
刚刚,DeepSeek官方发布R1模型推荐设置,这才是正确用法
刚刚,DeepSeek官方发布R1模型推荐设置,这才是正确用法自春节以来,DeepSeek 就一直是 AI 领域最热门的关键词,甚至可能没有之一,其官方 App 成为了史上最快突破 3000 万日活的应用。最近一段时间,各家 AI 或云服务厂商更是掀起了部署 DeepSeek-R1 服务的狂潮,甚至让薅羊毛的用户们都有点忙不过来了。
来自主题: AI资讯
6147 点击 2025-02-15 12:00
 搜索
搜索
自春节以来,DeepSeek 就一直是 AI 领域最热门的关键词,甚至可能没有之一,其官方 App 成为了史上最快突破 3000 万日活的应用。最近一段时间,各家 AI 或云服务厂商更是掀起了部署 DeepSeek-R1 服务的狂潮,甚至让薅羊毛的用户们都有点忙不过来了。

Replit凭借创新的AI编程平台「Agent」,在短短半年内实现了5倍的收入增长。通过采用Claude 3.5 Sonnet模型和多智能体架构,Replit为编程行业带来了前所未有的革新,推动了一个人人皆可参与的编程时代。

中国首个全自研空间智能AI诞生了,单图即可生成360度无限3D场景,实时互动自由探索。这不仅是技术的革新,更预示着,游戏电影等领域即将迎来颠覆性的变革。

7B大小的视频理解模型中的新SOTA,来了!

没有治理的人工智能?一场等待发生的灾难。我们经常听说数据治理和人工智能是矛盾的,一个注重控制,另一个注重速度和创新。但如果我告诉你数据治理实际上是一个人工智能加速器呢?
让DeepSeek代替Claude思考,缝合怪玩法火了。原因无它:比单独使用DeepSeek R1、Claude Sonnet 3.5、OpenAI o1模型的效果更好。DeepClaude应用本身100%免费且开源,在GitHub上已揽获3k星星(当然API要用自己的)。

DeepSeek掀起的算力热潮还在持续。中国电信昨日宣布推出了息壤智算一体机-DeepSeek版,在硬件层面以华为昇腾芯片为基础,提供8卡、16卡、32卡等多种规格型号。此前,京东云也发布DeepSeek大模型一体机,支持华为昇腾、海光、寒武纪、摩尔线程、天数智芯等国产AI加速芯片。《科创板日报》了解到,华鲲振宇也推出了DeepSeek大模型一体机方案。

2025 年普遍被认为是智能体爆发元年,AI 应用将出现井喷式增长。然而,在大家纷纷将目光投向智能体的同时,另一个 AI 领域也可能迎来它的「ChatGPT 时刻」。
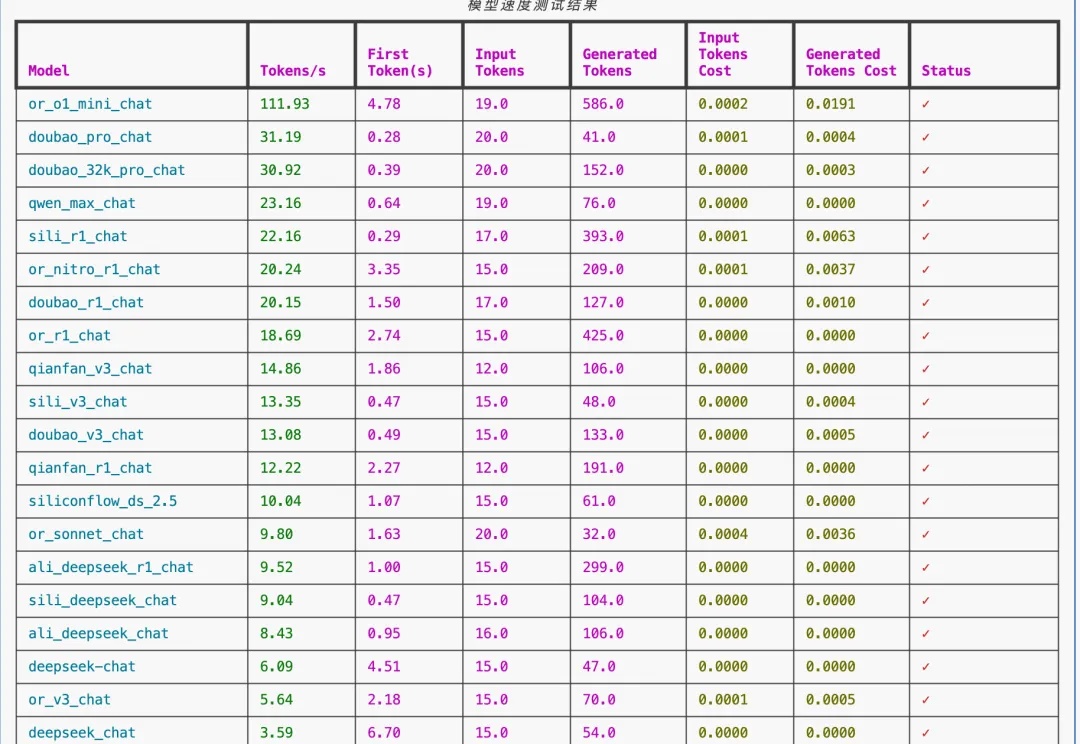
判断哪些是凑热闹的供应商

继昨天决定免费之后,百度刚刚又发布一则重磅消息——下一代文心模型,决定开源!而且官宣内容只有一句话(字少事大的感觉):我们将在未来几个月中陆续推出文心大模型4.5系列,并于6月30日起正式开源。