
欧洲区AI独角兽,估值升至212亿
欧洲区AI独角兽,估值升至212亿AI全球竞赛还在继续。在国内,最火的AI独角兽的光环属于212亿元估值的月之暗面、超177亿元估值的MiniMax,以及超100亿元的智谱AI等,而海外吸引眼球的非美国的OpenAI莫属,最新消息是,OpenAI正在以1500亿美元(10635亿元)的巨额估值融资65亿美元。这一数字令人叹为观止。
来自主题: AI资讯
6292 点击 2024-09-18 11:02
 搜索
搜索
AI全球竞赛还在继续。在国内,最火的AI独角兽的光环属于212亿元估值的月之暗面、超177亿元估值的MiniMax,以及超100亿元的智谱AI等,而海外吸引眼球的非美国的OpenAI莫属,最新消息是,OpenAI正在以1500亿美元(10635亿元)的巨额估值融资65亿美元。这一数字令人叹为观止。

前些天,OpenAI 发布了 ο1 系列模型,它那「超越博士水平的」强大推理性能预示着其必将在人们的生产生活中大有作为。但它的使用成本也很高,以至于 OpenAI 不得不限制每位用户的使用量:每位用户每周仅能给 o1-preview 发送 30 条消息,给 o1-mini 发送 50 条消息。
