越来越难以评估模型真实能力。GPQA、MMLU-pro、MMLU等流行基准,各家模型出街时人手一份,但局限性也开始暴露,比如覆盖范围狭窄(通常不足 50 个学科),不含长尾知识;缺乏足够挑战性和区分度,比如 GPT-4o 在 MMLU-Pro 上准确率飙到 92.3%。
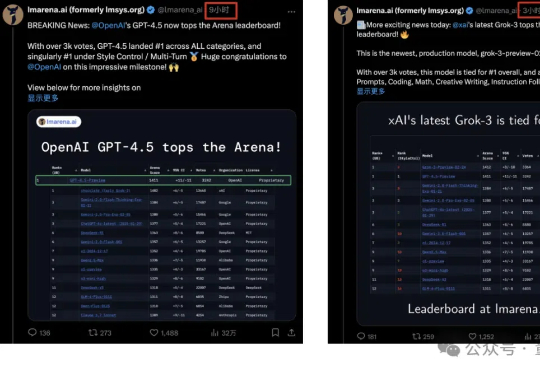
基础模型竞争又紧张刺激起来了!GPT-4.5刚登顶竞技场且全任务分类第一名,6小时后总榜就被马斯克的新版Grok-3反超。两者都是获得3000+票数,总分1412:1411只差一分。

又添新鲜血液。根据 TechCrunch 报道,由一位华人创始人 Weber Wong 开发的 AI 创意工具 Flora 于 3 月 1 日正式上线。时至今日,AI 图像与视频赛道的产品和格局已经有点固化了,能够有新鲜产品加入,还是华人创始人,确实很令人惊喜。