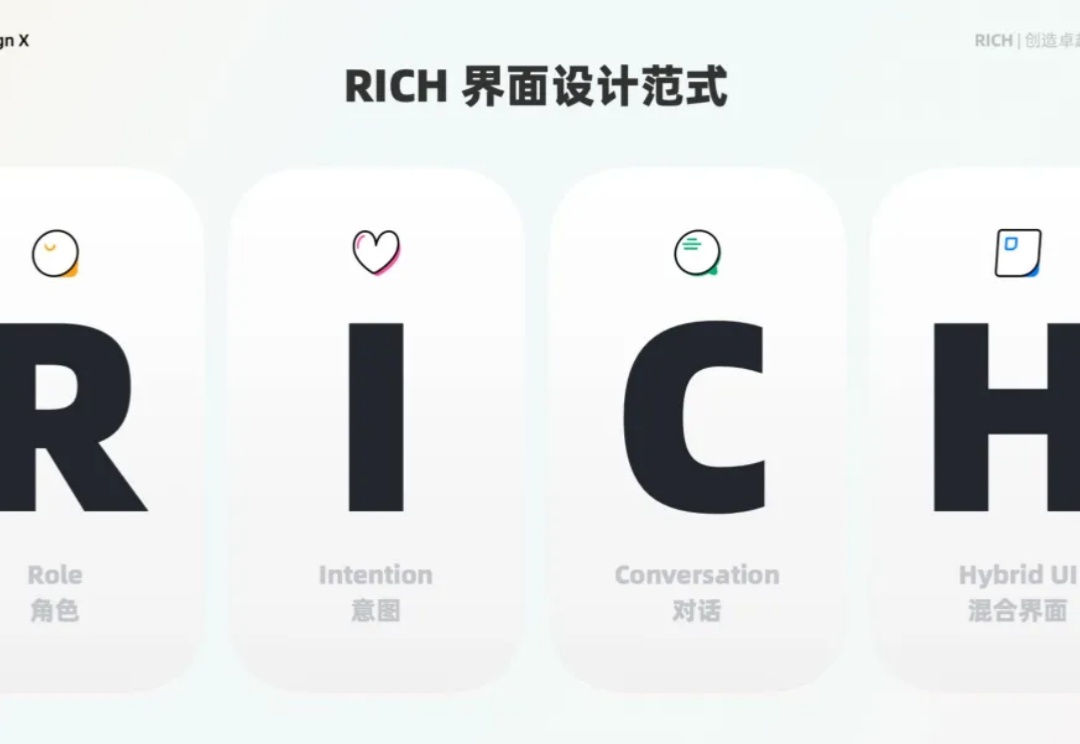
干货|Ant Design 定义 AI 界面设计新范式!
干货|Ant Design 定义 AI 界面设计新范式!2022 年 11 月,OpenAI 发布 ChatGPT 3.5,带领人类走向 AGI (Artificial General Intelligence 通用人工智能)人机交互新世纪。AGI 让自然人机交互成为现实,“语言”这一简单、自然的交互方式也影响到了 GUI(图形用户界面)。
来自主题: AI资讯
9134 点击 2024-12-11 09:24
 搜索
搜索
2022 年 11 月,OpenAI 发布 ChatGPT 3.5,带领人类走向 AGI (Artificial General Intelligence 通用人工智能)人机交互新世纪。AGI 让自然人机交互成为现实,“语言”这一简单、自然的交互方式也影响到了 GUI(图形用户界面)。

