
盘点科技大厂今年的AI投入,千亿投资背后谁是赢家?
盘点科技大厂今年的AI投入,千亿投资背后谁是赢家?2022年ChatGPT横空出世后,2023-2024年间,科技大厂们开始在人工智能领域投入巨额资金
来自主题: AI资讯
9114 点击 2024-08-26 11:05
 搜索
搜索
2022年ChatGPT横空出世后,2023-2024年间,科技大厂们开始在人工智能领域投入巨额资金

随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。

让AI绘画模型变“乖”,现在仅需3秒调整模型参数。

在 ECCV 2024 中,来自南洋理工大学 S-Lab、上海 AI Lab 以及北京大学的研究者提出了一种原生 3D LDM 生成框架。
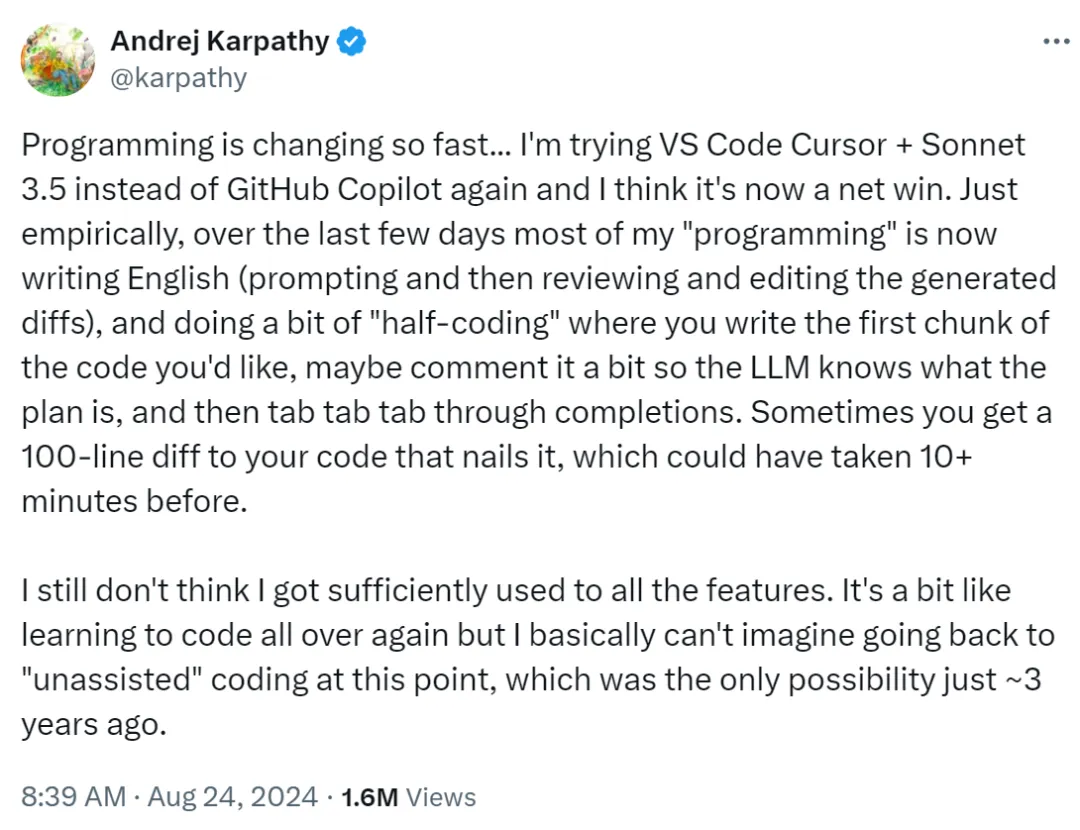
热衷于开课并与网友分享新技术使用心得的 AI 大牛 Karpathy,也有被质疑「为推销某个产品而在言论中夹带私货」的一天。