北京时间 9 月 13 日午夜,OpenAI 发布了推理性能强大的 ο1 系列模型。之后,各路研究者一直在尝试挖掘 ο1 卓越性能背后的技术并尝试复现它。当然,OpenAI 也想了一些方法来抑制窥探,比如有多名用户声称曾试图诱导 ο1 模型公布其思维过程,然后收到了 OpenAI 的封号威胁。

一家刚成立6个月的初创公司Chai Discovery最近发布了能对打甚至超越AlphaFold 3的模型Chai-1,而且放出了模型权重和推理代码。不开源的DeepMind这回还能坐得住吗?

近日,成立仅 6 个月的 AI 生物技术初创公司 Chai Discovery,发布用于分子结构预测的新型多模态基础模型 Chai-1,并附带了一份技术报告,比较了 Chai-1 与 AlphaFold 等模型的性能。
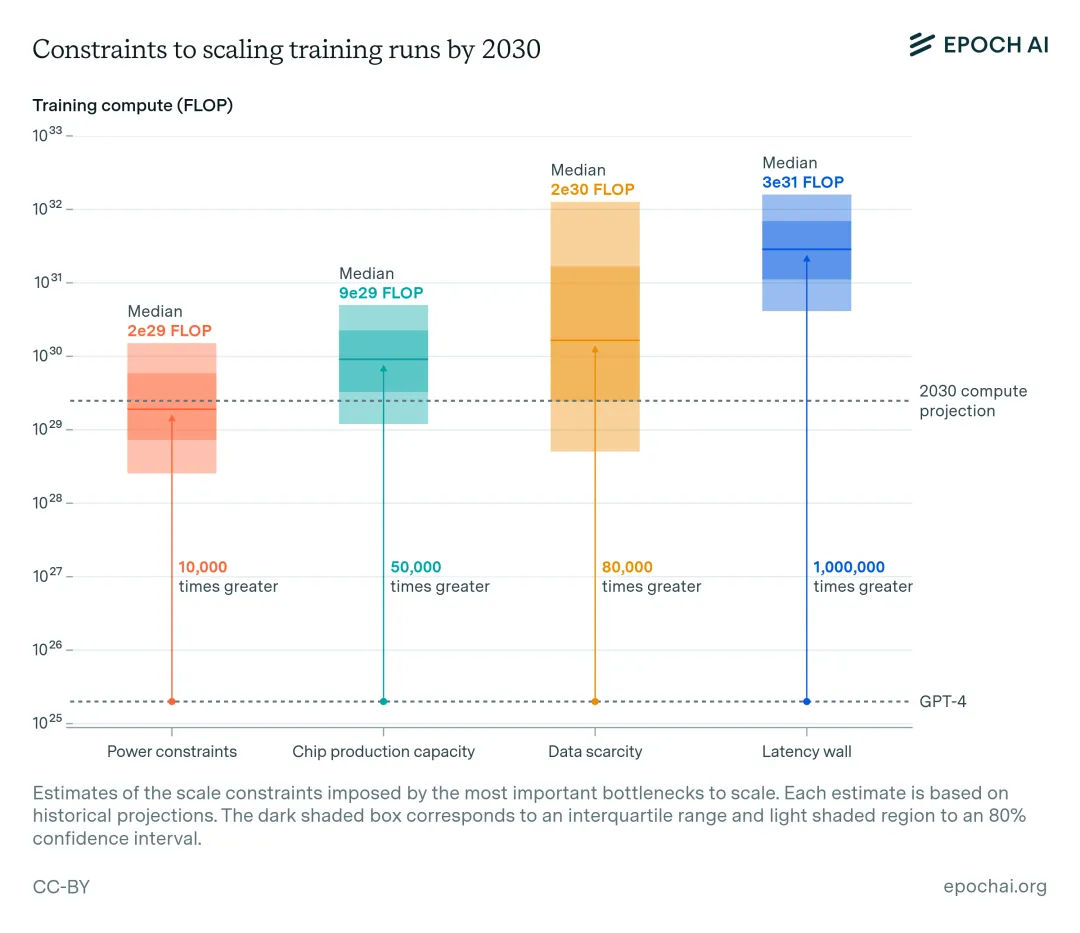
近年来,人工智能模型的能力显著提高。其中,计算资源的增长占了人工智能性能提升的很大一部分。规模化带来的持续且可预测的提升促使人工智能实验室积极扩大训练规模,训练计算以每年约 4 倍的速度增长。
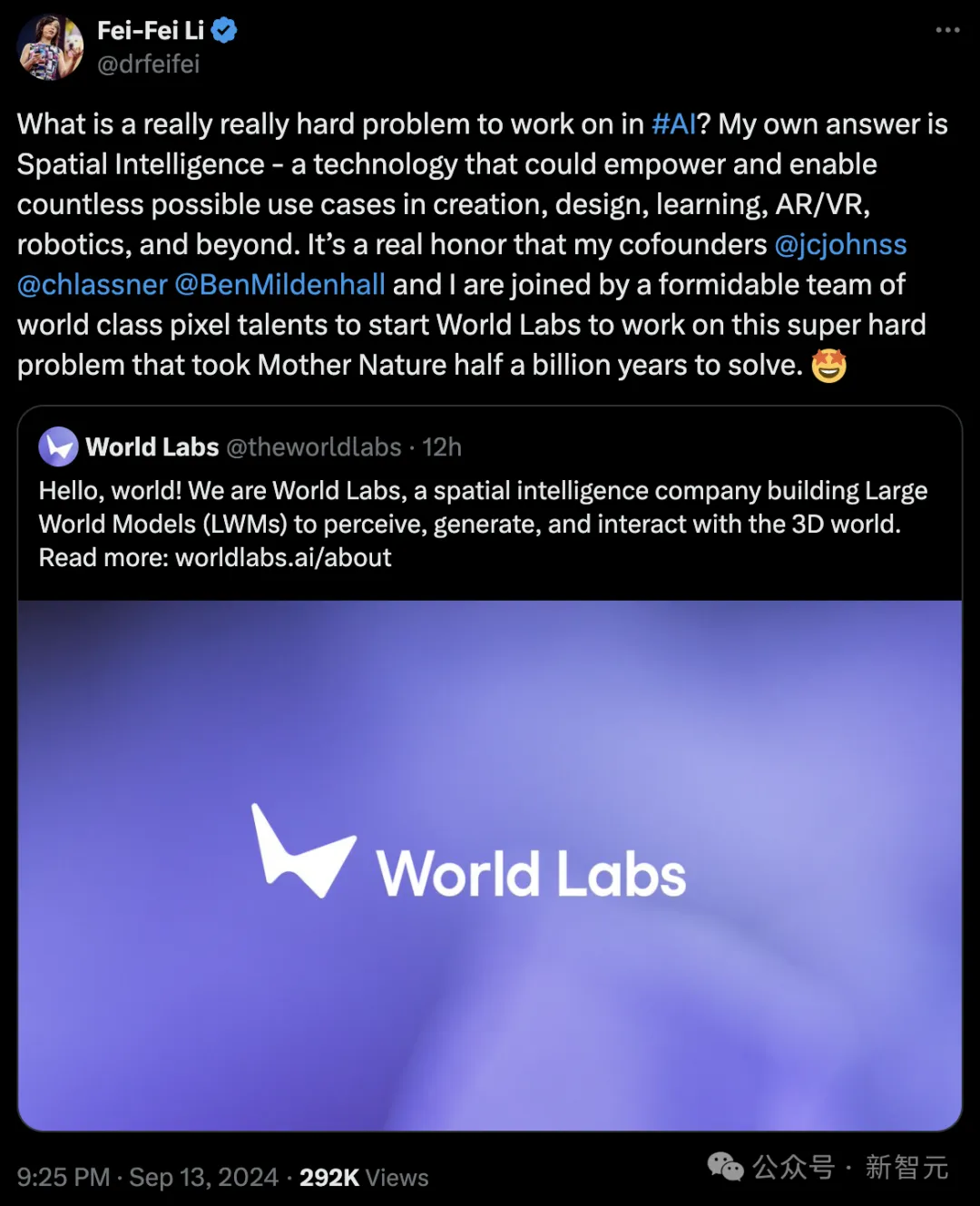
AI教母李飞飞的创业公司World Labs,正式官宣启动!
