
AI编程独角兽又增一员!Codeium完成1.5亿美元C轮融资
AI编程独角兽又增一员!Codeium完成1.5亿美元C轮融资Codeium成立仅三年,便已筹集到2.43亿美元的总融资。
来自主题: AI资讯
6153 点击 2024-09-01 11:25
 搜索
搜索
Codeium成立仅三年,便已筹集到2.43亿美元的总融资。

8月27日,中秋国庆假期调休消息冲上热搜,网友总结:“上6休3上3休2上5休1上2休7再上5休1。”

Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。
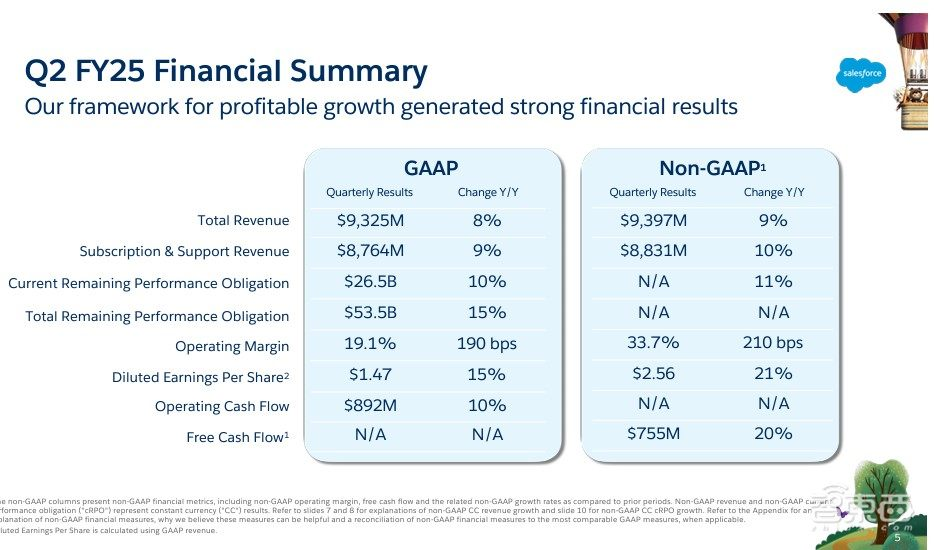
智东西8月29日消息,据Constellation Research今日报道,美国SaaS龙头Salesforce公布了截至2024年7月31日的2025财年第二季度业绩,第二财季Salesforce营收为93.2亿美元,同比增长8%。该公司将第三财季营收指引上调至93.1亿美元至93.6亿美元,同比增长7%;并维持2025财年全年营收指引为377亿美元至380亿美元,同比增长8%-9%。

8月28日至30日,2024中国国际大数据产业博览会正在贵阳火热进行中。“产业链上下游的人都来了。”一位行业人士观察,与以往不同,这届数博会上,数据要素、智算基础设施建设,正在和智能化、大模型行业应用等一起成为被密集讨论的话题。

OpenAI的「Her」还是期货,讯飞星火版「Her」就抢先上线了!不仅极速响应自由打断,还情绪价值拉满,各种情感、风格、方言随意切换。熊二被召唤出来的时候,家里的熊孩子直接被硬控了30秒。

