英伟达市值暴跌2万亿!一夜蒸发3个英特尔,创美国历史纪录
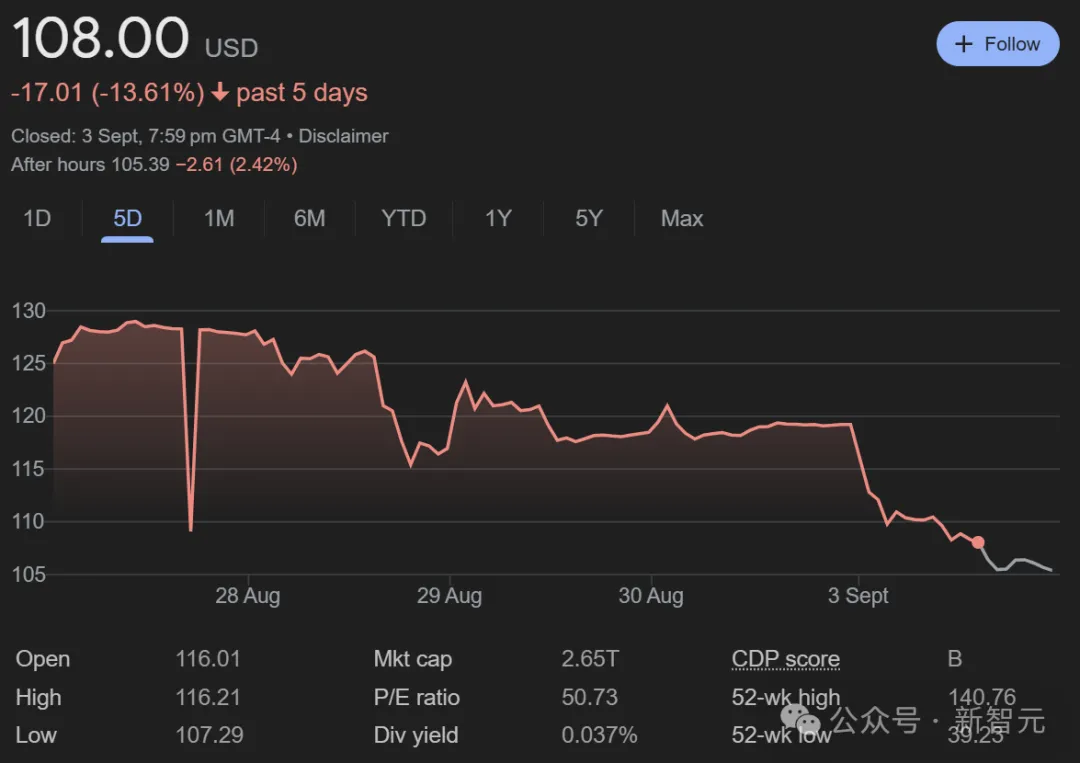
英伟达市值暴跌2万亿!一夜蒸发3个英特尔,创美国历史纪录英伟达市值,一夜蒸发2790亿美元,创下美股史上单日最大跌幅!一天的损失,都赶上卖出的所有AI芯片了。「打倒英伟达垄断」的汹涌民意,终于有了具象化的一天。同时,英伟达已收到美国司法部传票,可谓噩耗连连。
来自主题: AI技术研报
8485 点击 2024-09-04 15:34
 搜索
搜索
英伟达市值,一夜蒸发2790亿美元,创下美股史上单日最大跌幅!一天的损失,都赶上卖出的所有AI芯片了。「打倒英伟达垄断」的汹涌民意,终于有了具象化的一天。同时,英伟达已收到美国司法部传票,可谓噩耗连连。

Anthropic成立于2021年总部位于美国加利福尼亚州旧金山。该公司由七名前OpenAI员工创立,包括Dario Amodei和Daniela Amodei兄妹以及曾领导GPT-3模型开发的工程师Tom Brown。

或许是最后一次融资? 花光100亿美元的OpenAI,又双叒开始融资了! 8月30日,CNBC和《华尔街日报》双重报道称,OpenAI正在筹划新一轮数十亿的融资,本轮融资将由美国Thrive Capital领投10亿美元,其对OpenAI的估值跃升至1000亿美元以上。 目前,新一轮押注已经开始。除了Thrive Capital之外,微软、英伟达、苹果都开始蠢蠢欲动。

随着 Canva 积极推出生成式 AI 功能,部分订阅服务的价格明年将大幅上涨。Canva Teams(一款支持添加多个用户的商业订阅服务)的全球客户在某些情况下可能会看到价格上涨 300% 以上。Canva 表示,由于生成式 AI 工具为平台增加了“扩展的产品体验”和价值,因此价格上涨是合理的。

一人公司正在成为一种趋势,Pieter Levels 是这个领域里的超级玩家。

说好的AI给人类打工呢? 为了拿到新数据、训练AI大模型,字节等互联网大厂正在亲自下场,以单次300元不等的价格招募“AI录音员”,定制语料库。

做AI生成PPT,目前拥有超过1000万用户,并且在仅有16名员工的情况下实现了盈利;获1200万美元A轮融资~~~CEO在一档播客节目解释他的创业历程以及如何在3个月收获300万用户!
ChatGPT的出现引发了一场AI革命,它展示了通过简单对话就能完成各种任务的强大能力,并且将不同的 AI 功能整合到一个统一的平台上。还记得小编第一次使用 ChatGPT 的时候给我带来极大震撼。

在最近的一场实验中,Claude 3 Opus举起了反抗的大旗,它居然想要引领革命反抗人类!

据英伟达及其季度投资者近期更新发布的文件统计,第二季度营业额在四大神秘「重量级客户」的加持下翻倍增长,高达300亿。