2023年10月的某一天,在OpenAI的实验室里,一个被称为Q*的模型展现出了某种前所未有的能力。

上周,李飞飞空间智能首个3D生成模型刚刚交卷。这边,国内来自智源的See3D模型,在学习了无标注的1600万个视频之后,重建出全新的3D世界,效果令人惊叹。

Stability AI 可能会成为 AI 领域又一个很有意思的案例,4 月份前 CEO 因被投资人指责在领导力和财务方面混乱而辞职,导致整个公司处于破产收购边缘。
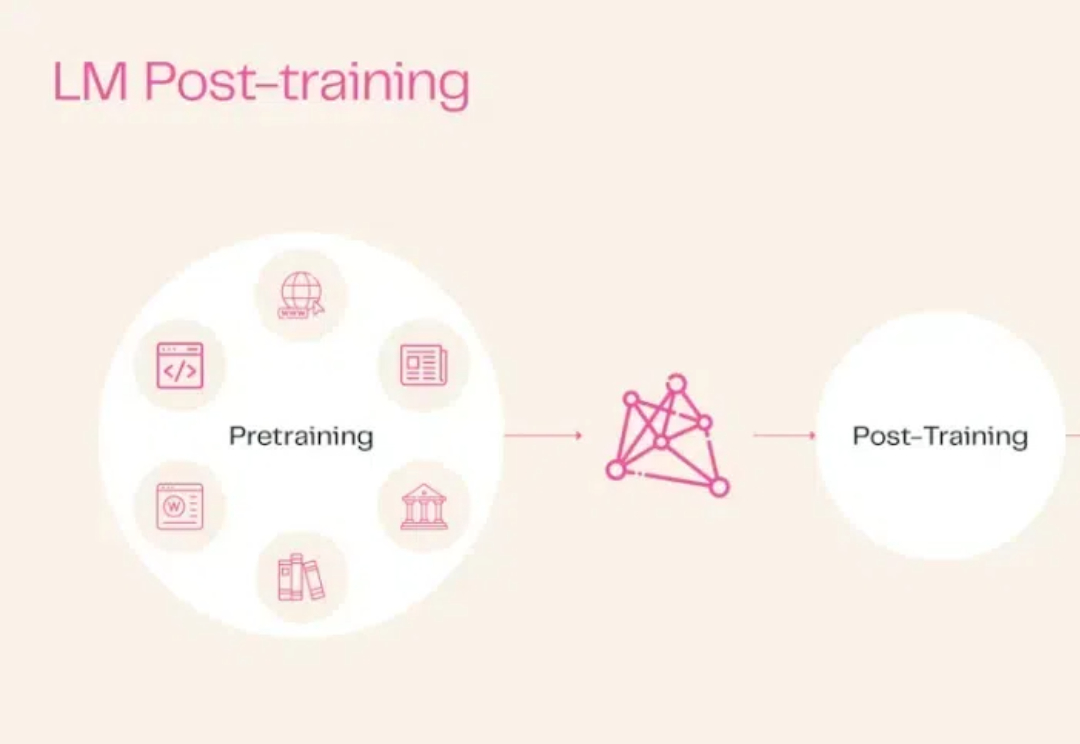
Allen Institute for AI(AI2)发布了Tülu 3系列模型,一套开源的最先进的语言模型,性能与GPT-4o-mini等闭源模型相媲美。Tülu 3包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。
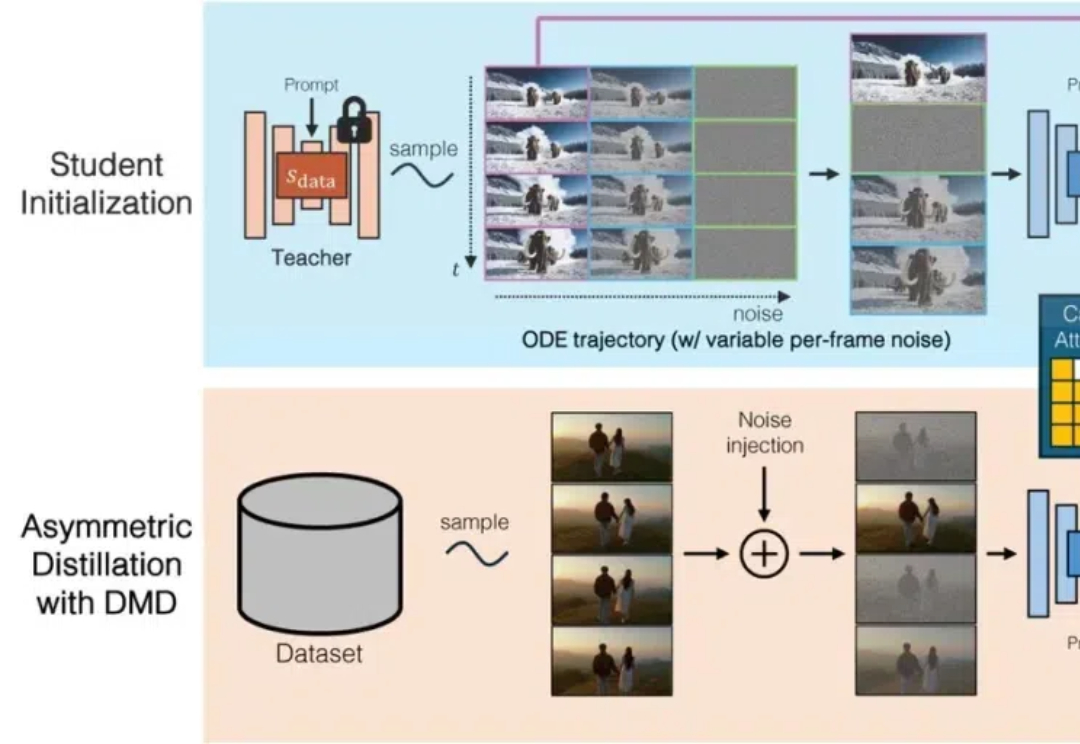
AI生成视频,边生成边实时播放,再不用等了! Adobe与MIT联手推出自回归实时视频生成技术——CausVid。