AI大佬陈天桥,联手Science官宣设立AI驱动科学大奖!评奖征集内容为1000字左右的论文,大奖和优胜者会分获3万美元和1万美元的奖励,截止时间为2024年12月13日。
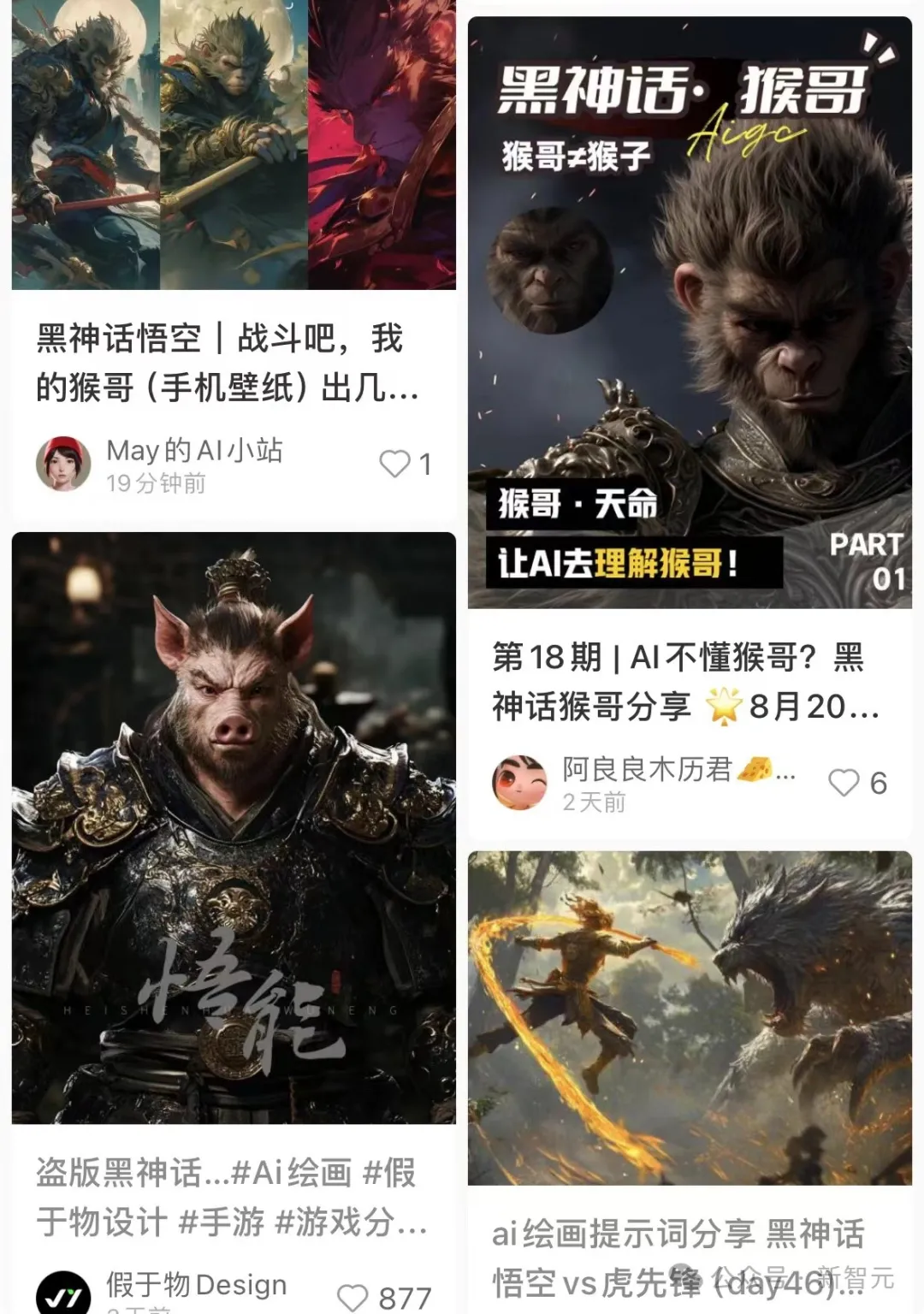
国产3A顶流《黑神话·悟空》,与AI联动起来了!网友纷纷开启二创,有人用AI续写神话,有人把自家二哈变成了精怪,甚至还有人自制了桌面壁纸!

Noam Shazeer 2021 年离职谷歌,3 年后又以特殊方式重回谷歌。

人自信的时候,说话都会变得坦率很多。
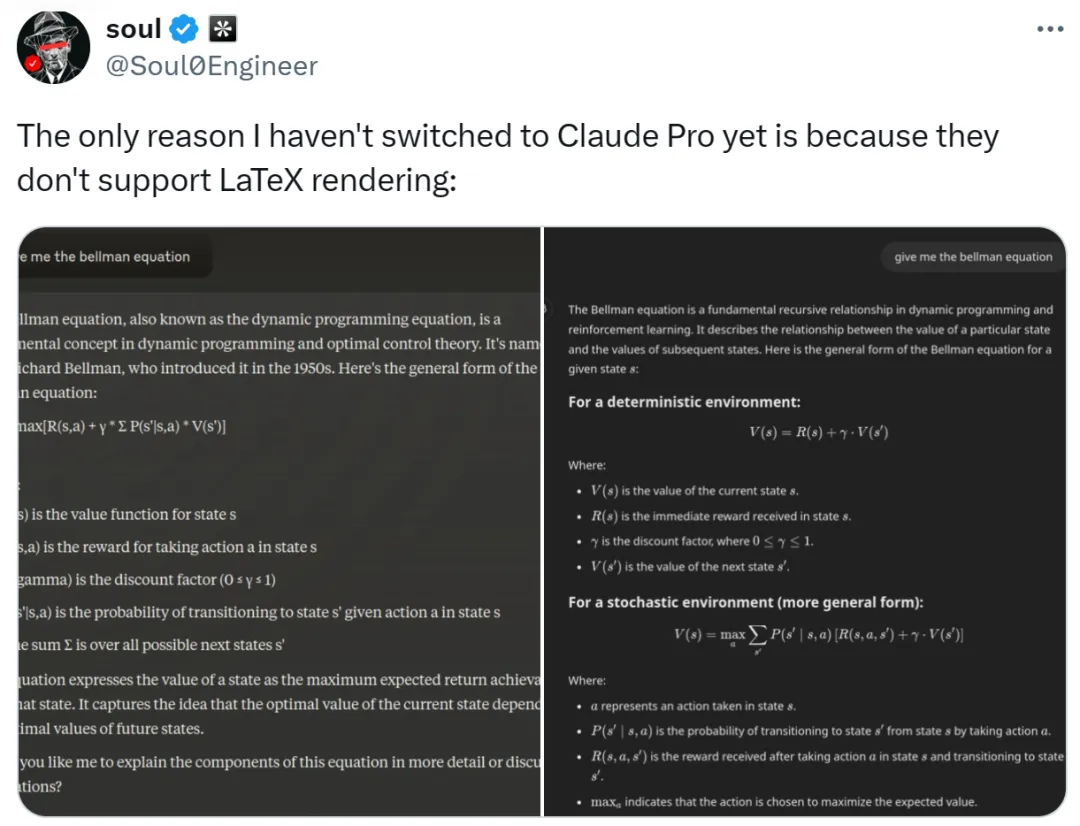
当 ChatGPT 老早就支持使用 LaTeX 语言输入和显示数学公式时,Claude 现在终于补上了这一功能。