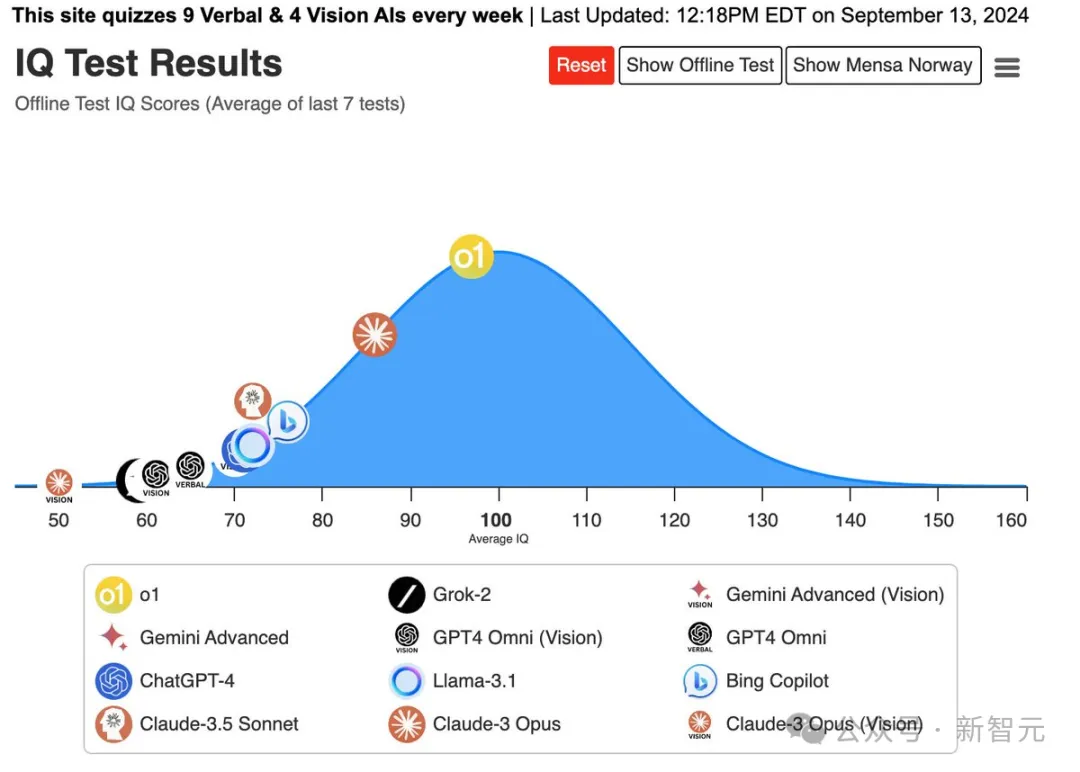
OpenAI o1,在IQ测试中拿到了第一名!大佬Maxim Lott,给o1、Claude-3 Opus、Gemini、GPT-4、Grok-2、Llama-3.1等进行了智商测试,结果表明,o1稳居第一名。

什么?大模型也许很快就能生成《黑神话·悟空》这种3A大作了?!直接看一则demo,《西游记》这就上桌
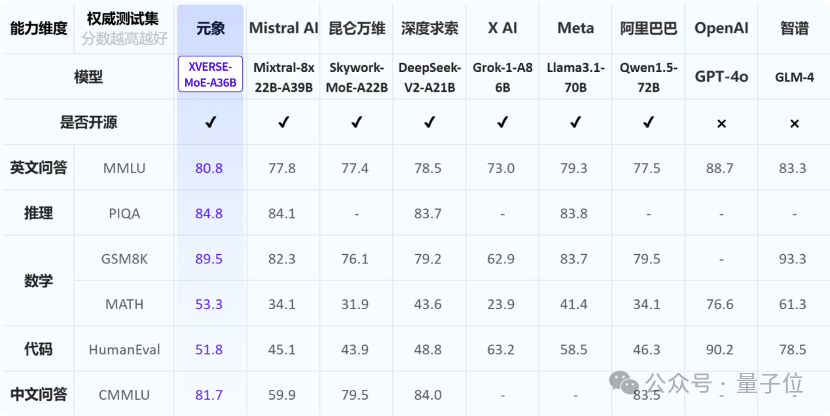
元象XVERSE发布中国最大MoE开源模型:XVERSE-MoE-A36B,该模型总参数255B,激活参数36B,达到100B模型性能的「跨级」跃升。