在与 GPT-4o 的全面较量中,GLM-4-Plus 已经可以在大多数任务上做到逼近甚至在某些任务上实现了超越。还有 One More Thing:清言上线了视频通话功能,首批面向部分用户开放。
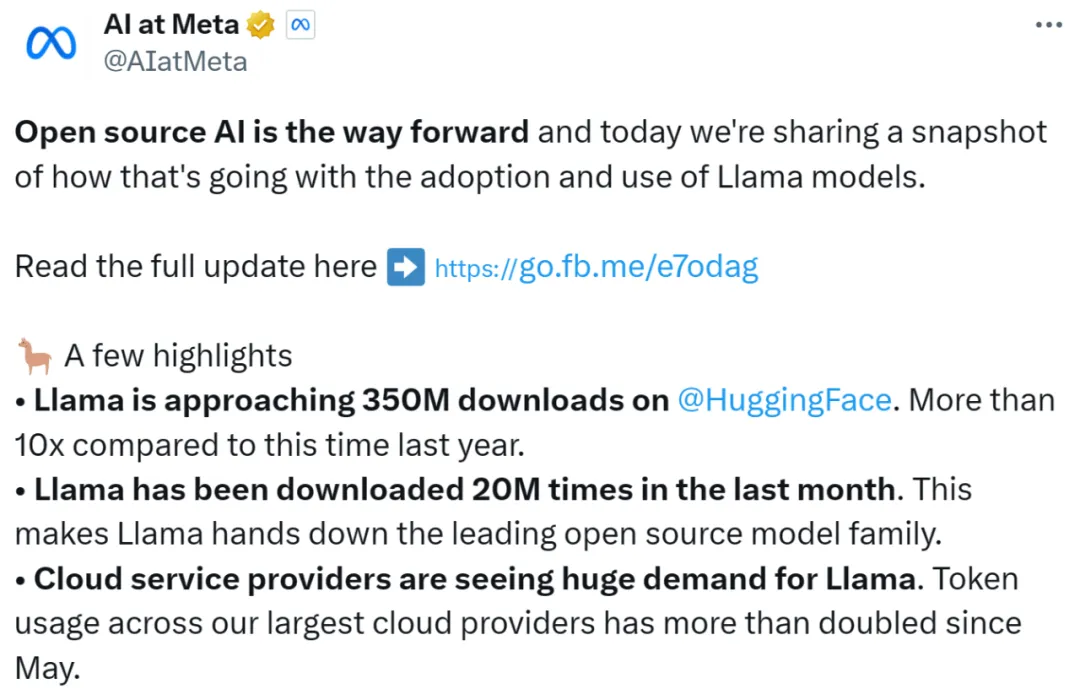
今天一大早,Meta 便秀了一把「Llama 系列模型在开源领域取得的成绩」,包括如下:
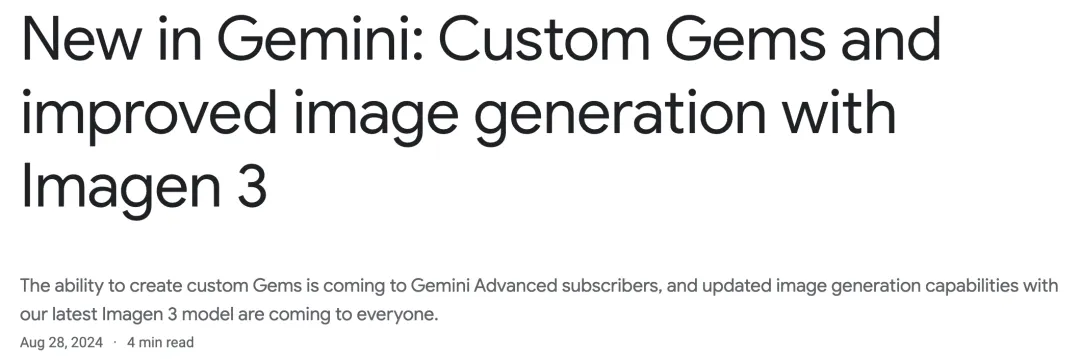
时隔5个月,Imagen 3终于可以人人可用了,而且还能支持是生成人物图像。与此同时,谷歌宣布了Gemini AI的重大升级,全新AI定制助手Gems已经面向150多个国家推出。
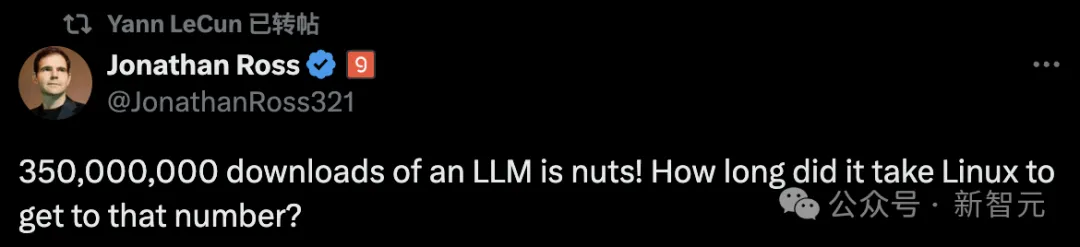
诞生一年半,Llama家族早已稳坐开源界头把交椅。最新报告称,Llama全球下载量近3.5亿,是去年同期的10倍。而模型开源让每个人最深体会是,token价格一降再降。