百度首个自研万卡集群点亮,上架DeepSeek直降3折全网最低!降低AI算力门槛
百度首个自研万卡集群点亮,上架DeepSeek直降3折全网最低!降低AI算力门槛国内首个自研万卡集群,刚刚成功点亮!国产AI的高价门槛直接被打下来了。在百度智能云平台上,DeepSeek R1和V3的官方价格直接低至五折和三折,基本实现全网最低。
来自主题: AI资讯
9352 点击 2025-02-06 15:09
 搜索
搜索
国内首个自研万卡集群,刚刚成功点亮!国产AI的高价门槛直接被打下来了。在百度智能云平台上,DeepSeek R1和V3的官方价格直接低至五折和三折,基本实现全网最低。
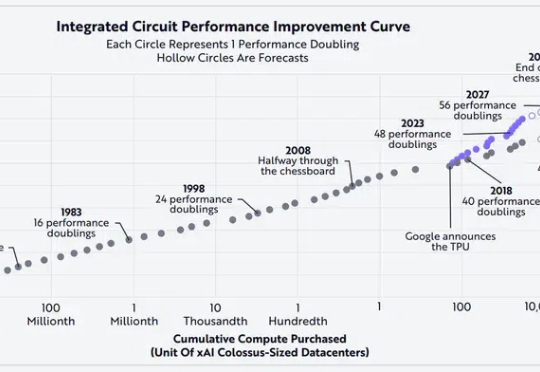
随着计算性能不断提升,技术融合趋势愈发显著,人工智能、机器人技术、储能技术、公共区块链和多组学测序这五个创新平台正重塑各个行业。在AI投资方面,木头姐明确表示她正在远离硬件和基础设施,加倍投资软件。

36氪获悉,「乐享科技」于近期完成天使轮融资本轮融资由IDG资本领投,Monolith、经纬创投、真格基金、红杉种子基金、绿洲资本跟投,融资总金额接近2亿元人民币,投后估值约为6亿元

AI发展日新月异,未来扑朔迷离。近日,Web框架Django之父Simon Willison,预测了未来1、3、6年不同阶段的AI发展以及影响。

2024年11月,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B和70B,在性能上超越了同等参数的Llama 3.1 Instruct版本,并在长达82页的论文中公布其训练细节,训练数据、代码、测试基准一应俱全。

机器人界「球星」竟被CMU英伟达搞出来了!科比后仰跳投、C罗、詹皇霸气庆祝动作皆被完美复刻。2030年,我们将会看到一场人形机器人奥运会盛宴。

就很秃然,人形机器人独角兽Figure宣布与OpenAI终止合作。创始人Brett Adcock称内部端到端机器人AI有了重大突破,将在接下来的30天展示“没人在人形机器人上见过的东西”。
北京时间2月3日上午,OpenAI突然发布了一款全新的Agent(智能体)——deep research。Deep research是一款利用推理合成大量在线信息并为用户完成多步骤研究任务的Agent,目前已整合到ChatGPT中。目前,ChatGPT Pro用户已可使用相关功能,接下来deep research也将对Plus和Team用户开放使用。

AI硬件的风吹了一年,消费电子的销量好起来了,但和AI的关系不大。经历了2023年的低谷期后,智能手机、PC都在2024年迎来了不同程度的复苏。根据Canalys数据,2024年全球智能手机出货量达到12.2亿台,同比增长了7%,结束了连续两年的下滑趋势;PC在经历了漫长的行业寒冬后,也实现了3.8%的同比增幅。
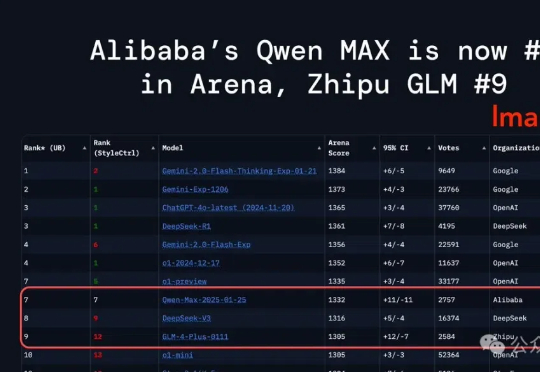
刚刚,大模型竞技场榜单上再添一款国产模型——来自阿里,Qwen2.5-Max,超越了DeepSeek-V3,以总分1332的成绩位列总榜第七。同时还一举超越Claude 3.5 Sonnet、Llama 3.1 405B等模型。