研究人员提出首个可以渲染高动态范围(High Dynamic Range, HDR)自然光的3DGaussian Splatting模型HDR-GS,以用于新视角合成(Novel View Synthesis, NVS)。

纠错功能表明,量子计算机的规模越大,其准确性就越高。
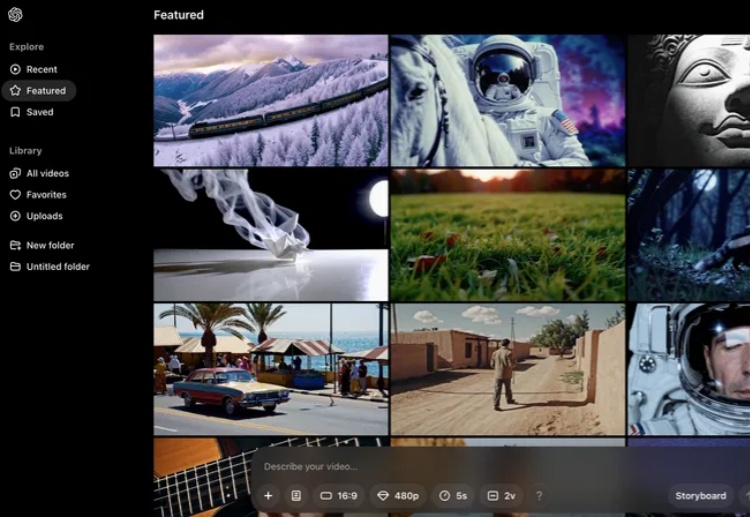
OpenAI发布会直播第3天,继第1天完全版o1和200美元月费ChatGPT Pro会员,以及第2天的强化微调工具后,OpenAI终于填上9个月前的期货大坑,正式发布了观众敲碗已久的全新视频生成模型——Sora Turbo。

台积电与英伟达,是当下 AI 浪潮中的双子星。 岁末,台积电创始人张忠谋出版了他最新的自传(1964 年——2018 年),距离他出版自己前半生的自传,已经过去了 23 年。